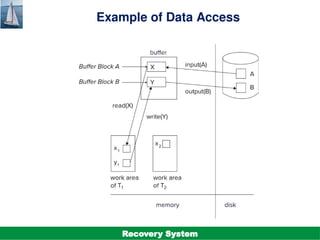
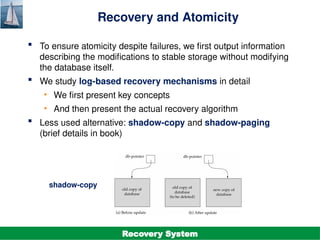
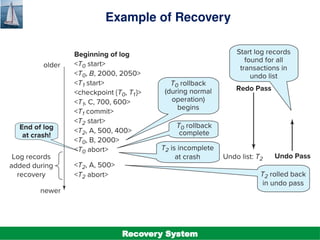
The document discusses the recovery system in database management, focusing on failure classification, recovery algorithms, and storage structures. It outlines the mechanisms employed to ensure atomicity, consistency, and durability of transactions, including log-based recovery and checkpointing techniques. Additionally, it highlights the importance of maintaining stable storage and the steps involved in undoing and redoing transactions during recovery processes.