Download to read offline


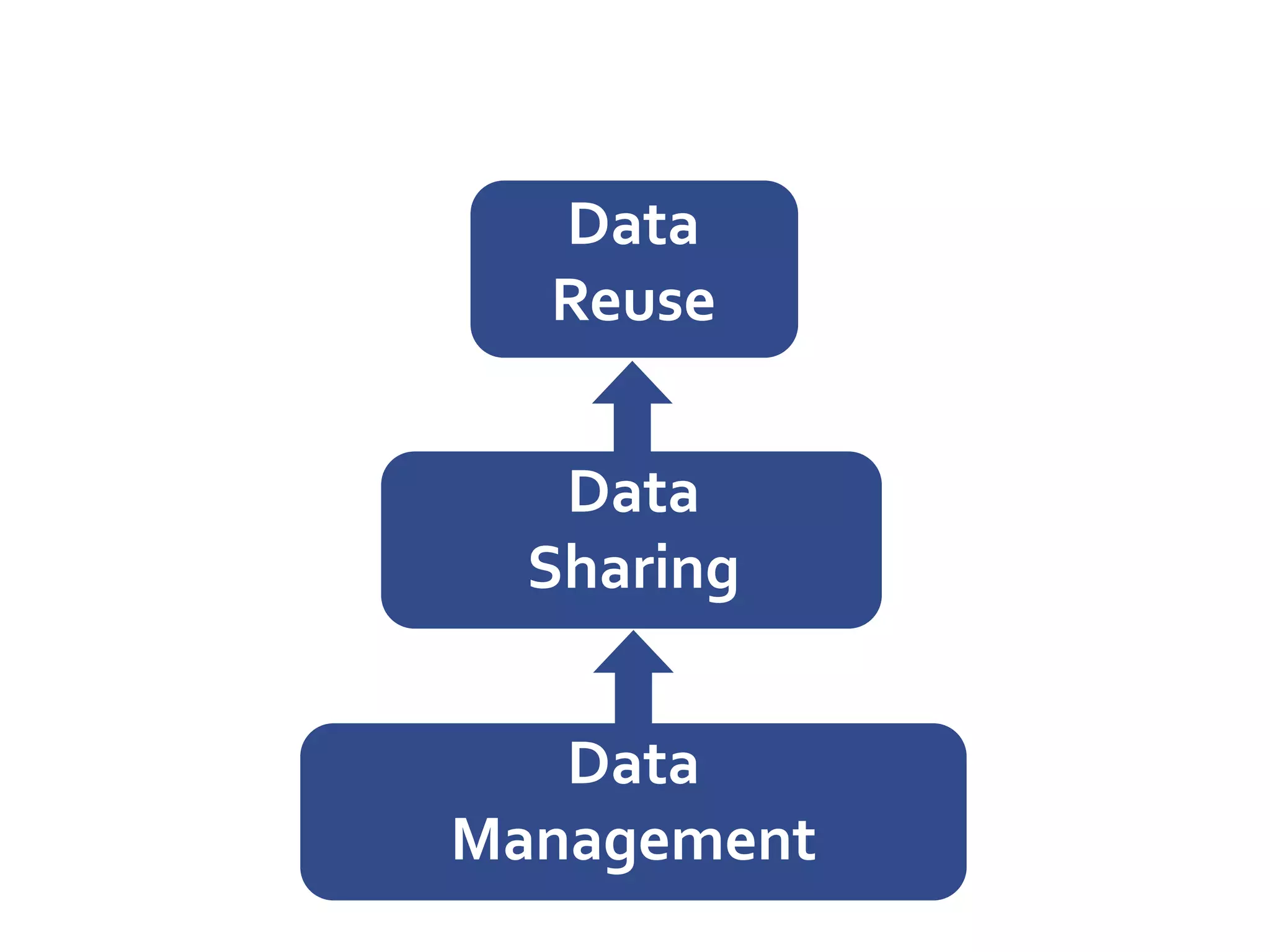

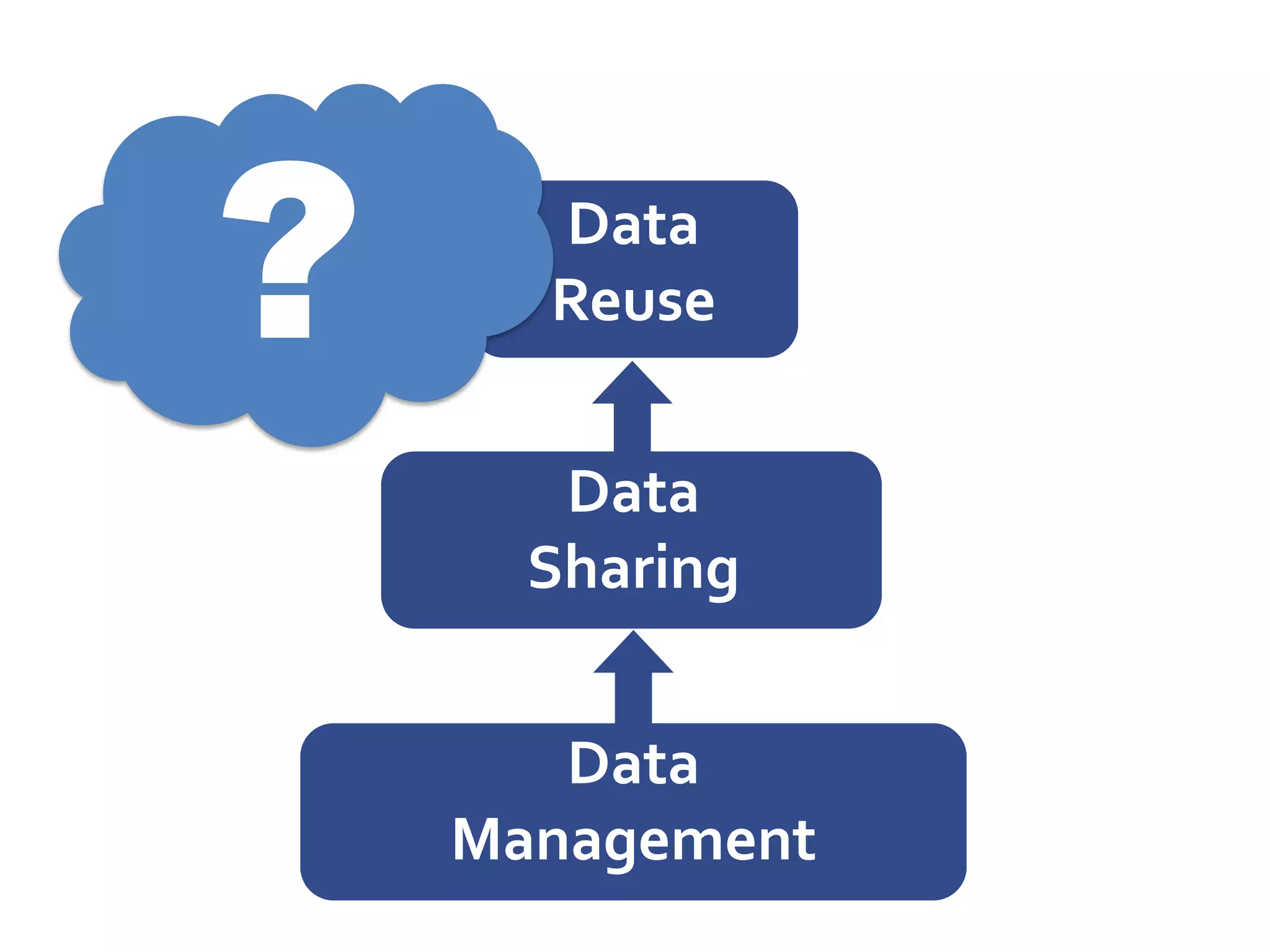


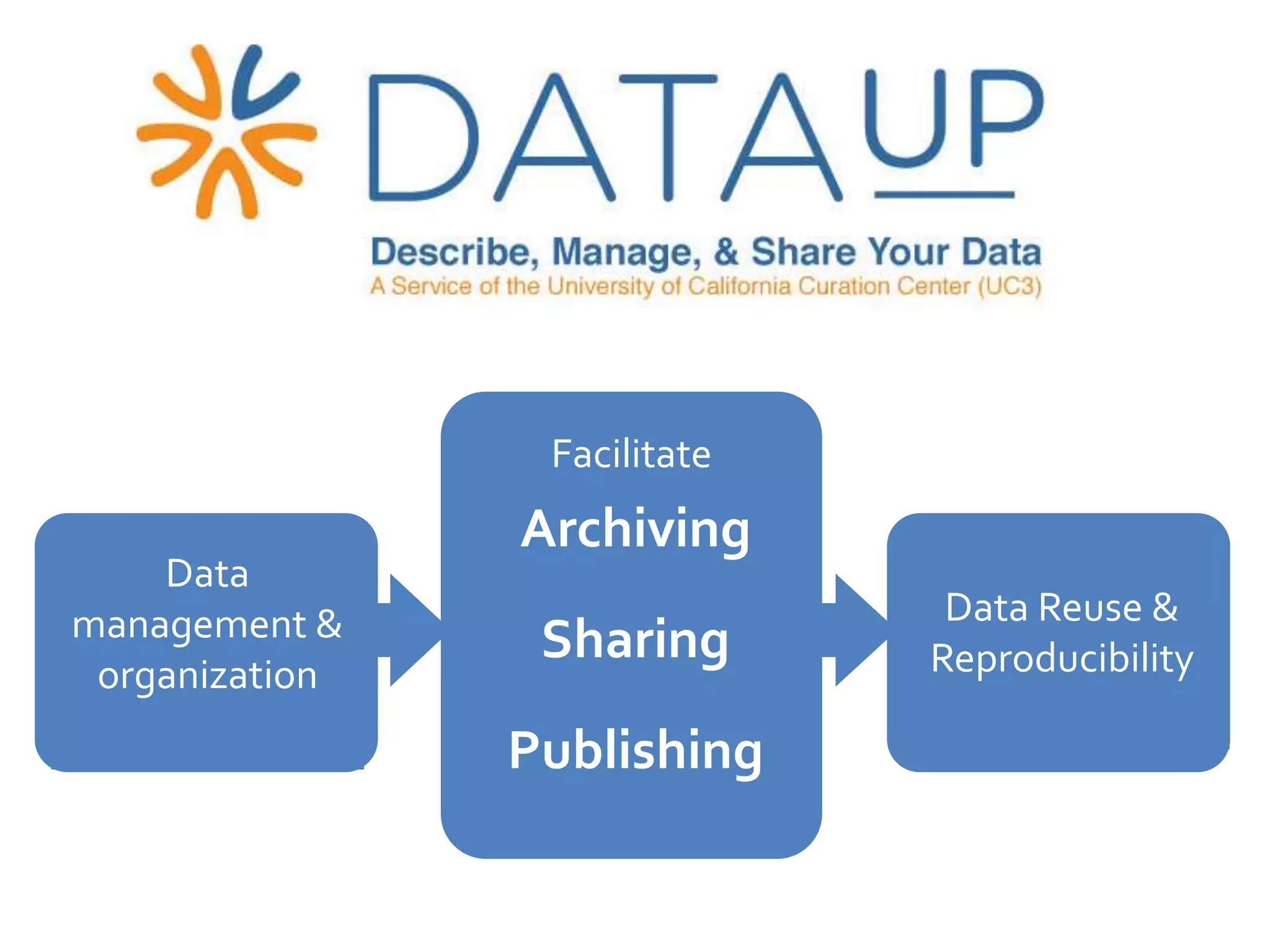
