



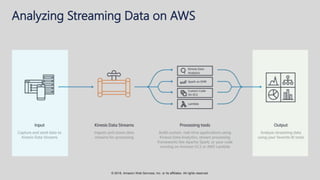

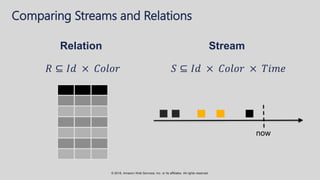
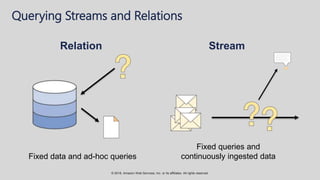





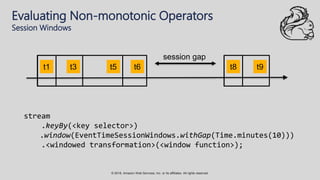
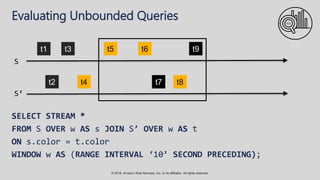

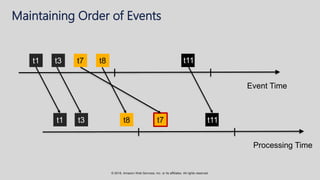
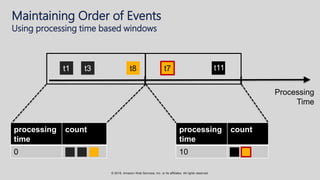

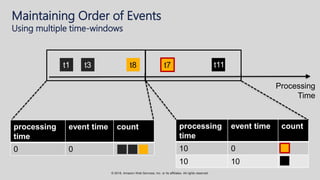
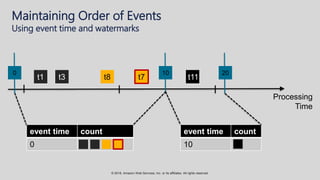



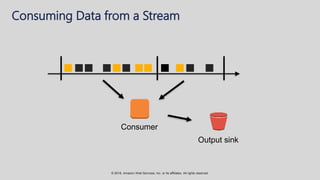
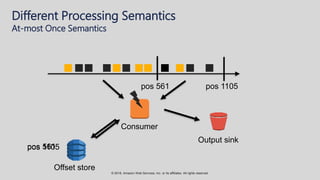
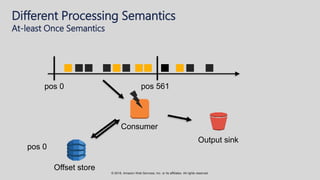

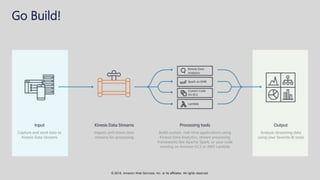



The document provides an overview of techniques and tools for analyzing streaming data using Amazon Web Services (AWS), focusing on stream processing challenges and solutions. It discusses the capabilities of Amazon Kinesis Analytics and Apache Flink for handling real-time data, as well as various windowing strategies for querying streams. Additionally, it highlights different event processing semantics and the importance of maintaining event order within data streams.
















![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)























































