Download to read offline

![Introduction: Pfarrerbuch
content editor
(Project Team)
[protected zone]
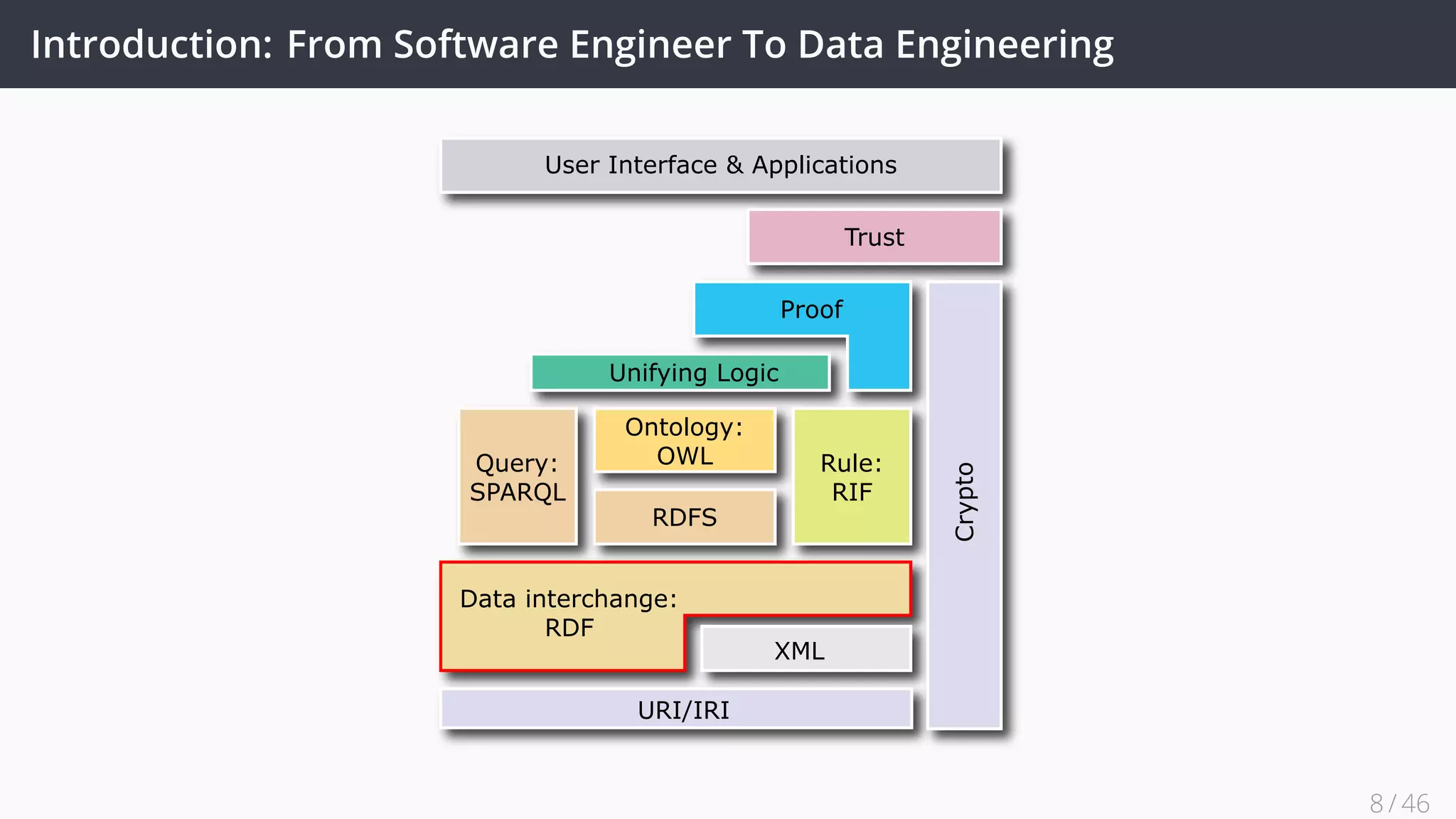
SPARQL
Endpoint
HTML GUI
[stable]
OntoWiki
Persistency Layer
Backup Model
query, search
add, edit, maintain
3 / 45](https://image.slidesharecdn.com/natanael-arndt-170607114252/75/Decentralized-Evolution-and-Consolidation-of-RDF-Graphs-5-2048.jpg)
![Introduction: Catalogus Professorum Lipsiensium
synchronize
Model Data (SPARUL)
Linked Data
Linked Data
Partial RDF export
Full RDF export
Backup Model
experienced
web user
