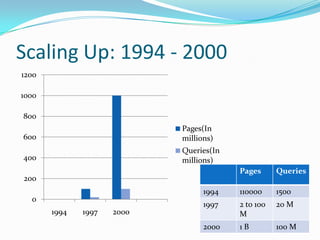
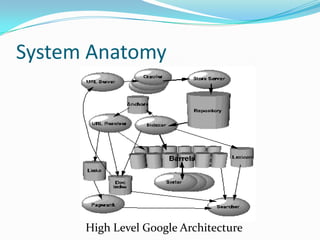
This document discusses the history and design of the Google search engine created by Sergey Brin and Lawrence Page. It outlines the challenges of scaling a search engine to index billions of web pages and handle hundreds of millions of queries. The document also describes Google's techniques for crawling the web efficiently, indexing content, calculating PageRank to determine importance of pages, and using anchor text to improve search results.