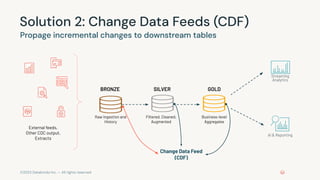
This document provides an overview of a training on data privacy patterns. It includes an agenda for lessons on storing data securely, deleting data in Databricks, and streaming data and change data feeds (CDF). It summarizes key learning objectives around identifying use cases for data privacy, securing sensitive data, and leveraging CDF. It also previews upcoming lessons on pseudonymization, anonymization techniques like generalization and suppression, and how CDF addresses propagating updates and deletes in streaming data.