content editor
(Project Team)
general
web user
SPARQL
Endpoint
HTML GUI
[stable]
OntoWiki
Persistency Layer
SPARQL
Endpoint
HTML GUI
[experimental]
OntoWiki
Persistency Layer
HTML GUI
[stable]
CPL Frontend
Persistency Layer
OCPY
TOWEL
configure
configure
query, search
add, edit, maintain
getData
query, search
browse, annotate, discuss
synchronize
Model Data
synchronize
Model Data
browse, search
[protected zone]
[public zone]
4 / 45](https://image.slidesharecdn.com/natanael-arndt-170607114252/75/Decentralized-Evolution-and-Consolidation-of-RDF-Graphs-6-2048.jpg)




![Related Work/State of the Art
Approach storage quad
support
bnodes branches merge push/pull
TailR [4] hybrid noa yes nof no (yes)h
Eccrev [2] delta yes yes nof no no
R43ples [3] delta nob,c (yes)d yes no no
R&W base [5] delta noc (yes)e yes (yes)g no
dat chunks n/a n/a no no yes
a
The granularity of versioning are repositories; b
Only single graphs are put under version control;
c
The context is used to encode revisions; d
Blank nodes are skolemized; e
Blank nodes are
addressed by internal identifiers; f
Only linear change tracking is supported; g
