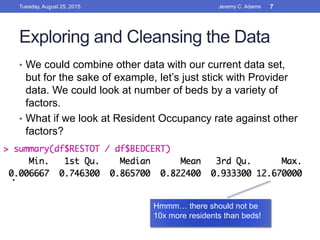
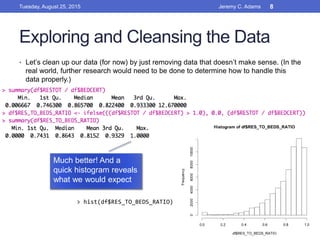
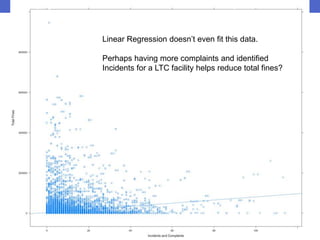
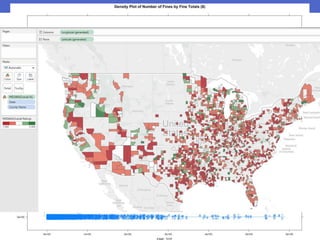
This document outlines the workflow for preparing data visualizations, including getting the data, exploring and cleansing it, identifying key variables, testing for usability, building the data, and creating models and visualizations. It discusses downloading data from various sources, cleaning invalid values, selecting important variables through subject matter experts, checking for normality and anomalies, and provides examples of different types of visualizations like scatter plots, linear regressions, density plots, and heatmaps.




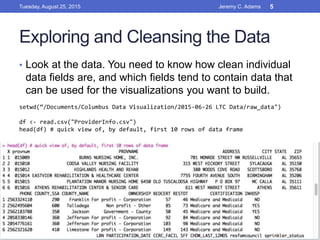
![Exploring and Cleansing the Data
• It’s usually helpful to start by using 400 randomly chosen
rows from a given table of large size (10k+ rows).
rand400 <- df[sample(nrow(df), 400), ] # random sample of 400 rows from df
Tuesday, August 25, 2015 Jeremy C. Adams 6](https://image.slidesharecdn.com/datavizworkflow-150827143821-lva1-app6891/85/Data-Visualization-Workflow-6-320.jpg)