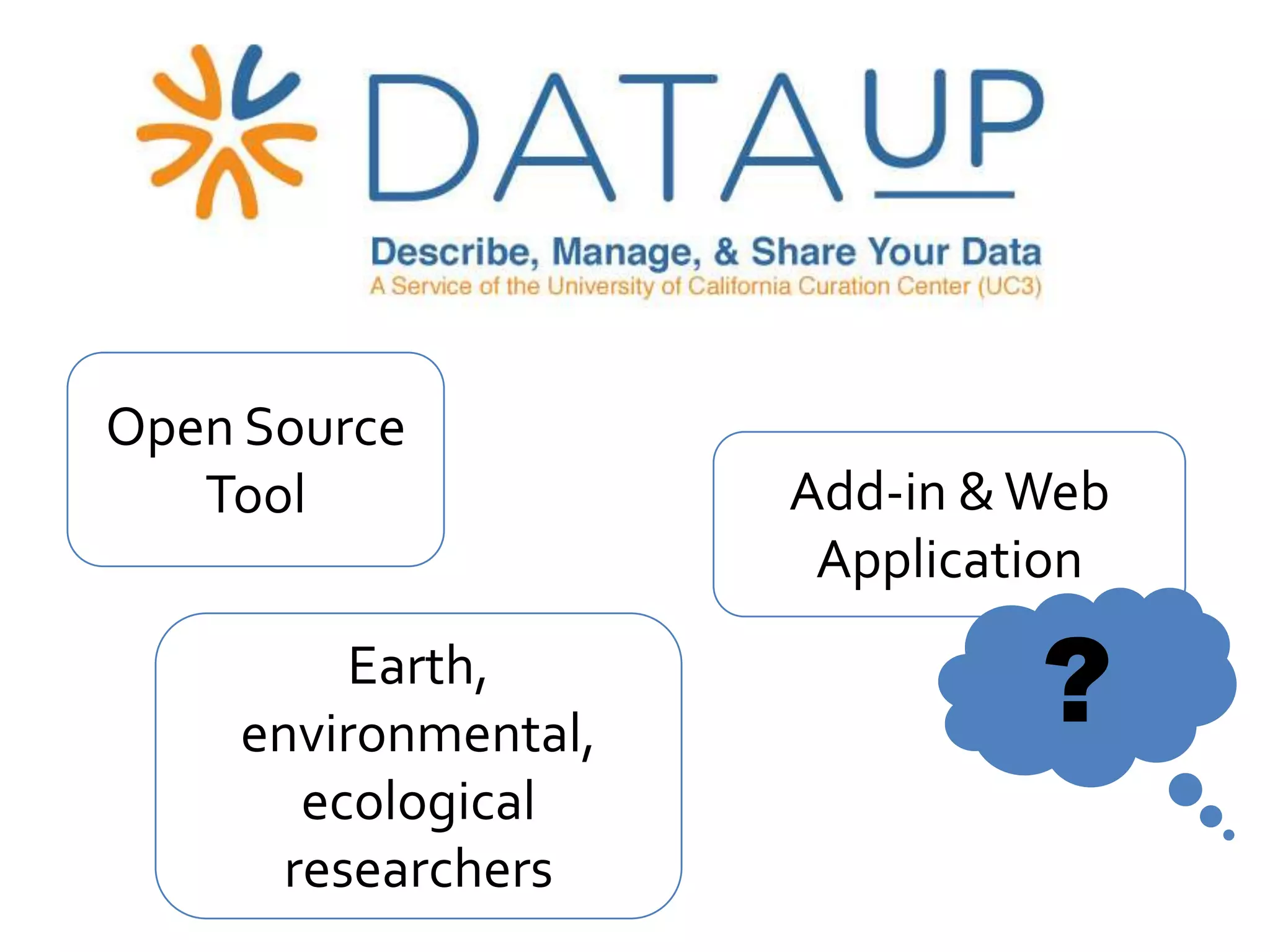






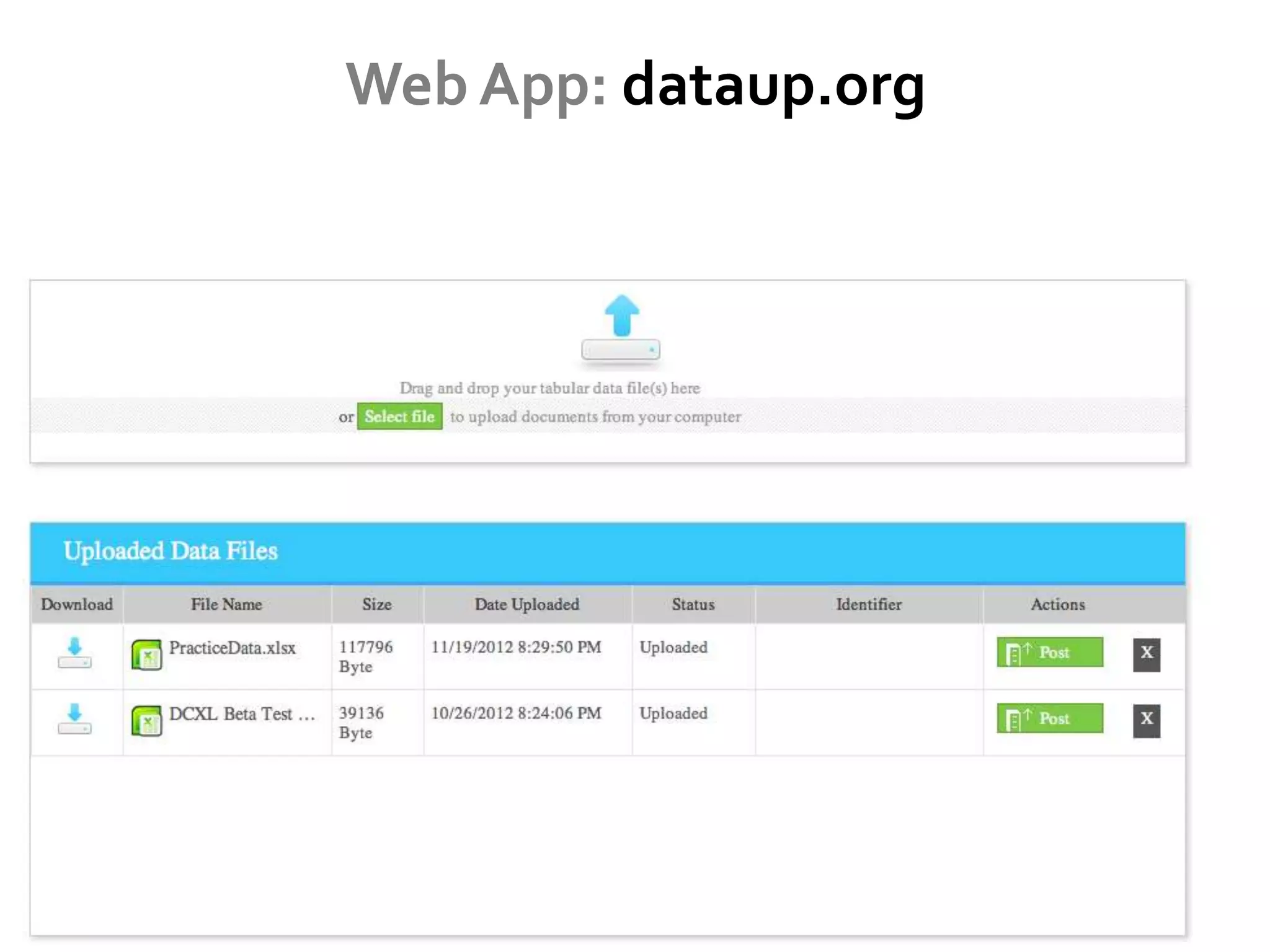
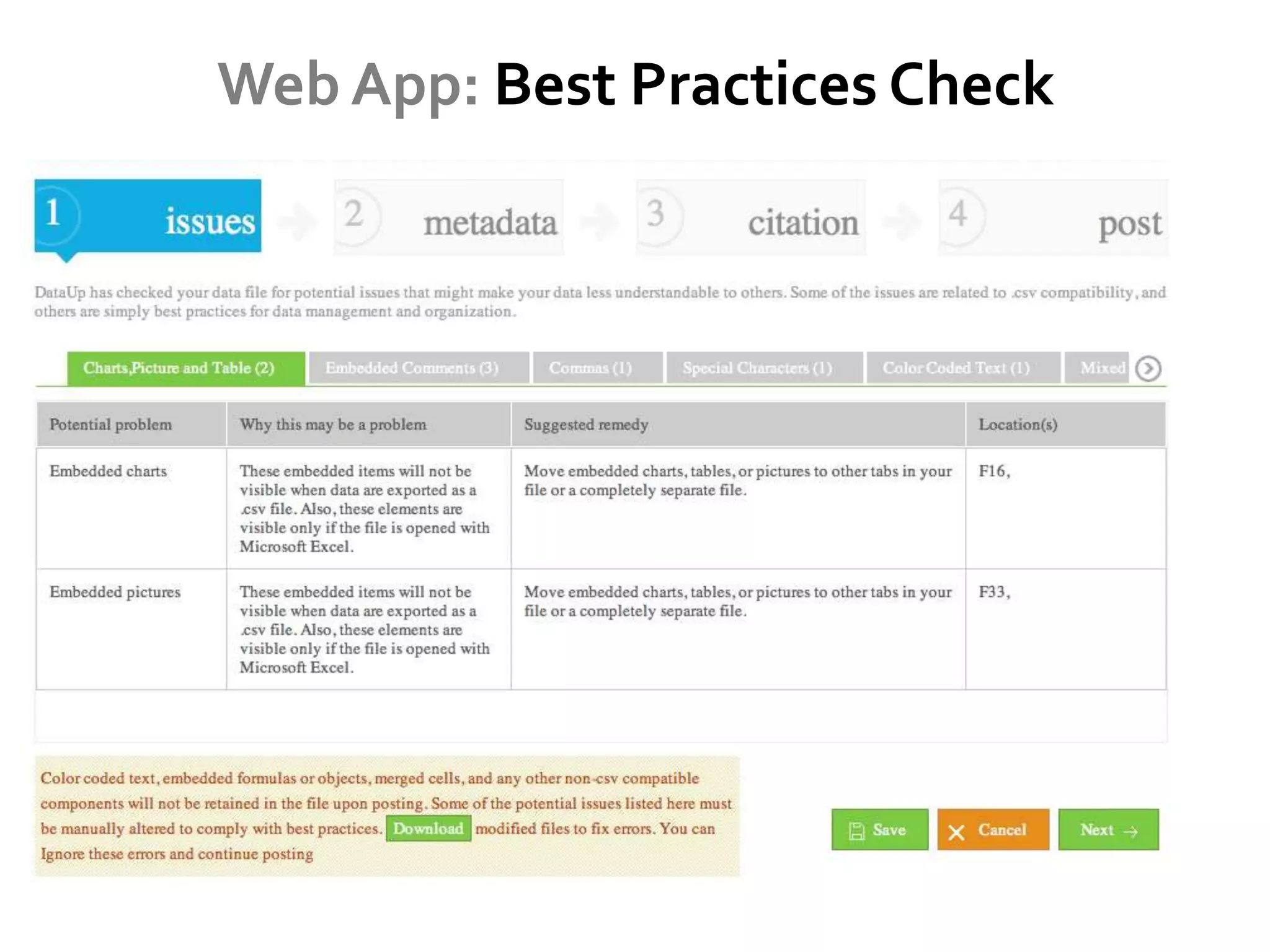