Naive merge
implementation; h
No pull requests but history replication via memento API
9 / 45](https://image.slidesharecdn.com/natanael-arndt-170607114252/75/Decentralized-Evolution-and-Consolidation-of-RDF-Graphs-12-2048.jpg)

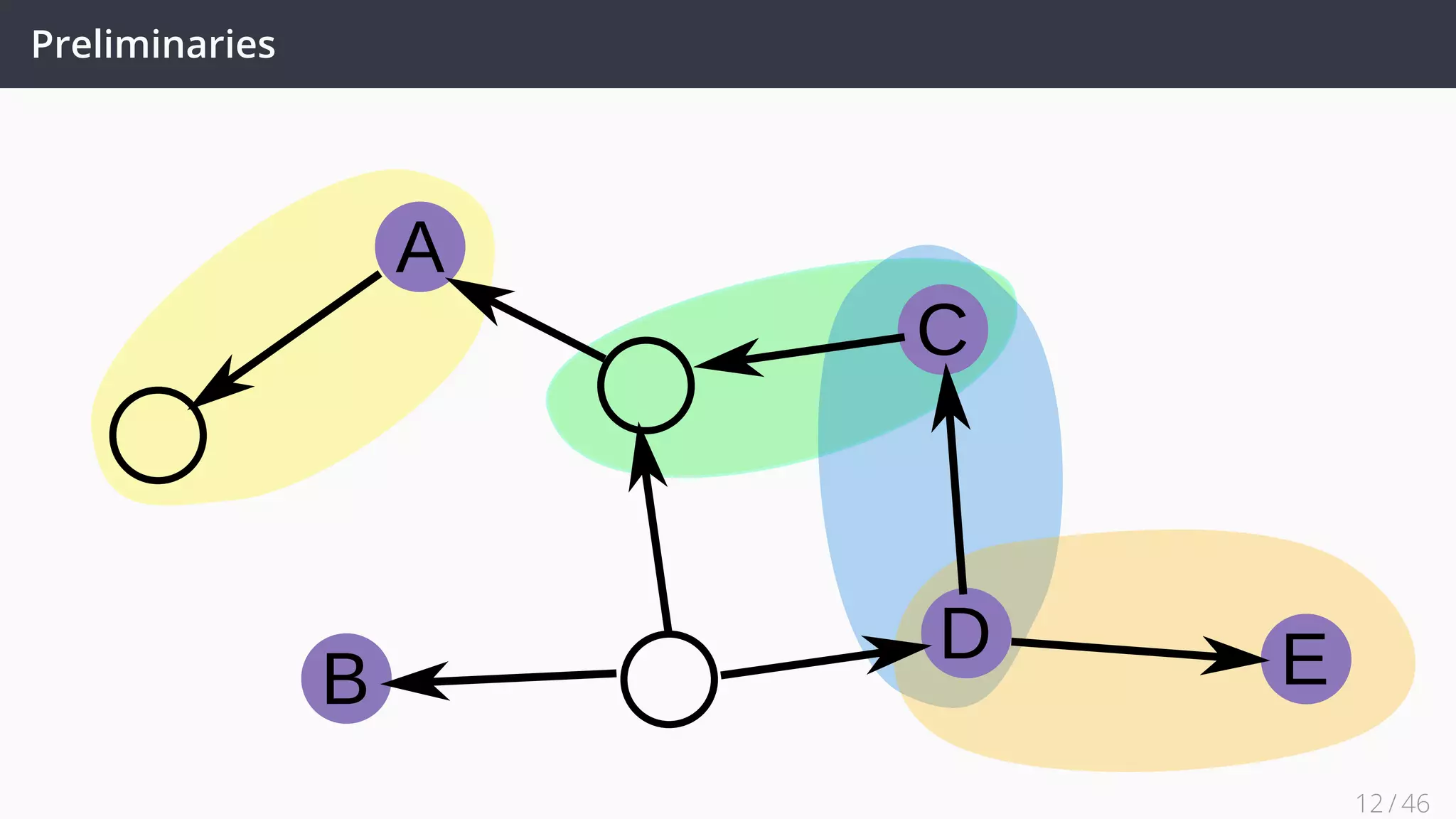
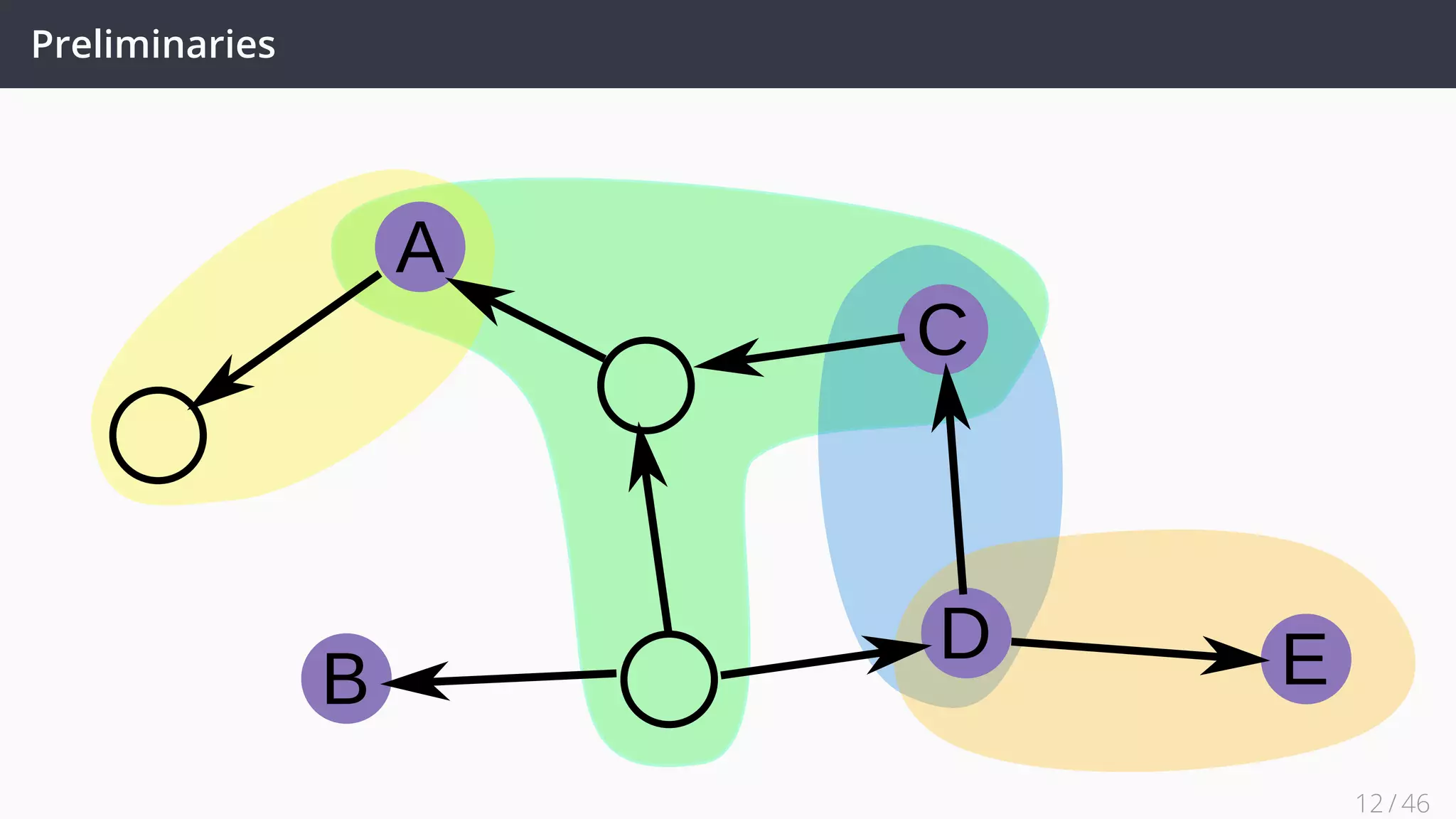
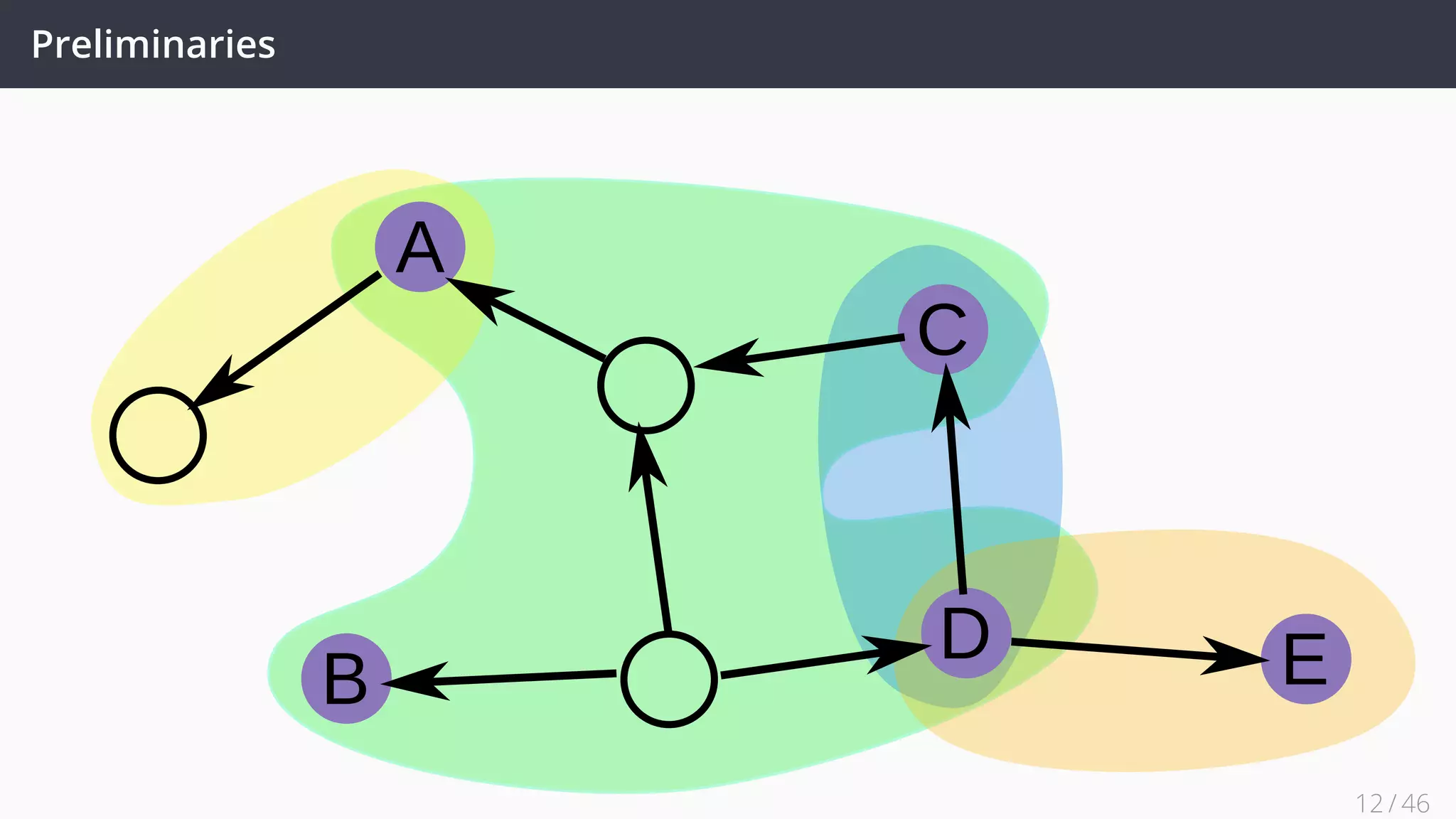
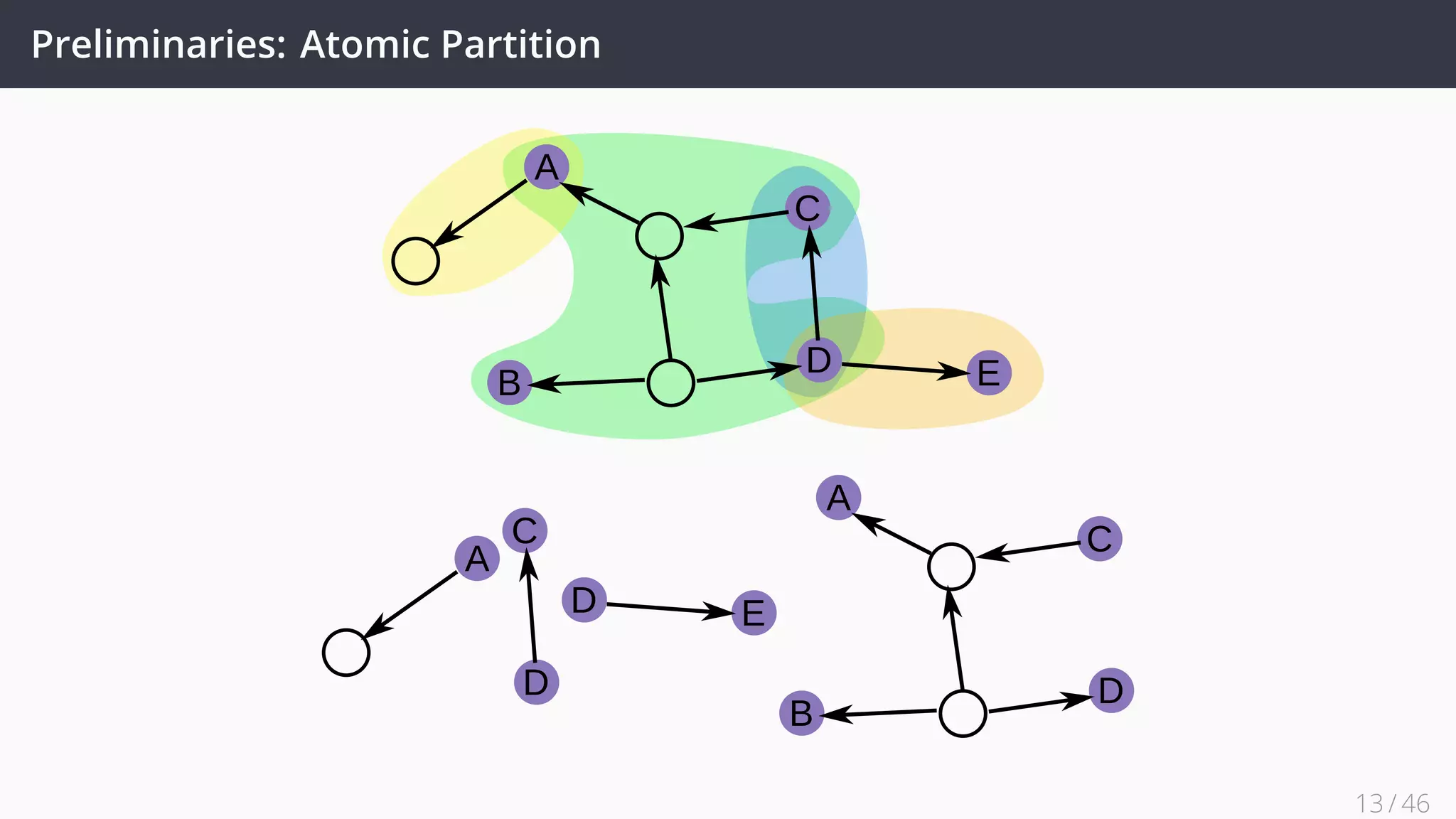
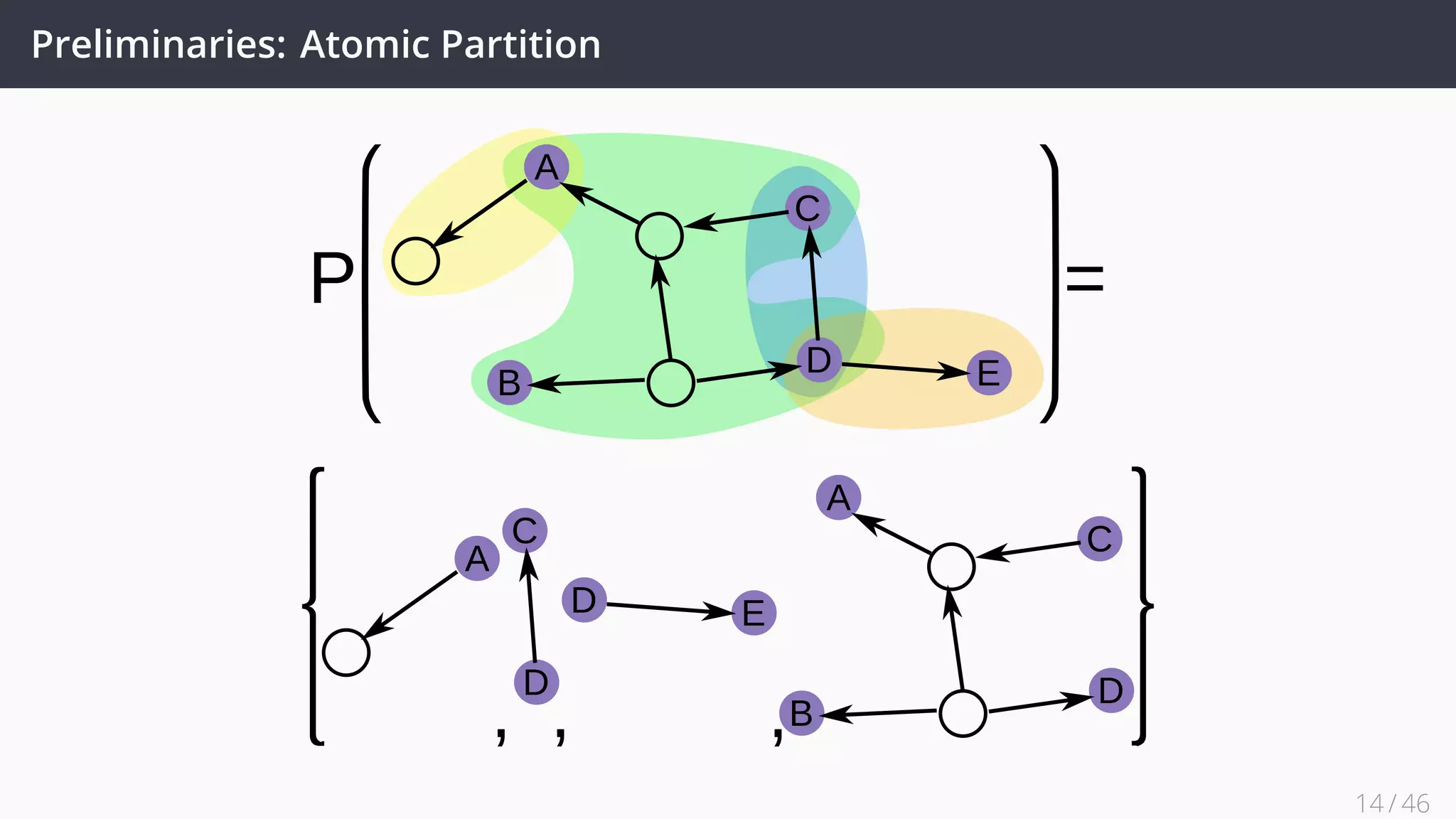
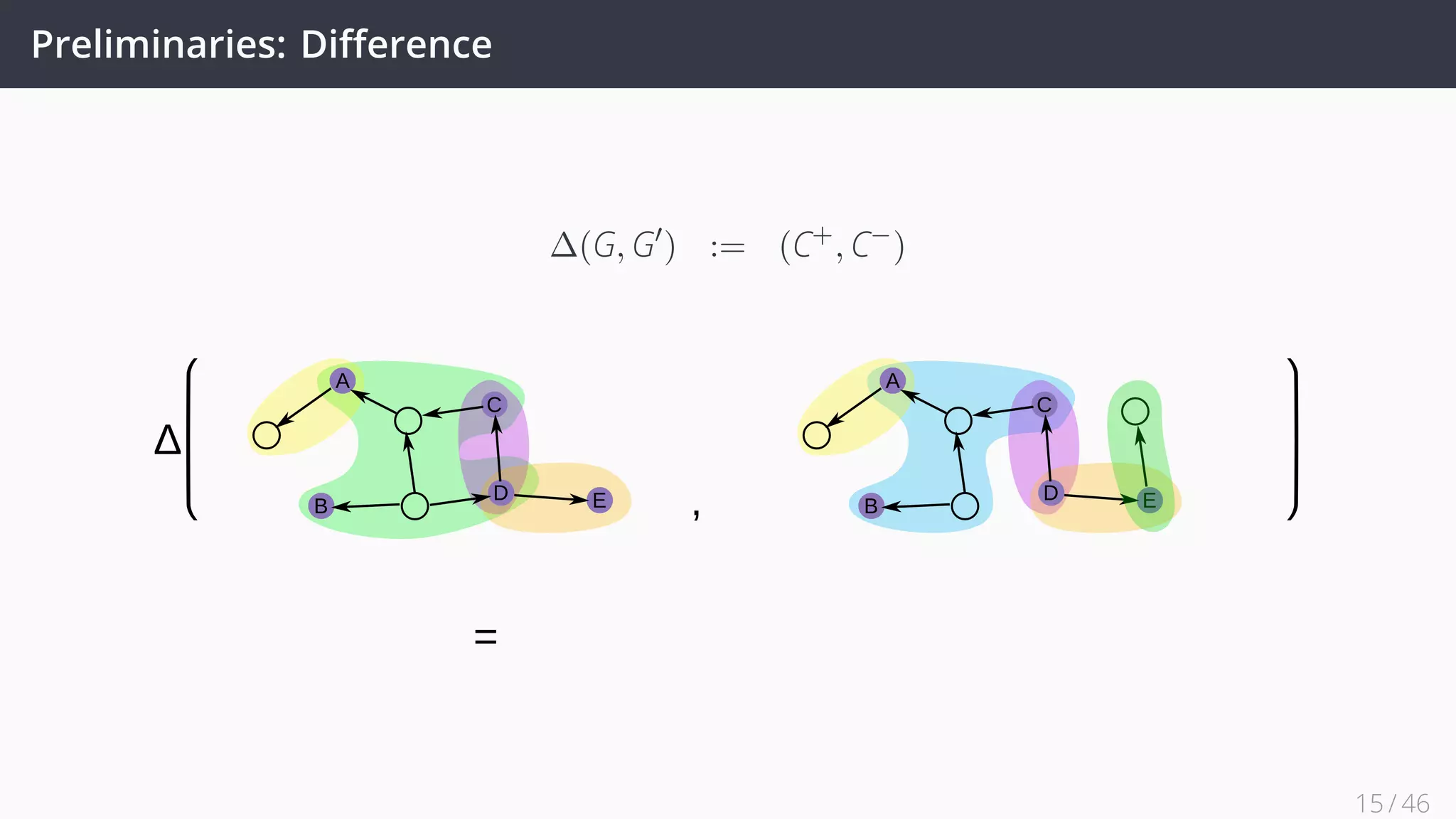
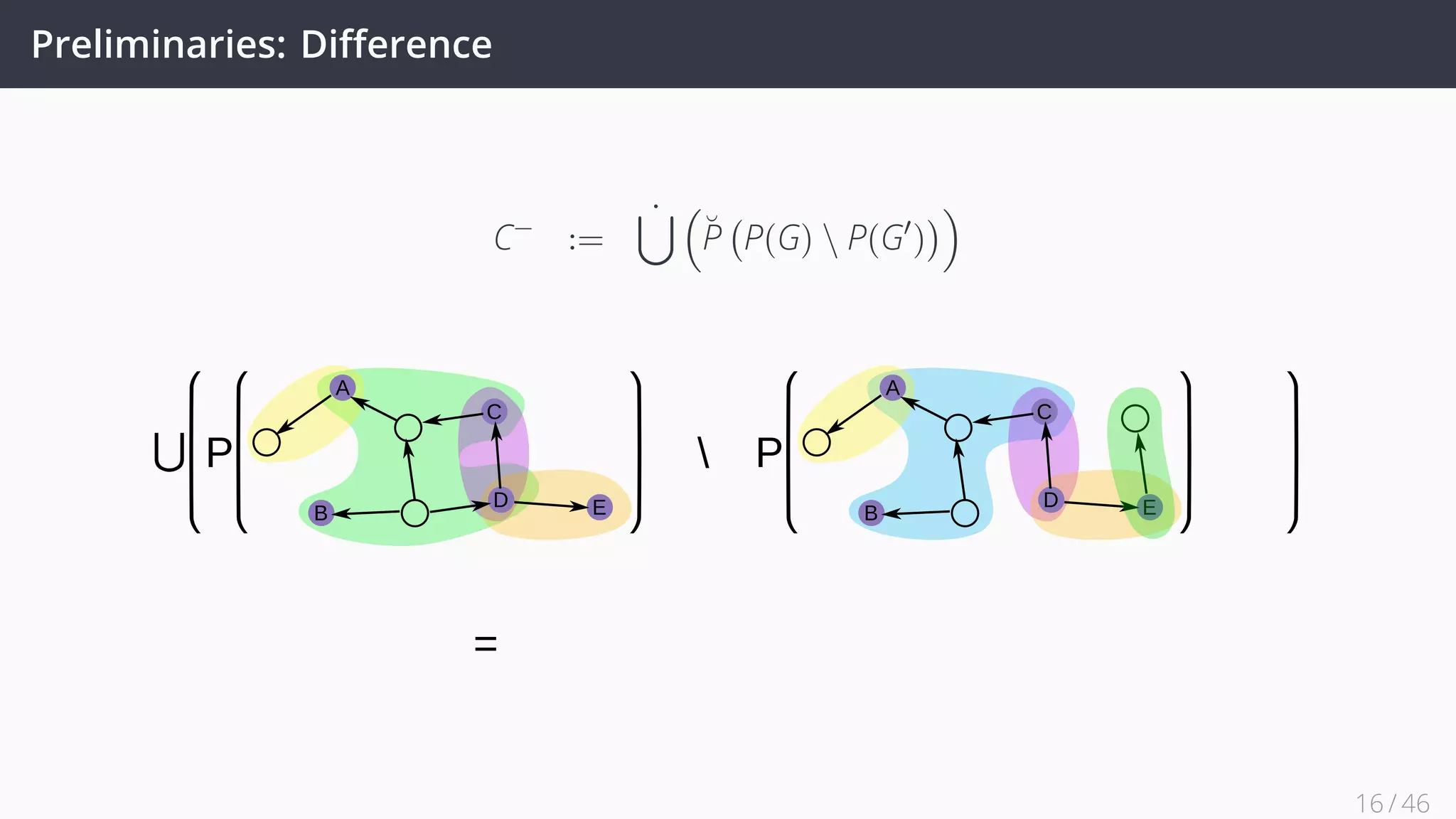
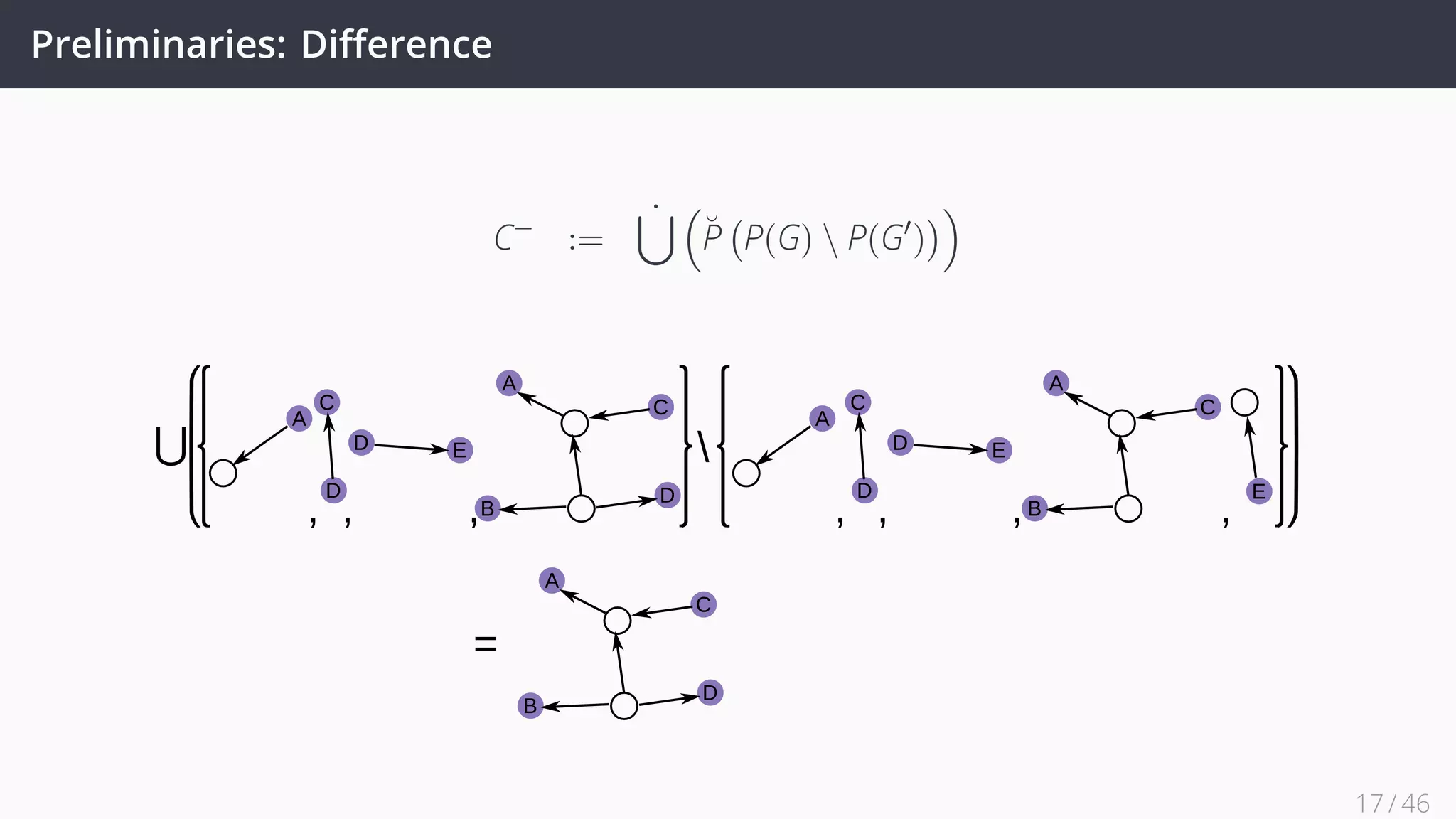
