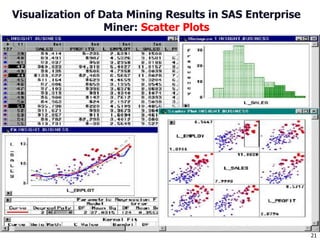
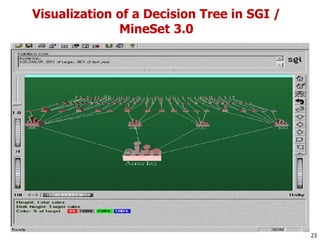
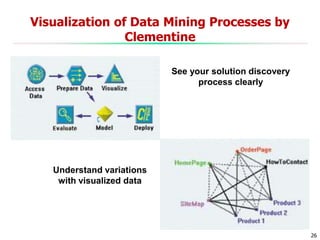
This document discusses data mining applications and trends. It covers topics like mining complex data types, other data mining methodologies, and various applications of data mining. Some key applications discussed include using data mining in finance, retail, telecommunications, science/engineering, intrusion detection, and recommender systems. The document also touches on topics like visual data mining, ubiquitous and invisible data mining, and the privacy and social impacts of data mining.



























































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)


![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)






