Download to read offline




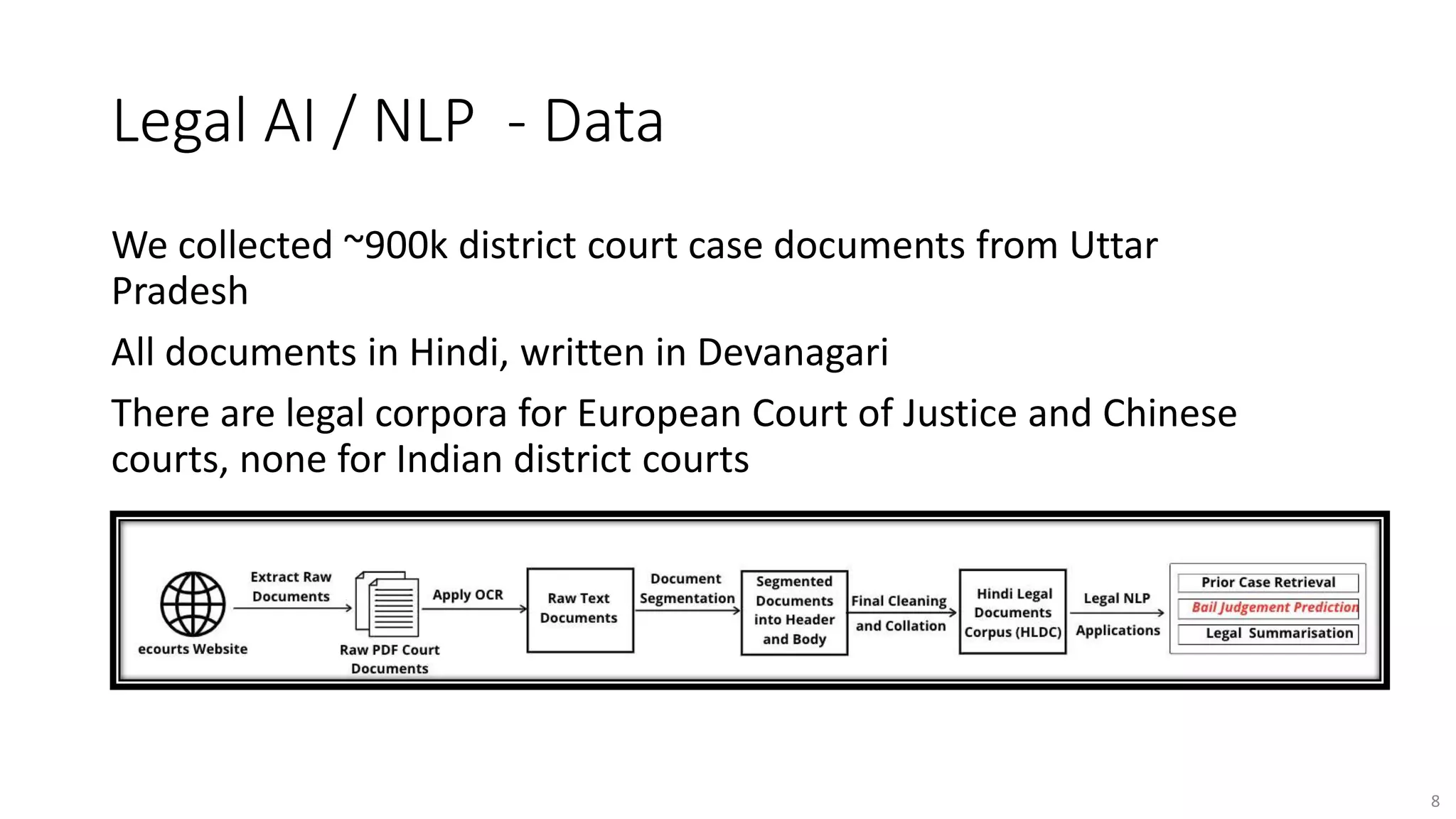


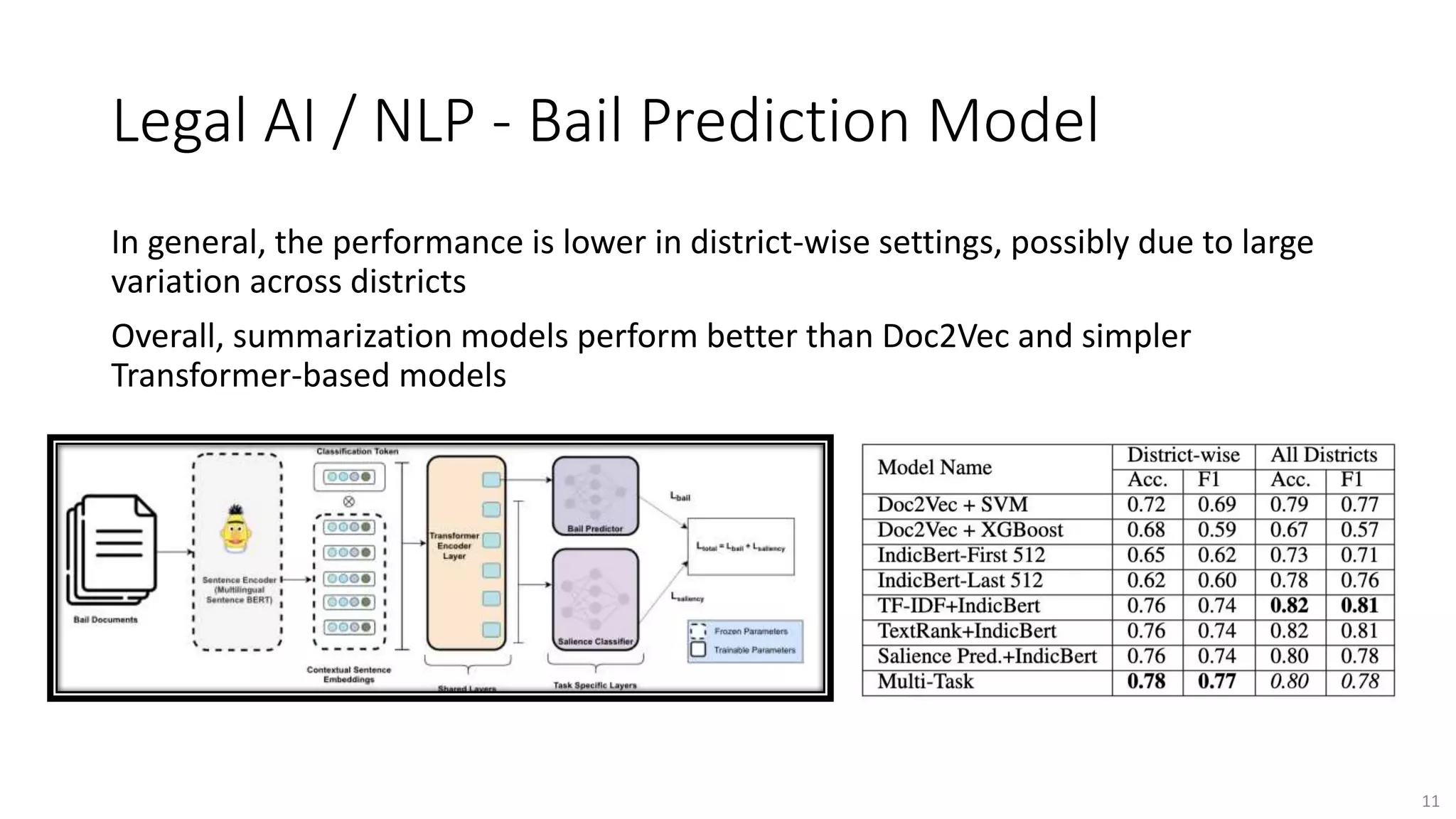