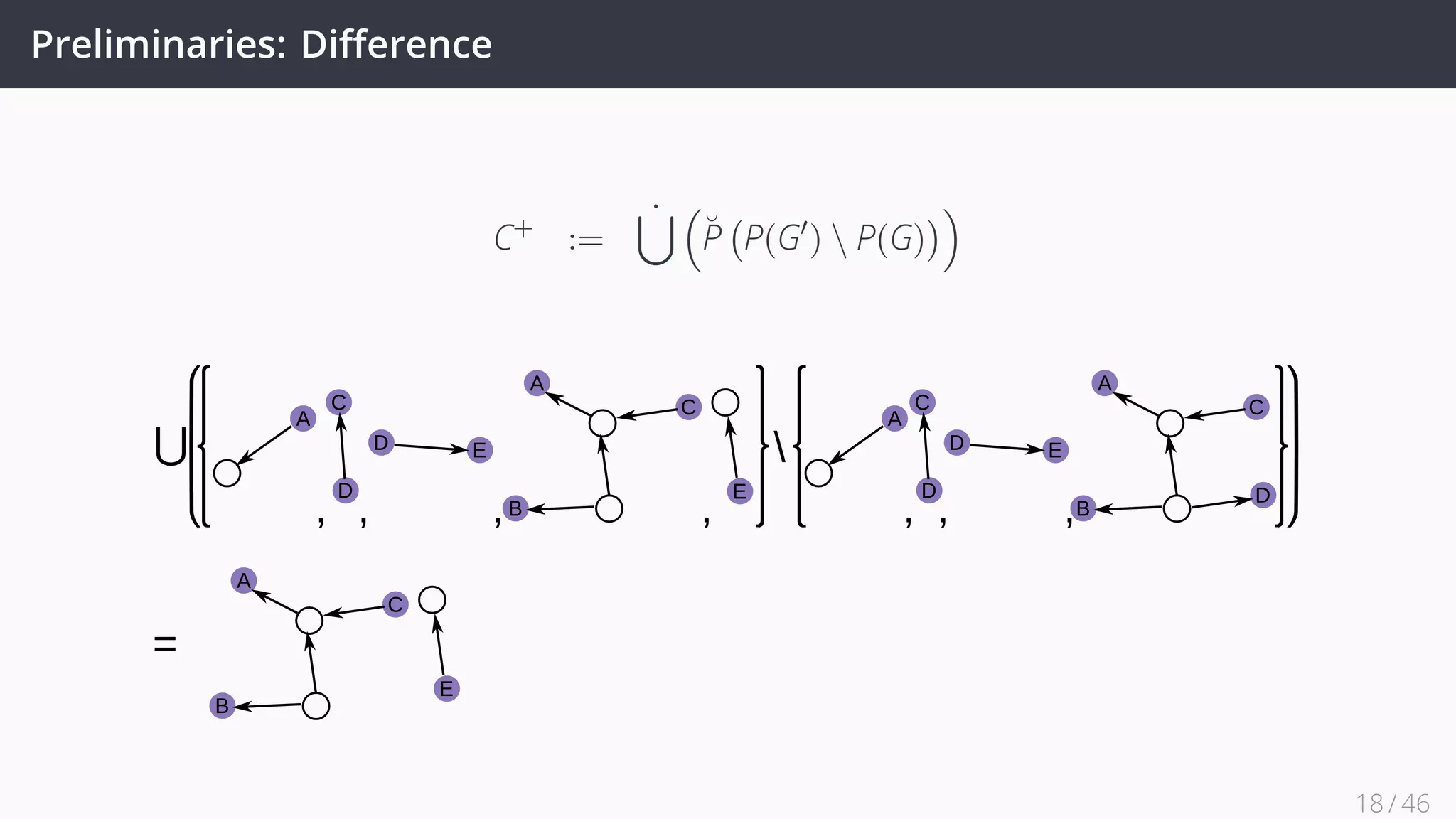

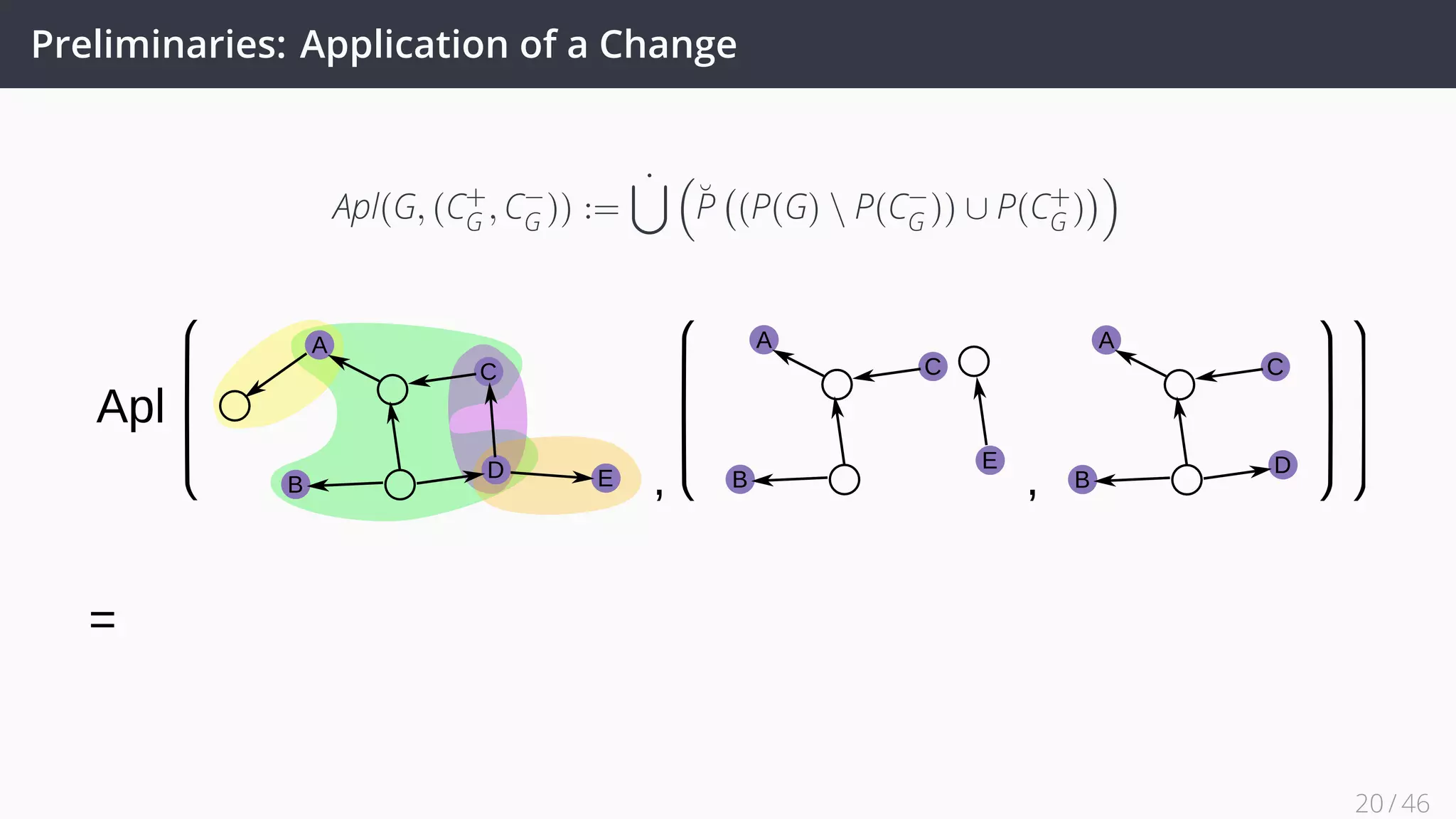
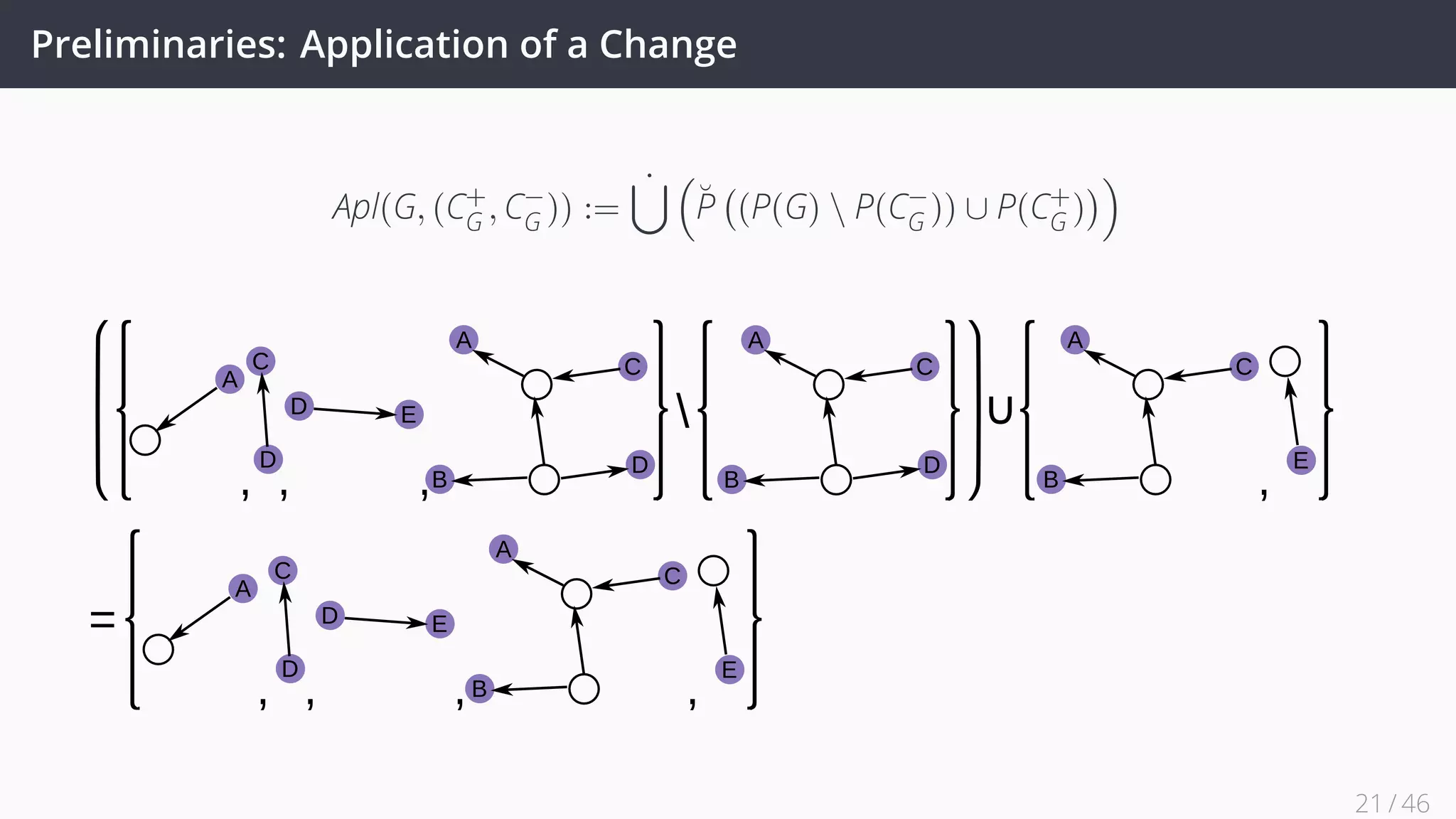
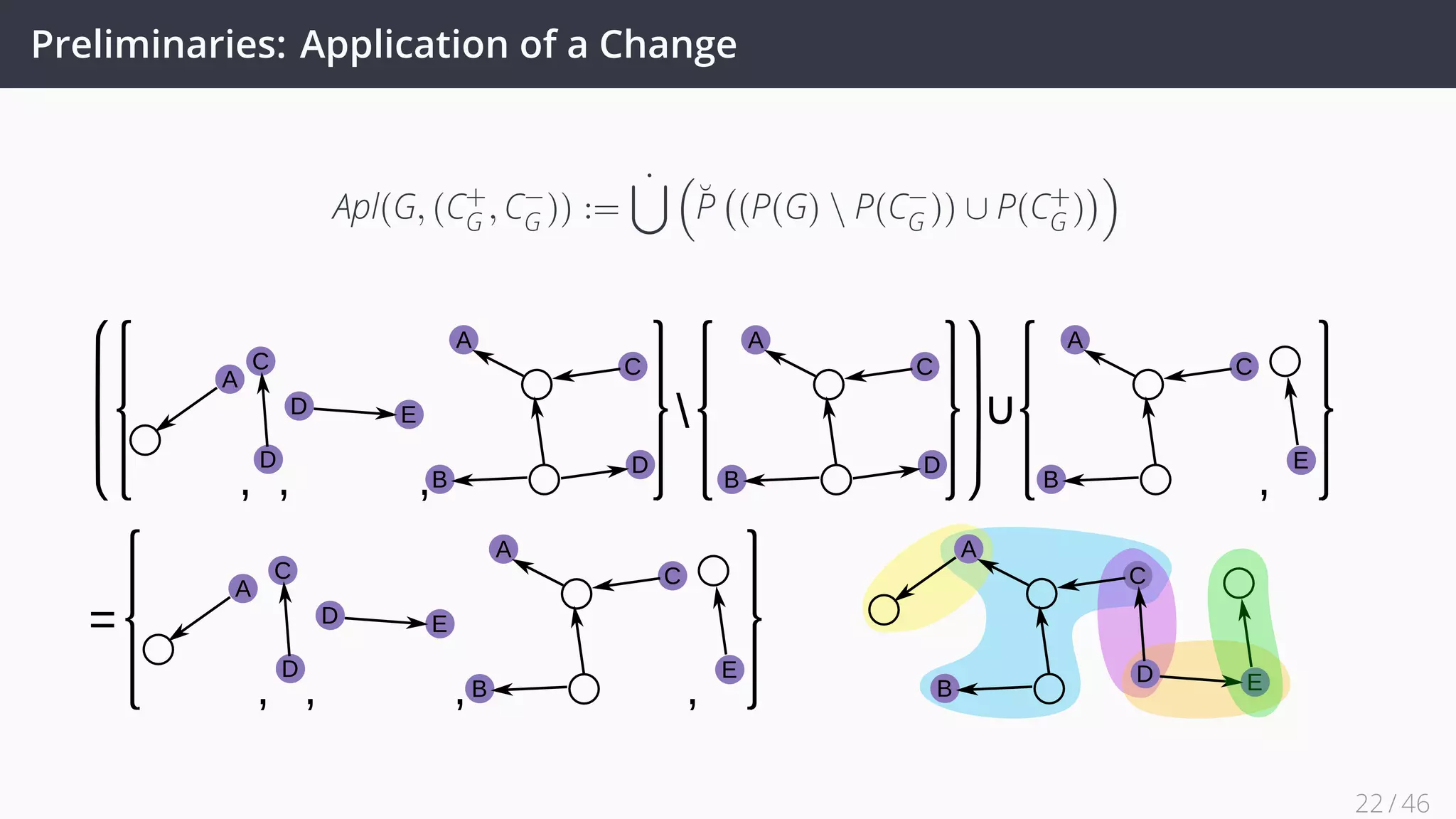









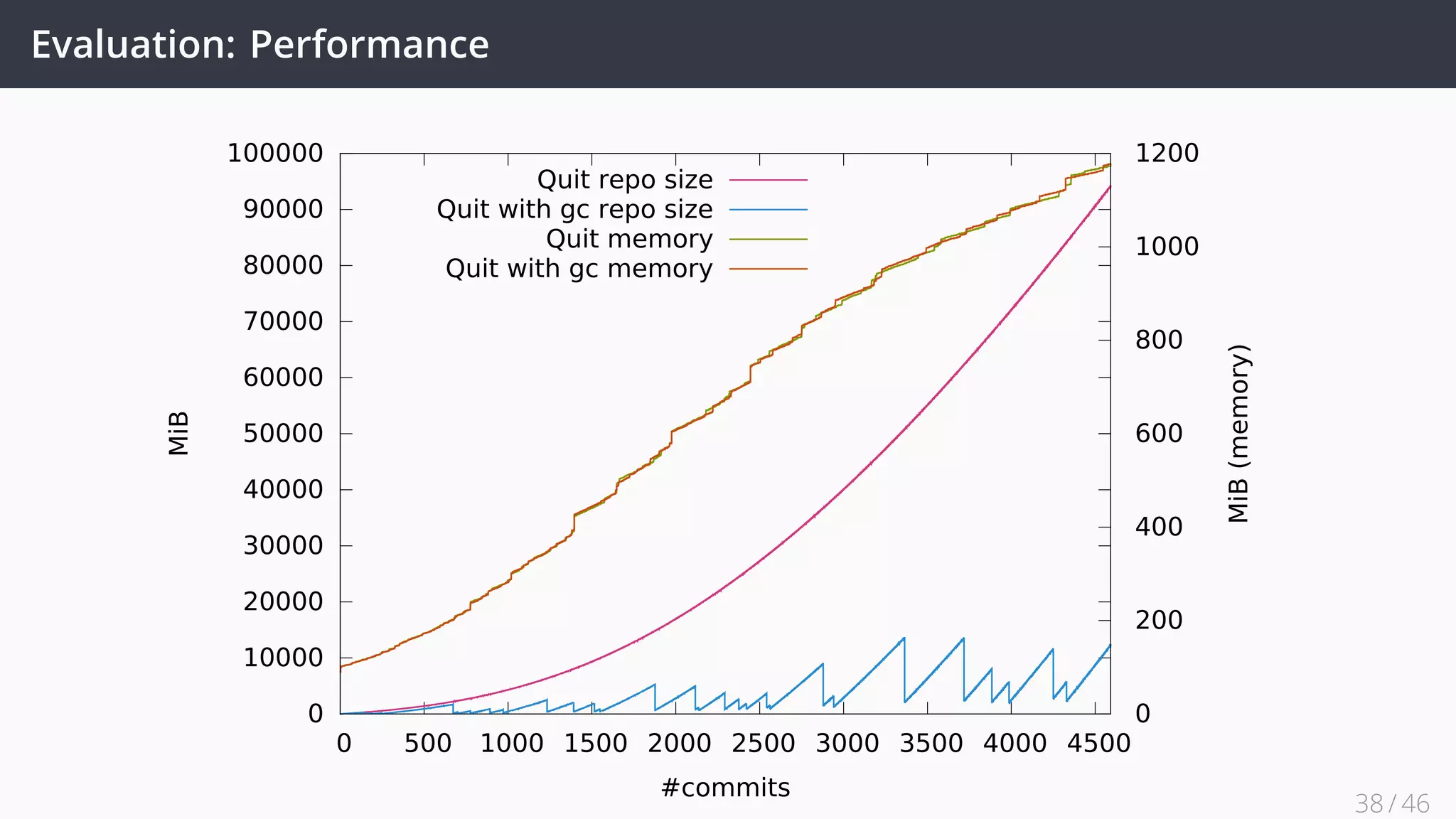
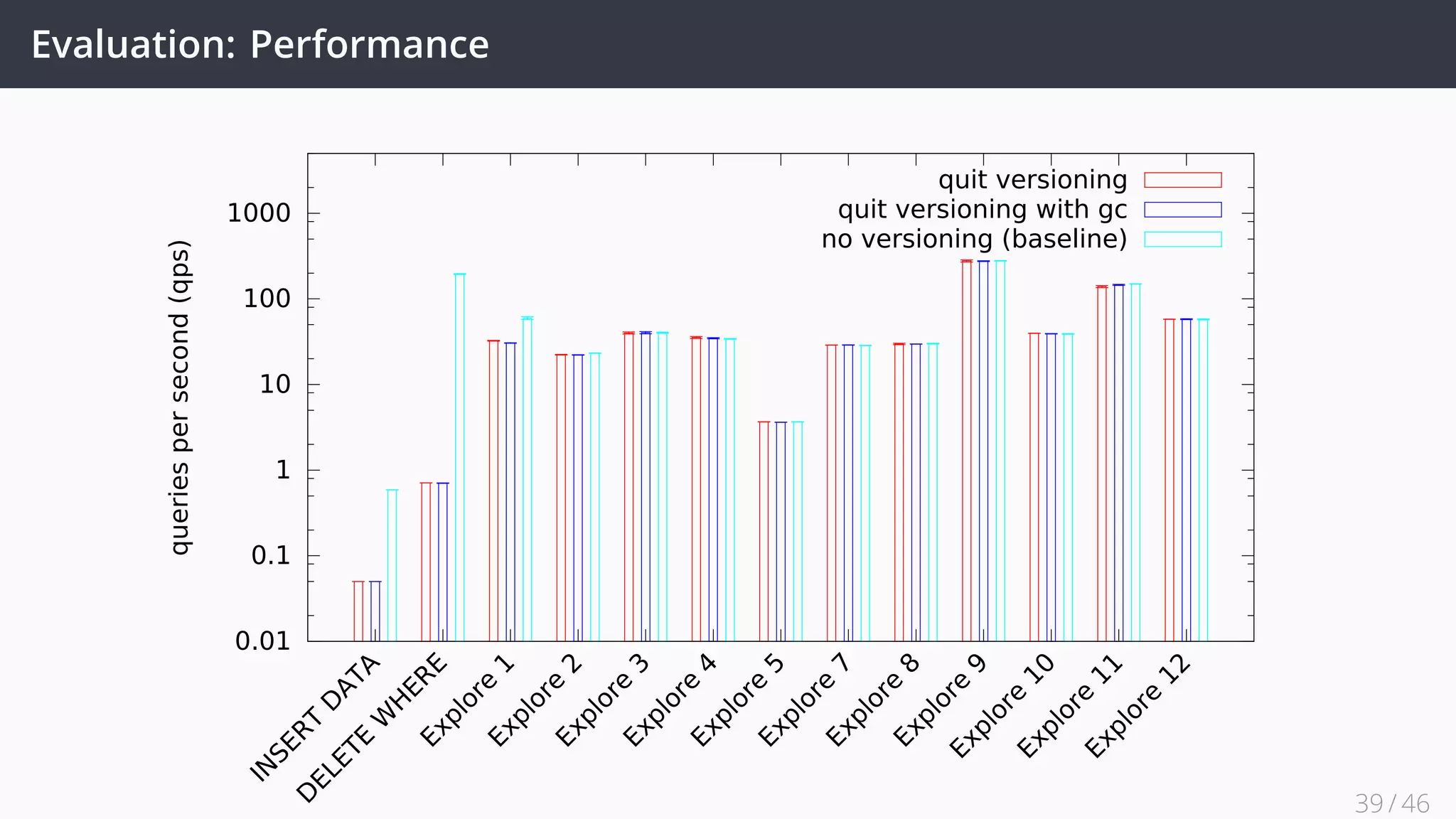



![Future Work
• Improve our Quit Store implementation to support the complete framework
• Explore provenance tracked by Git through an RDF interface ✓ [1]
• Implement the Quit architecture for real world problems
41 / 45](https://image.slidesharecdn.com/natanael-arndt-170607114252/75/Decentralized-Evolution-and-Consolidation-of-RDF-Graphs-57-2048.jpg)
