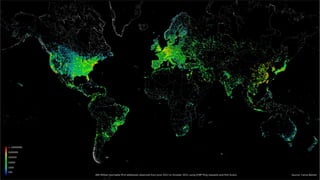
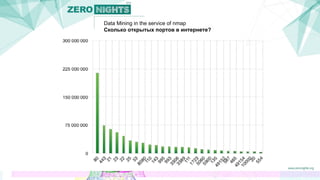
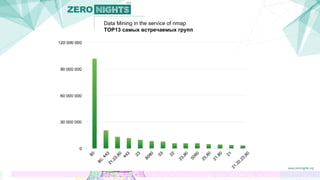
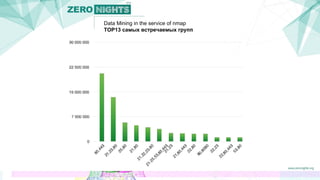
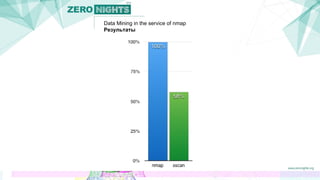
Документ описывает методы добычи данных в контексте сканирования сети с использованием инструмента nmap. Авторы представляют подходы, которые увеличивают эффективность сканирования, минимизируя количество запросов и предсказывая открытые порты на основе анализа групп портов. Также обсуждаются результаты и планы на будущее, включая создание патчей для улучшения nmap и применение полученных данных для кластеризации сервисов.




















![[DagCTF 2015] Hacking motivation](https://cdn.slidesharecdn.com/ss_thumbnails/slides-151211150644-thumbnail.jpg?width=640&height=640&fit=bounds)
































