Download as PDF, PPTX


























![ELASTIC SEARCH POWER
index over 95GB/h/node
8-node cluster: sub-200ms response for complex searches on 10B+ records
(oracle OR mysql) AND replication
apple AND ip*d
john AND city:Dublin
species:"Sea Bream" AND execution.date:[20130701 TO 20130730]
taxicub AND ("Dublin"^2 OR "Cork")
"facets" : {
"locations" : { "terms" : {"field" : "city"} }
}
"terms" : [ {
"term" : "Dublin",
"count" : 130
}, {
"term" : "Cork",
"count" : 20
}, {
"term" : "Galway",
"count" : 1
} ]](https://image.slidesharecdn.com/delivering-a-big-data-ready-minimum-viable-product-140225093338-phpapp02/85/Delivering-a-Big-Data-Ready-minimum-viable-product-27-320.jpg)

![HISTOGRAMS / GEO DISTANCE
"facets" : {
"Feed_Histogram" : {
"date_histogram" : {
"key_field" : "date",
"value_field" : "execution.quantity_fed",
"interval" : "month"
}
}
}
"filter" : {
"geo_distance_range" : {
"from" : "200km",
"to" : "400km"
"pin.location" : {
"lat" : 40,
"lon" : -70
}
}
}
"filter" : {
"geo_distance" : {
"distance" : "200km",
"pin.location" : {
"lat" : 40,
"lon" : -70
}
}
}
"filter" : {
"geo_polygon" : {
"person.location" : {
"points" : [
{"lat" : 40, "lon" : -70},
{"lat" : 30, "lon" : -80},
{"lat" : 20, "lon" : -90}
]
}
}
}](https://image.slidesharecdn.com/delivering-a-big-data-ready-minimum-viable-product-140225093338-phpapp02/85/Delivering-a-Big-Data-Ready-minimum-viable-product-29-320.jpg)




![EASY GRAPH TRAVERSAL WITH GREMLIN
// calculate basic collaborative filtering for user 'Gregory'
m = [:]
g.v('name','Gregory').out('likes').in('likes').out('likes').groupCount(m)
m.sort{-it.value}](https://image.slidesharecdn.com/delivering-a-big-data-ready-minimum-viable-product-140225093338-phpapp02/85/Delivering-a-Big-Data-Ready-minimum-viable-product-34-320.jpg)
















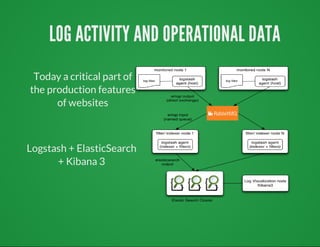




The document details the concepts and considerations for developing a big data-ready minimum viable product (MVP), highlighting the importance of choosing an appropriate data architecture and storage solutions. It discusses various data models, emphasizes polyglot persistence, and outlines key features of big data architecture, including distributed computing and real-time processing. Additionally, it provides insights into best practices for data storage selection, data modeling, and the application of RESTful APIs in service-oriented architectures.















