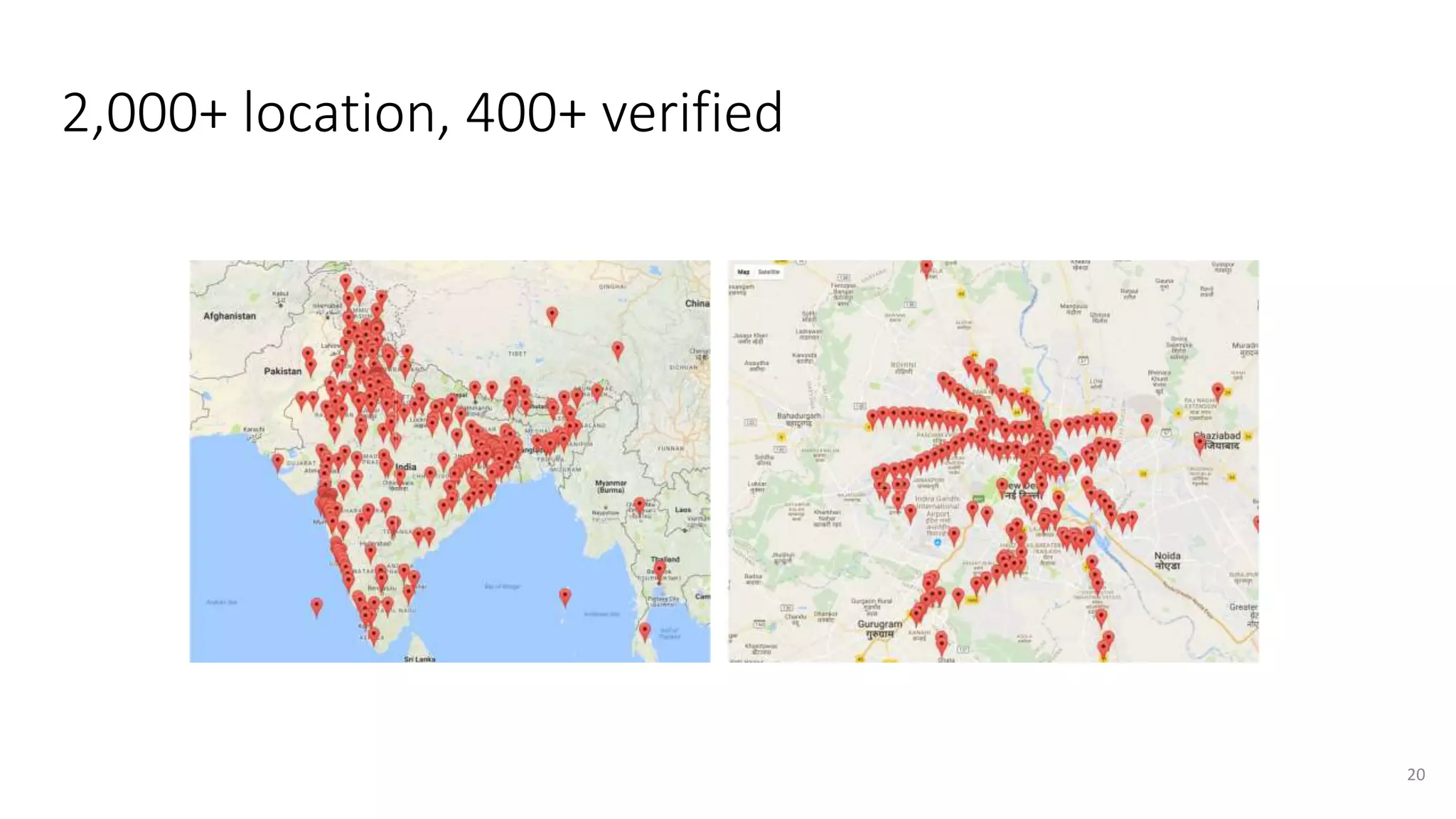

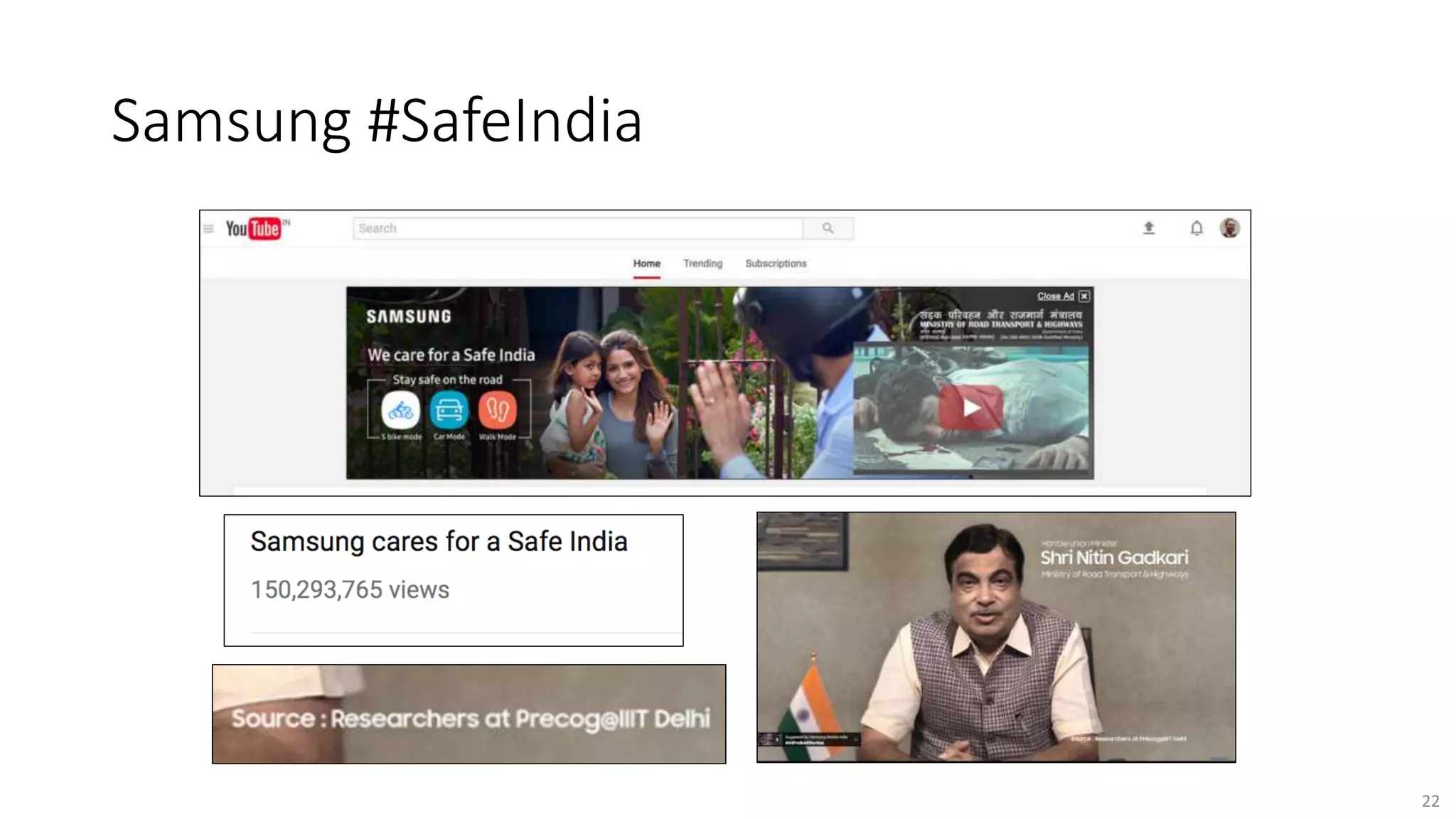
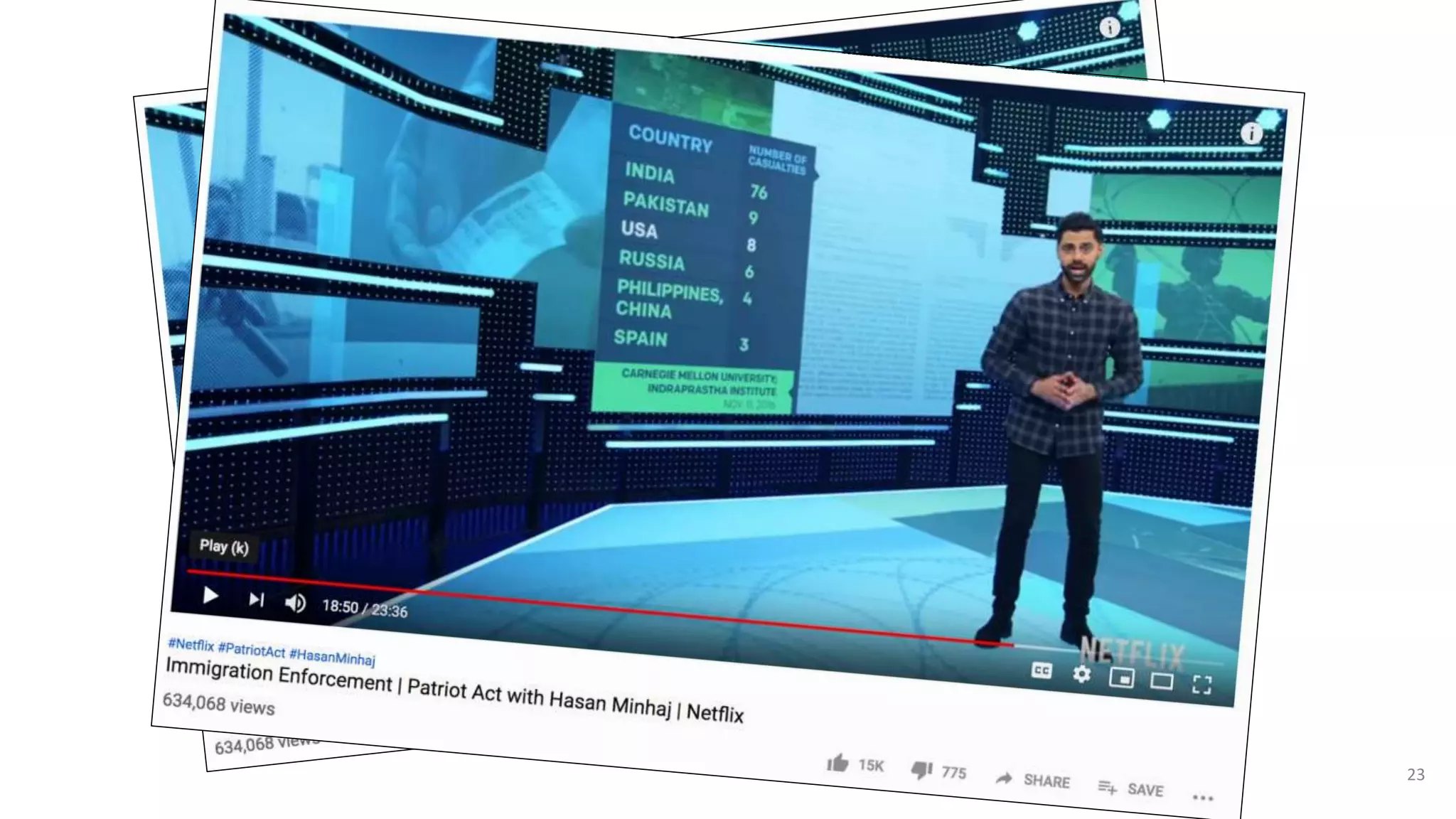
