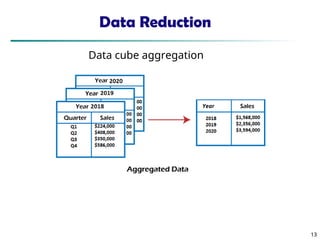
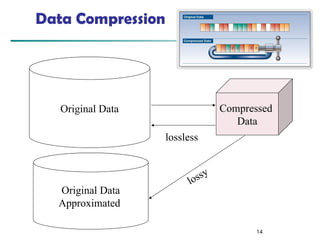
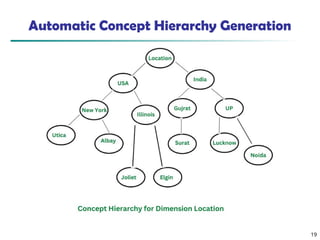
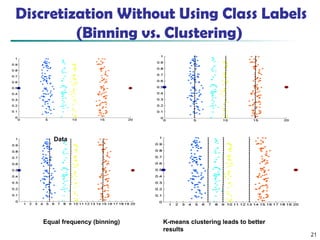
The document discusses data preprocessing in precision agriculture, detailing its importance for ensuring data quality through tasks such as data cleaning, integration, reduction, and transformation. It emphasizes the significance of addressing issues like missing, noisy, and inconsistent data for effective data analysis. Various methods and techniques for handling these issues, including normalization, discretization, and dimensionality reduction, are also outlined.