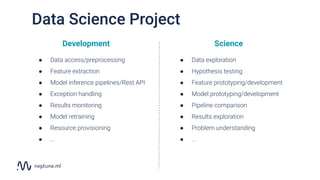
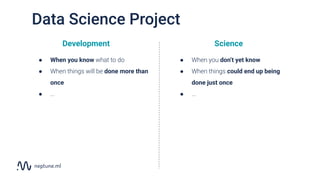
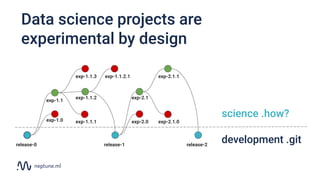
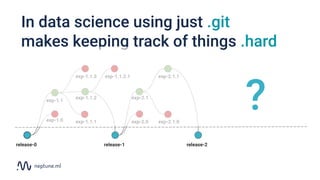
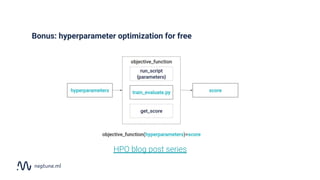
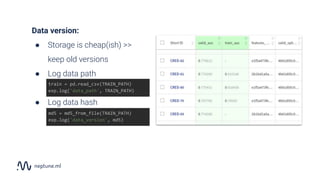
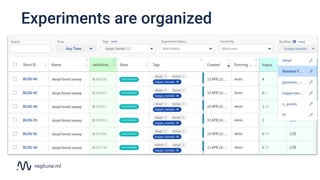
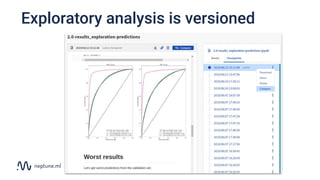
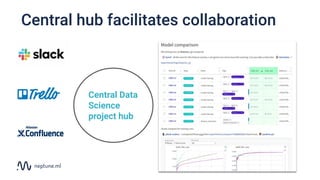
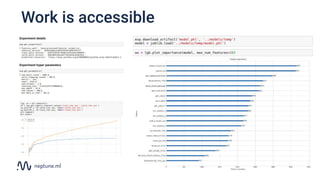
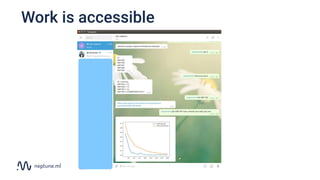
The document discusses the distinction between data science and software development, emphasizing that data science projects are inherently experimental and require different management approaches. It introduces experiment management as a process for organizing and tracking experiments, which helps improve collaboration and reproducibility within data science teams. The document also outlines best practices for experiment management, including version control, metric tracking, and results exploration.