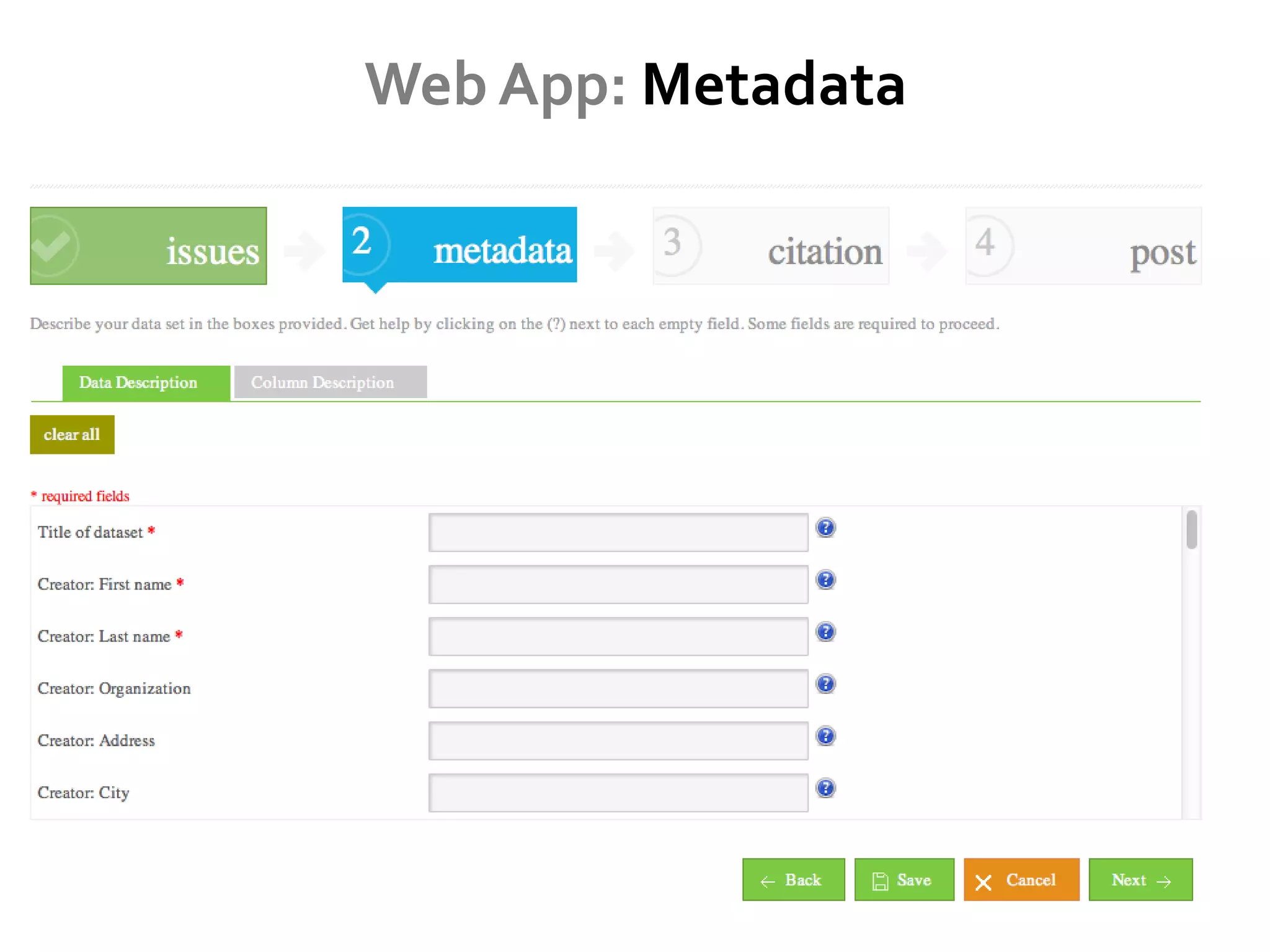
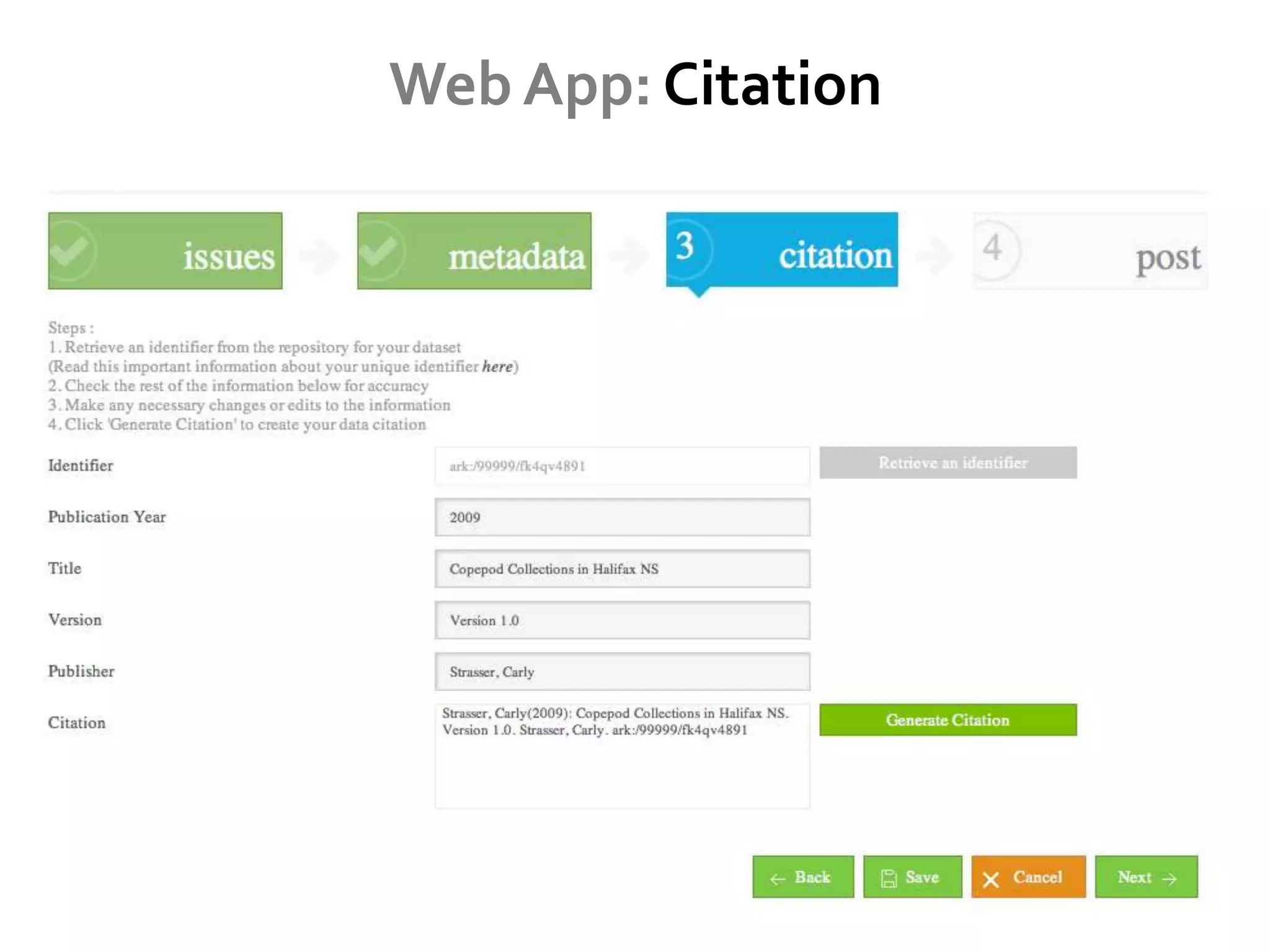
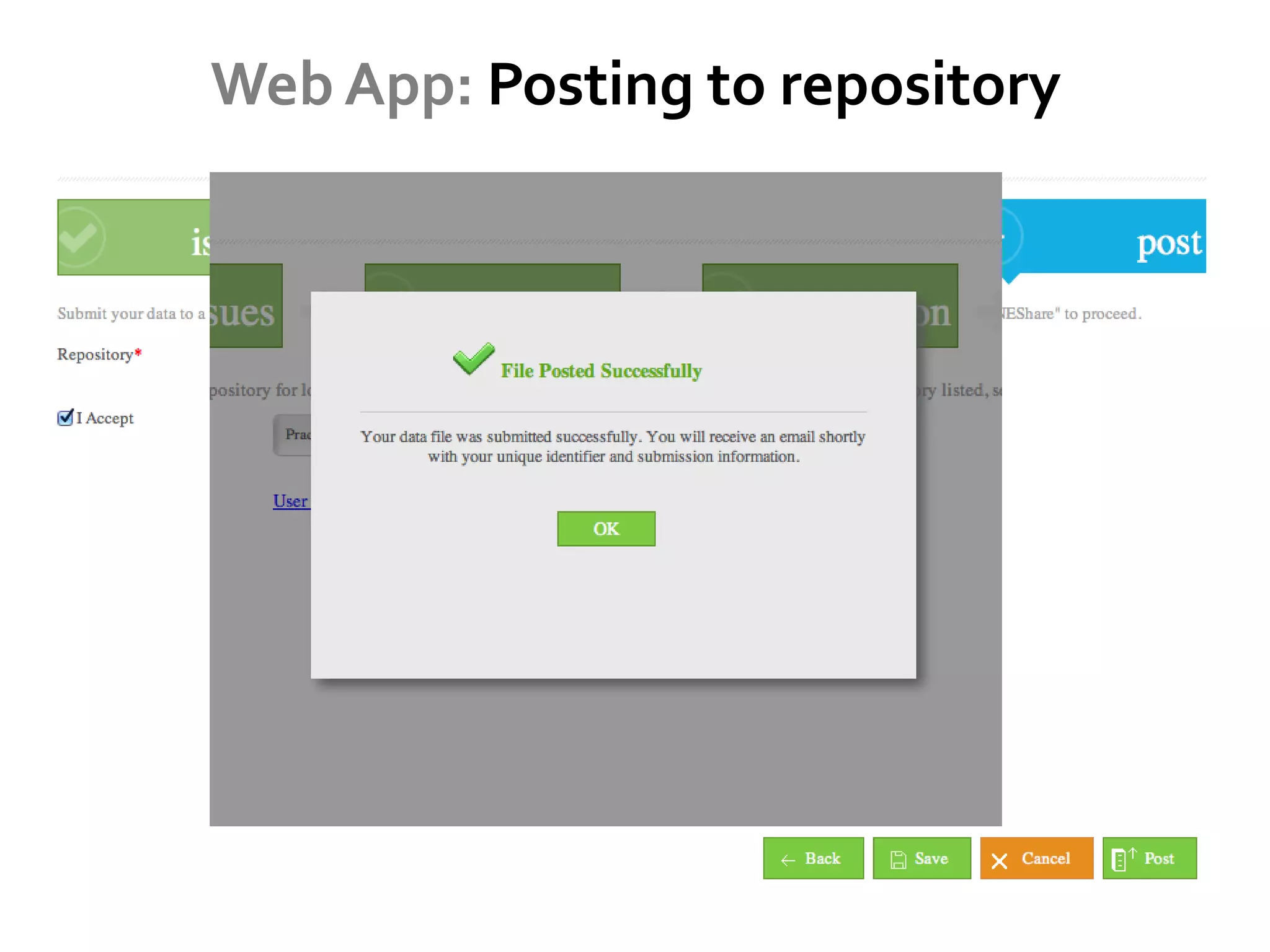

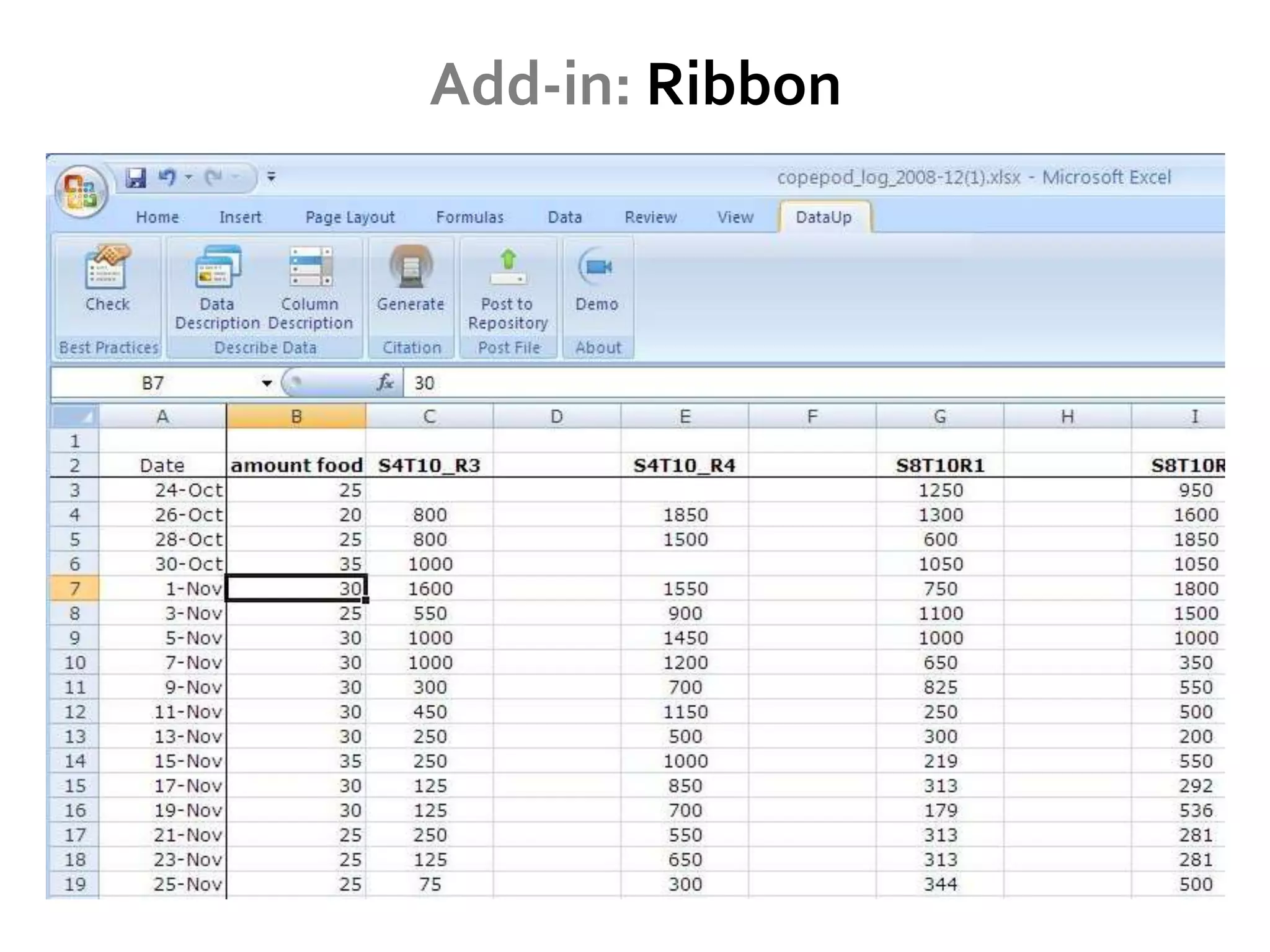