![Future Work
experienced
web user
general
web user
content editor
(Project Team)
[protected zone]
SPARQL
Endpoint
HTML GUI
[stable]
OntoWiki
Persistency Layer
query, search
add, edit, maintain
clone/fetch/push
public + private
Data
Data
Transformation
Tasks (ETL)
add new Data
Legacy Data Sources
[public zone]
any RDF
Editor
Commenting
Interface
Browsing
Interfacequery, search
comment
42 / 45](https://image.slidesharecdn.com/natanael-arndt-170607114252/75/Decentralized-Evolution-and-Consolidation-of-RDF-Graphs-58-2048.jpg)



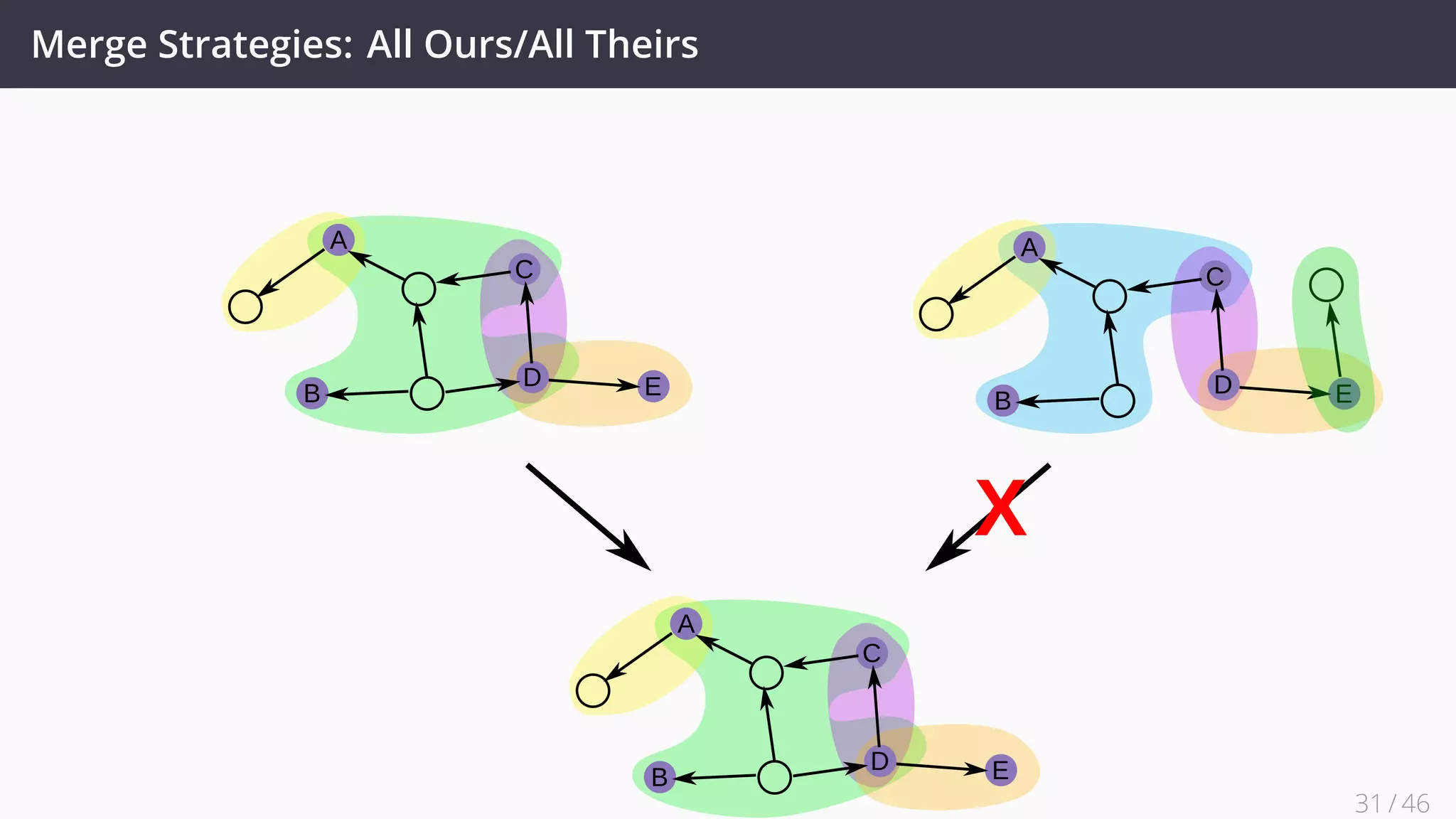
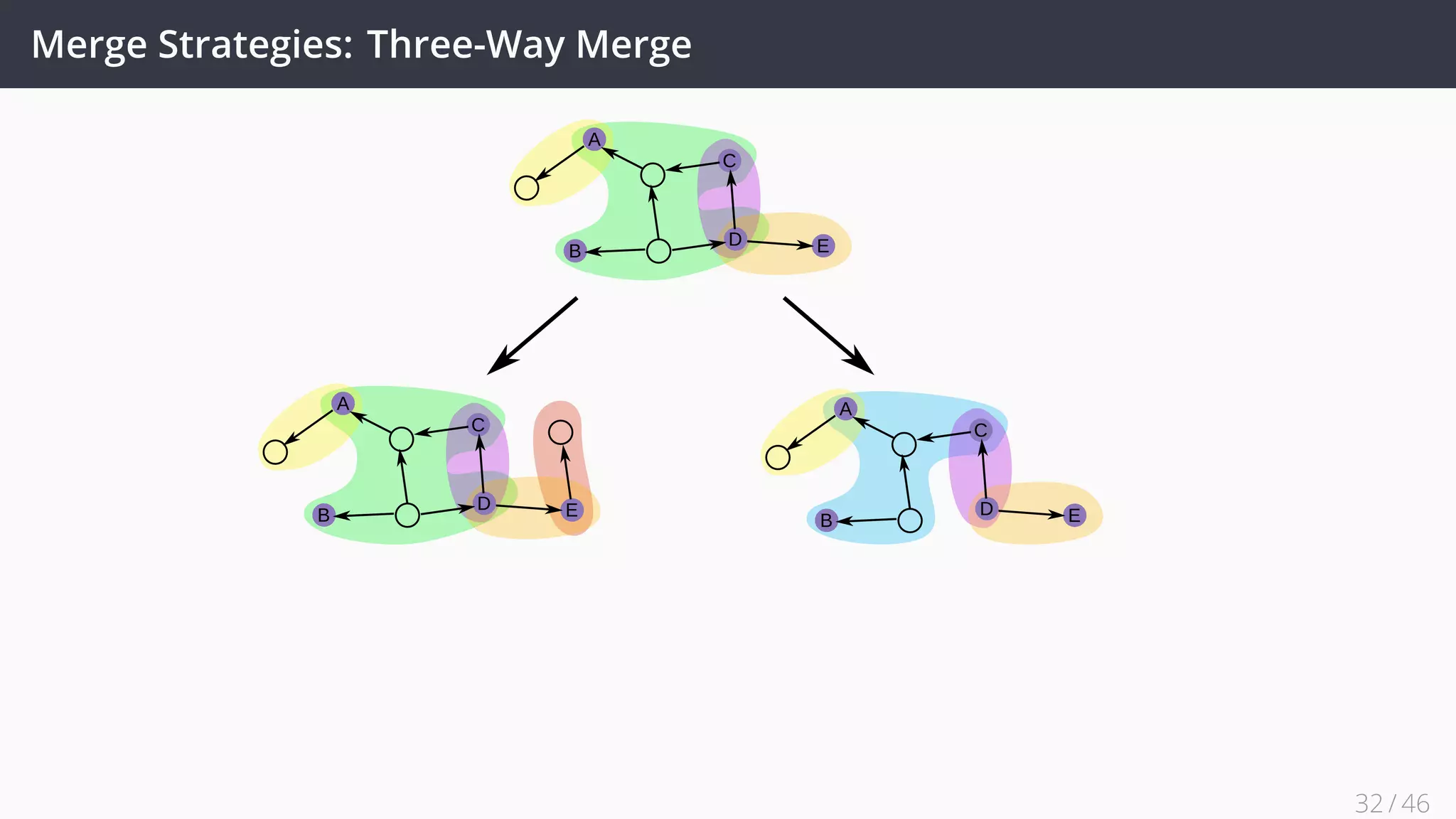
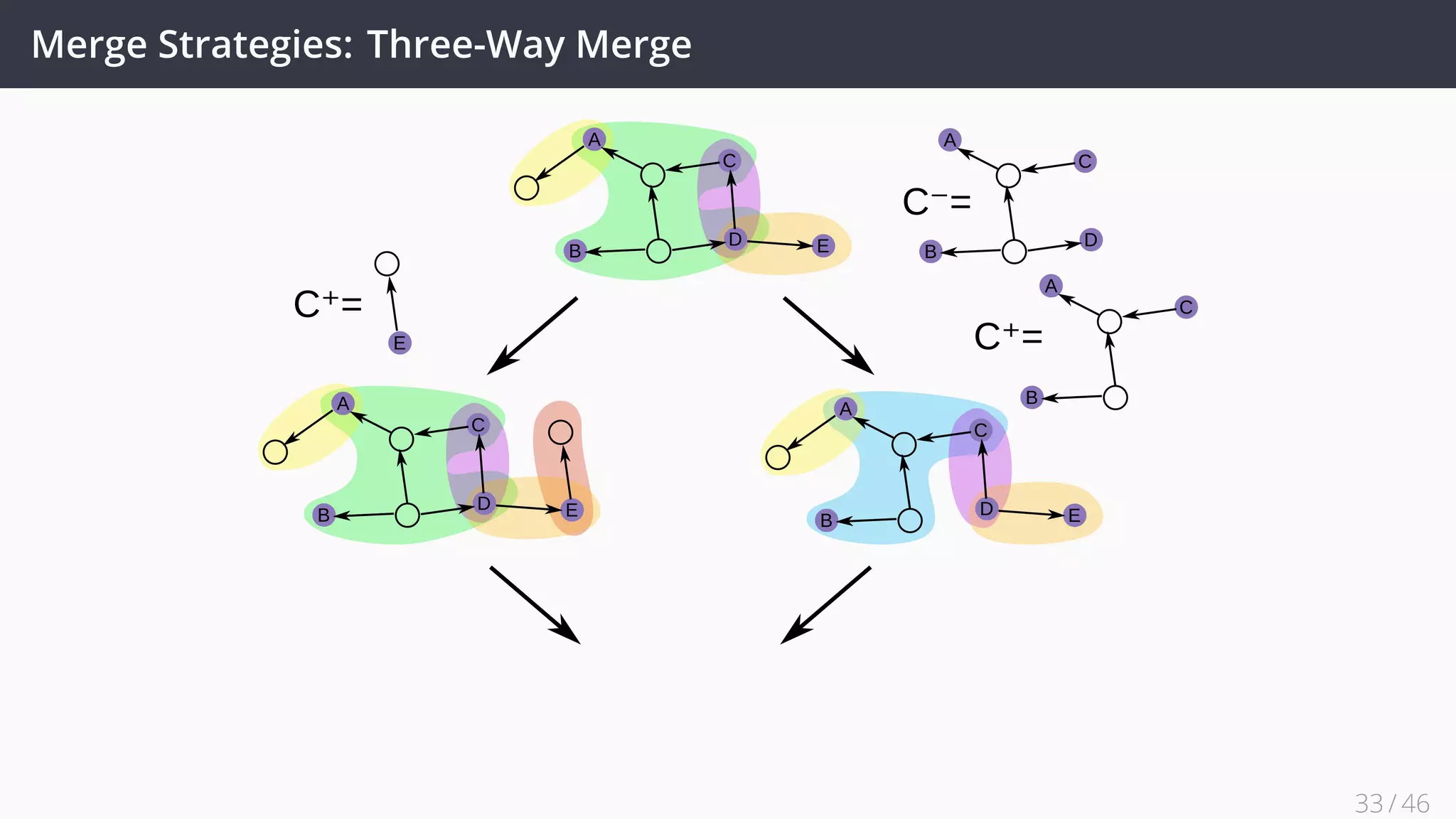
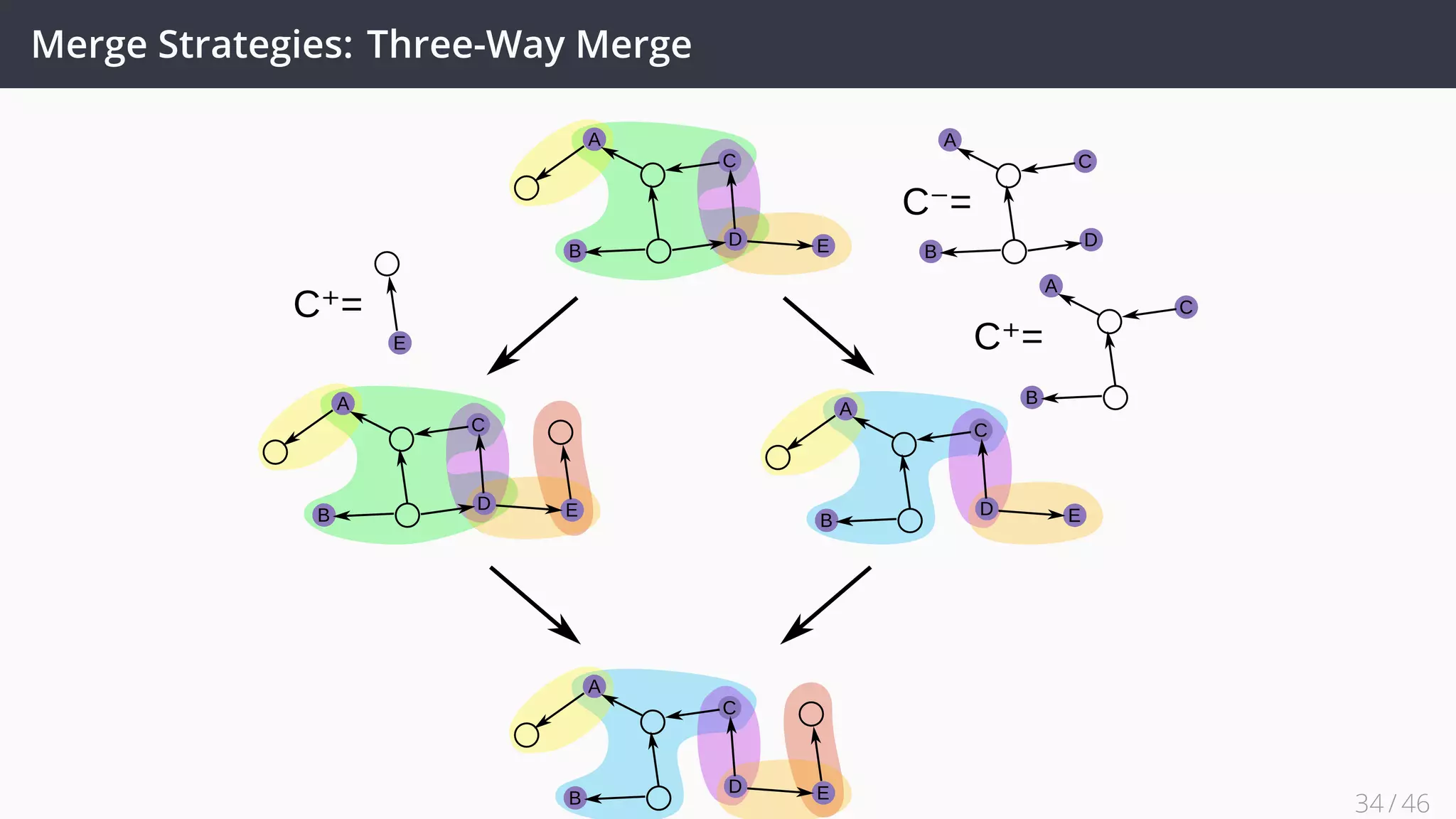
This document discusses decentralized evolution and consolidation of RDF graphs. It proposes using techniques from distributed version control systems (DVCS) like Git to track changes to RDF graphs. Key contributions include formalizing operations for committing changes, branching, merging graphs, and reverting commits. Strategies for merging graphs with conflicts like three-way merging are presented. An evaluation of a prototype implementation demonstrates it can correctly track changes and merge graphs while providing good performance. Future work includes improving support for the full framework and applying it to real world knowledge bases.
















![Introducing TiDB [Delivered: 09/25/18 at Portland Cloud Native Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/portlandk8smeetupintroducingtidb-180926052719-thumbnail.jpg?width=640&height=640&fit=bounds)















