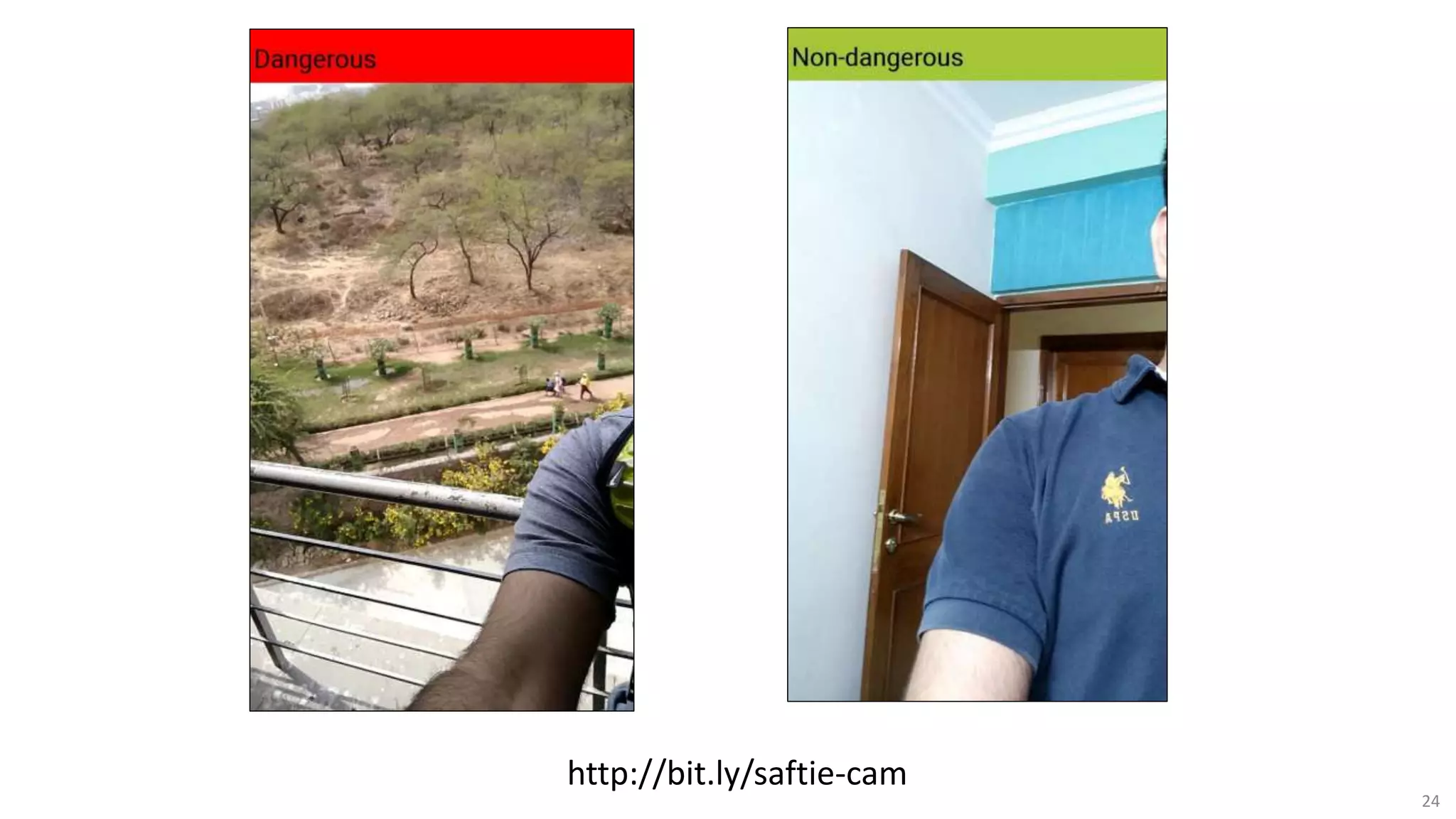




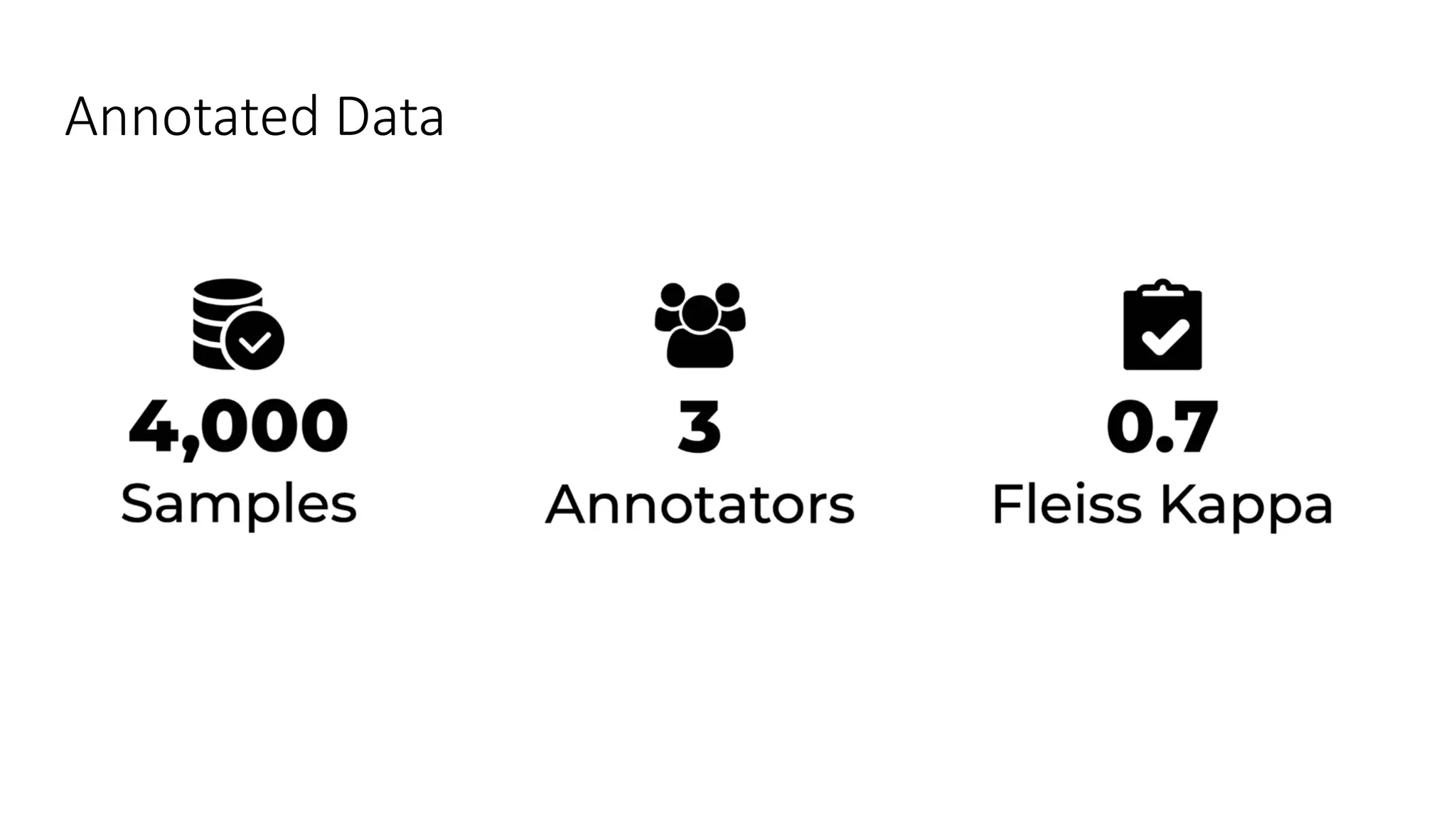
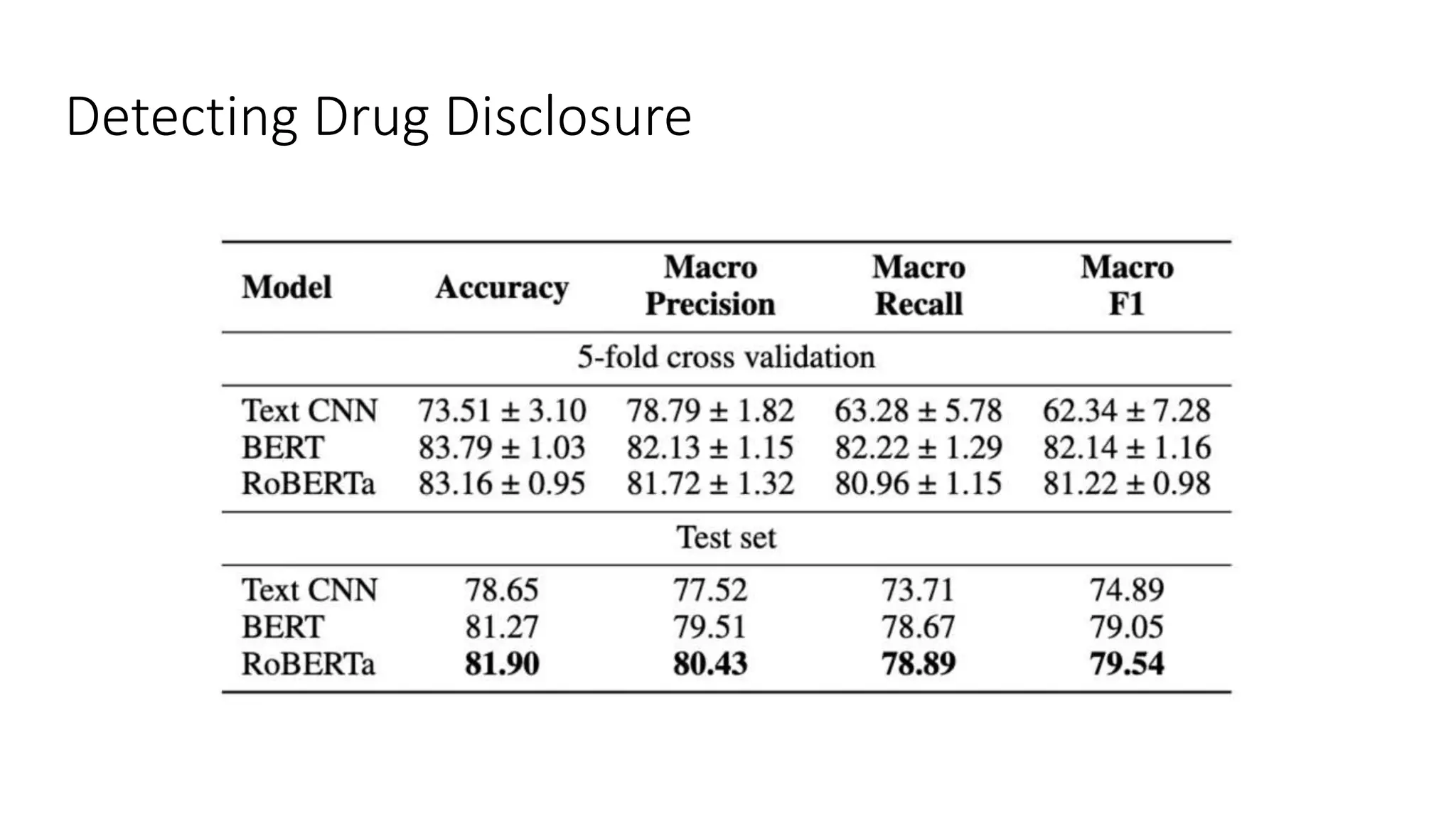
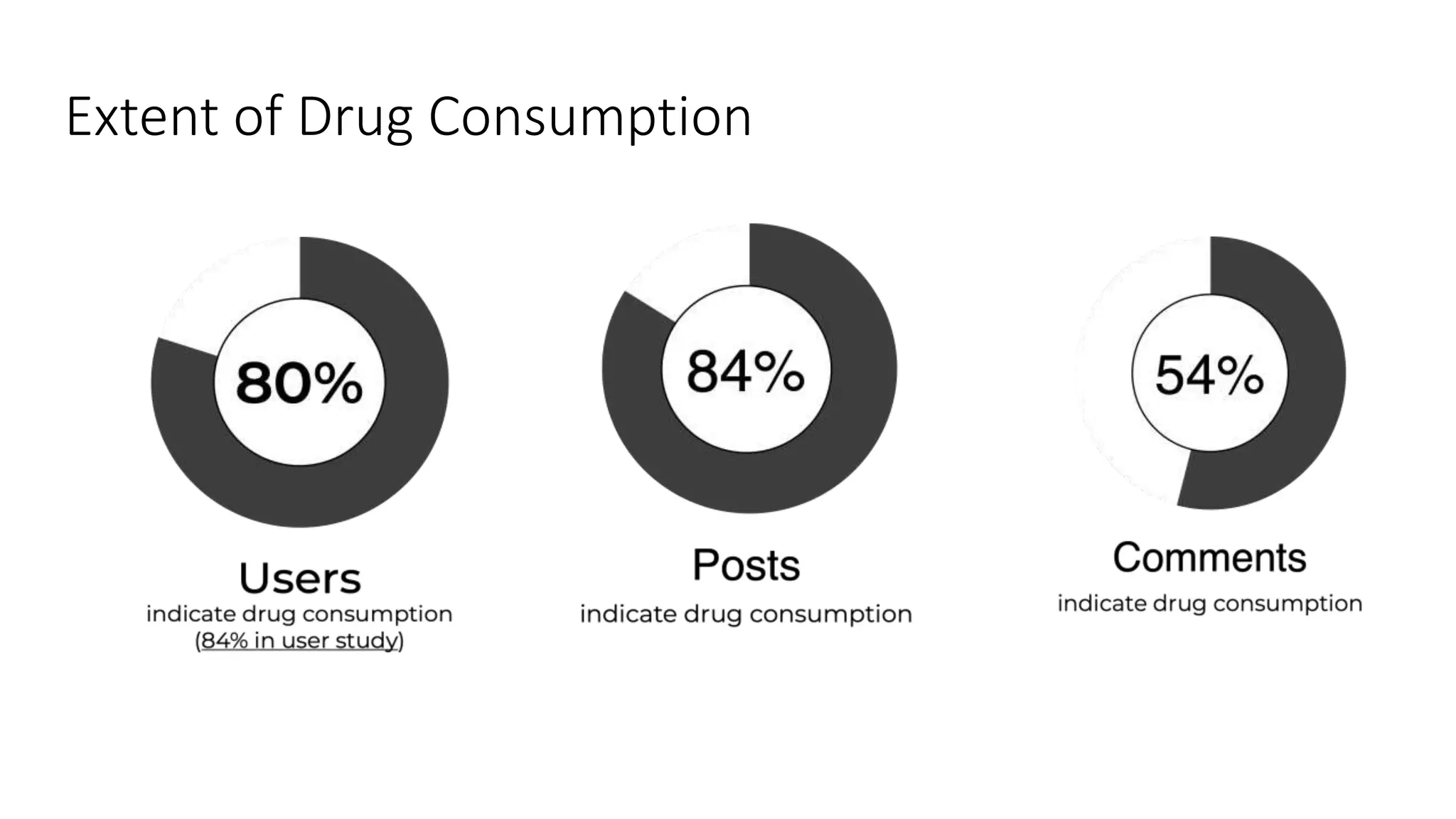








The document discusses opportunities for interdisciplinary research in data science, particularly focusing on legal NLP and algorithmic bias within the Indian judicial context. It highlights the unique challenges faced by district courts in India, such as case backlogs and language barriers, while also detailing a specific legal document corpus and initial findings from various legal AI models. Additionally, the document outlines topics for potential research collaboration and the preparation needed for academic publishing and post-doctoral opportunities.



































