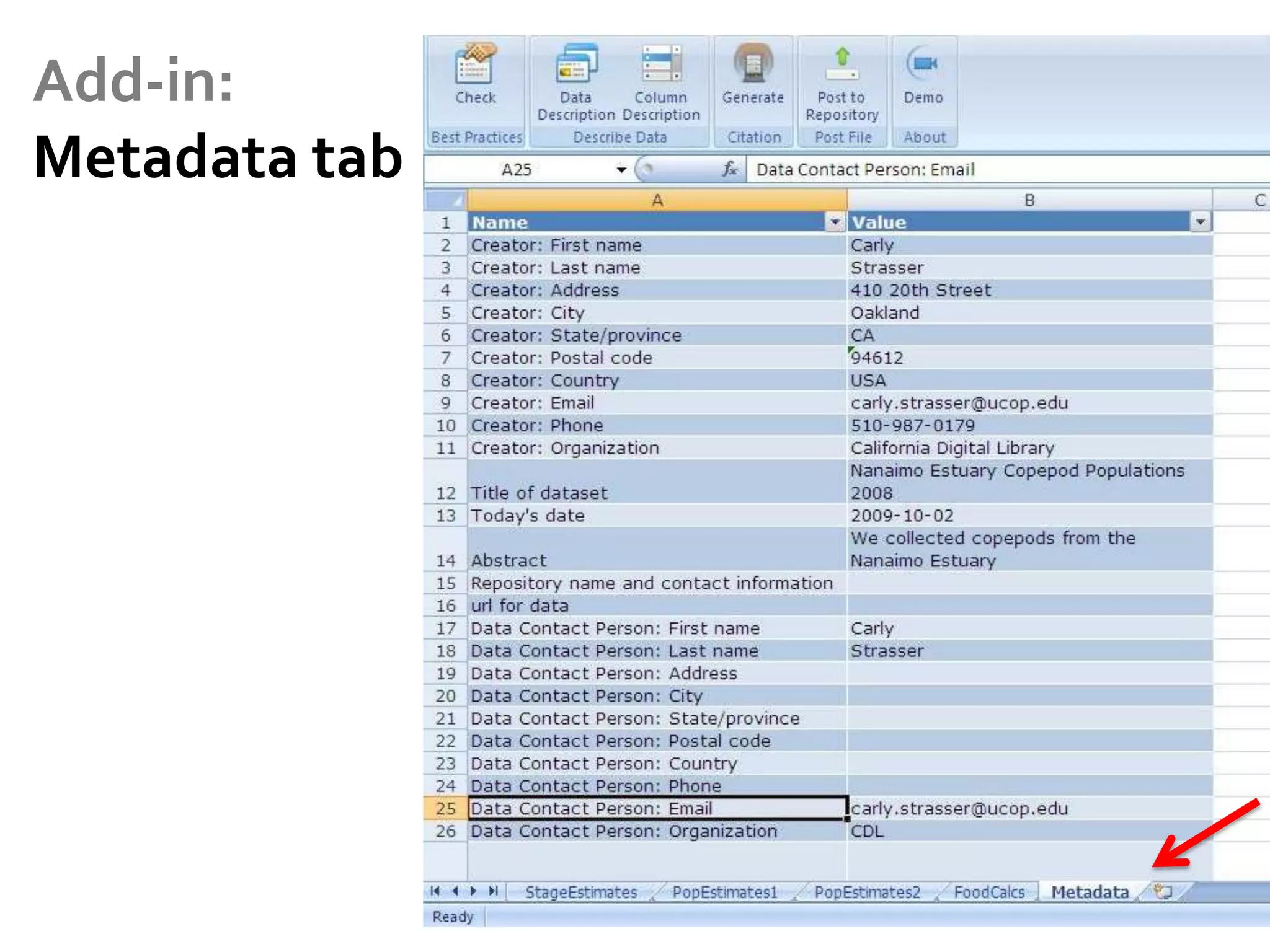


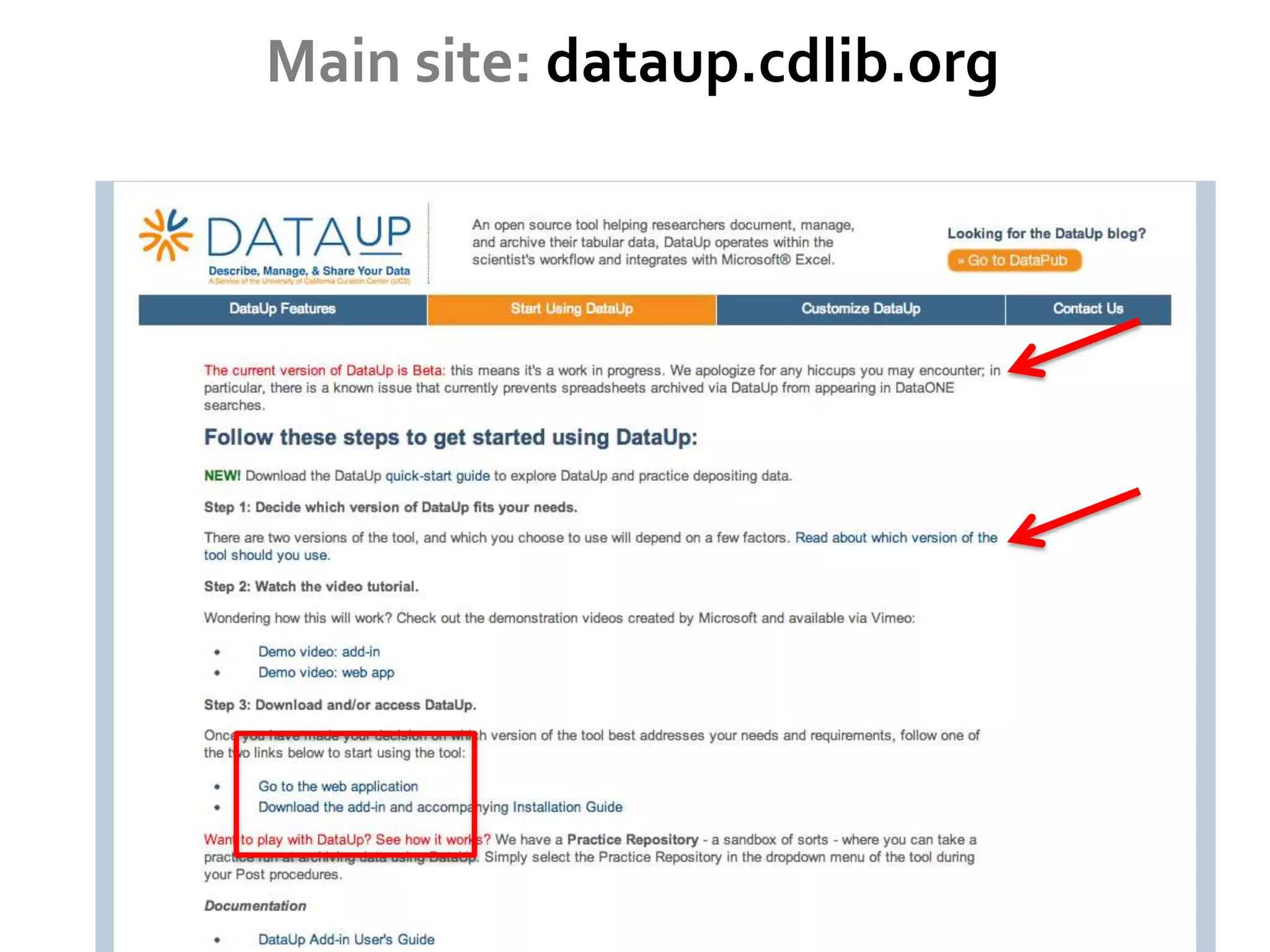
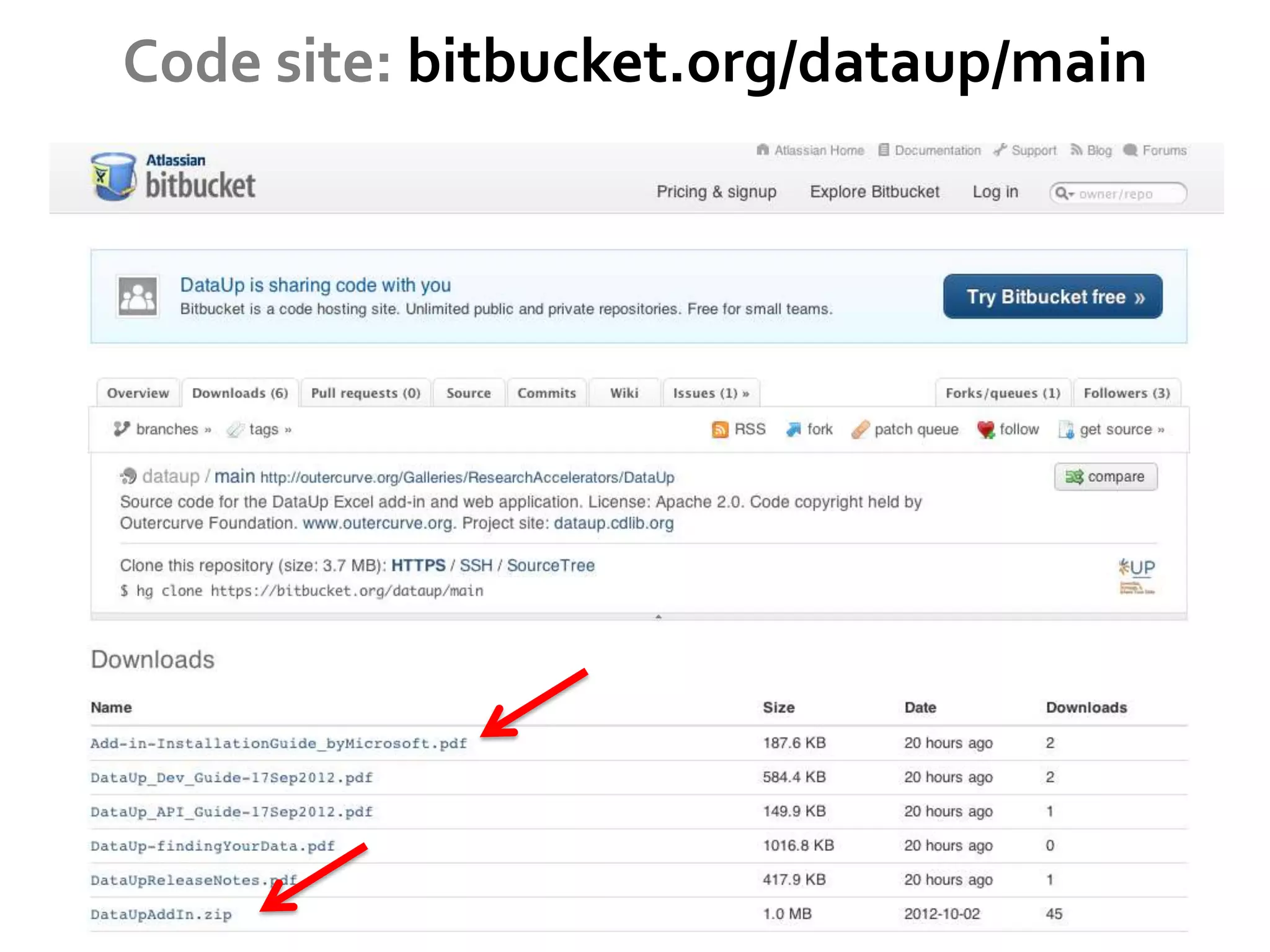
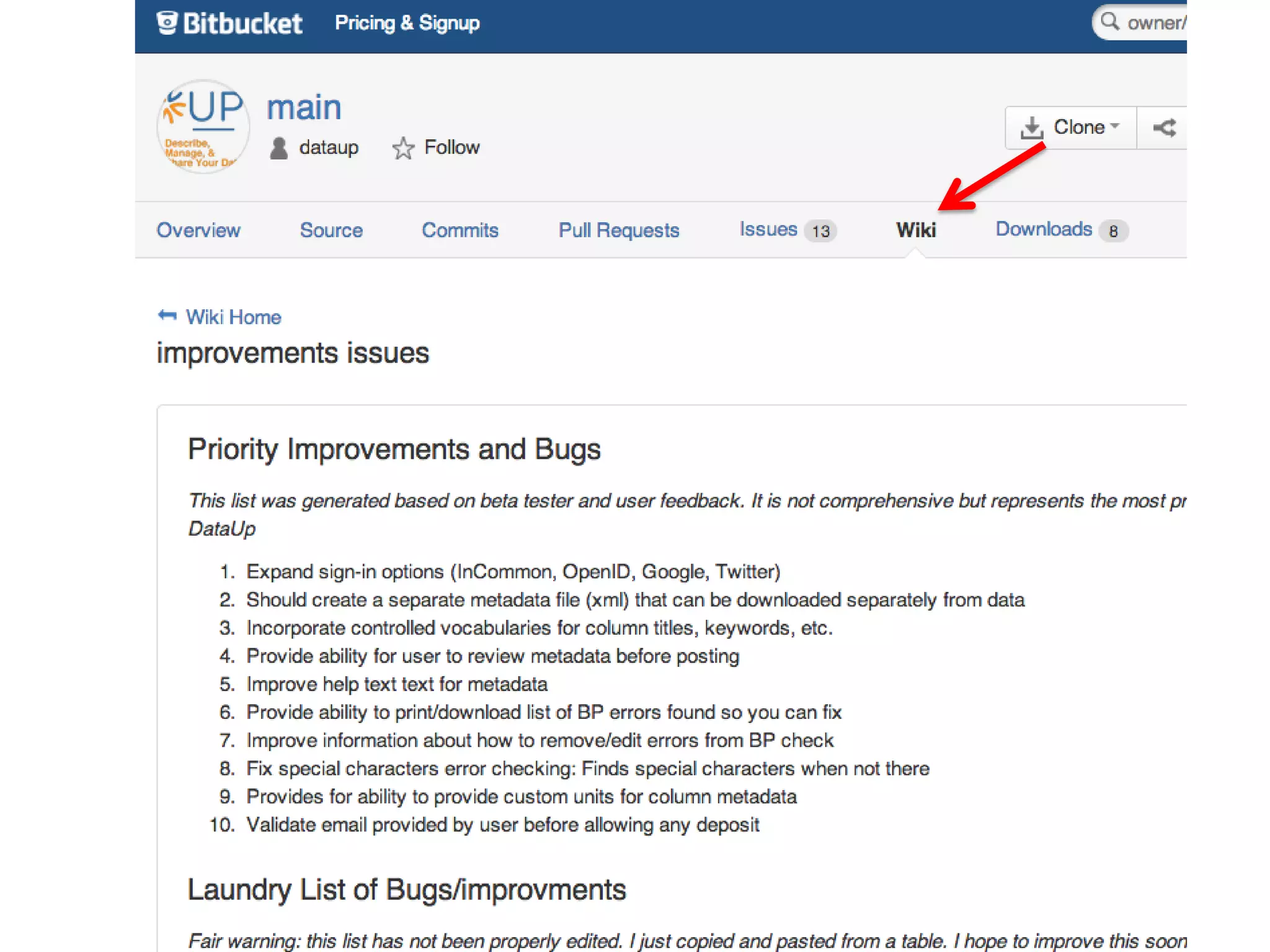



DataUp is a web application and Excel add-in designed to assist scientists with managing, archiving, and sharing their data effectively. Key features include best practice checks, metadata generation, citation creation, and direct posting to repositories, addressing common challenges such as poor data documentation and a lack of awareness about data preservation. The project also aims to engage developers and build a community around data stewardship best practices.



































































