Guidance
kyrt @takekazuomi 7
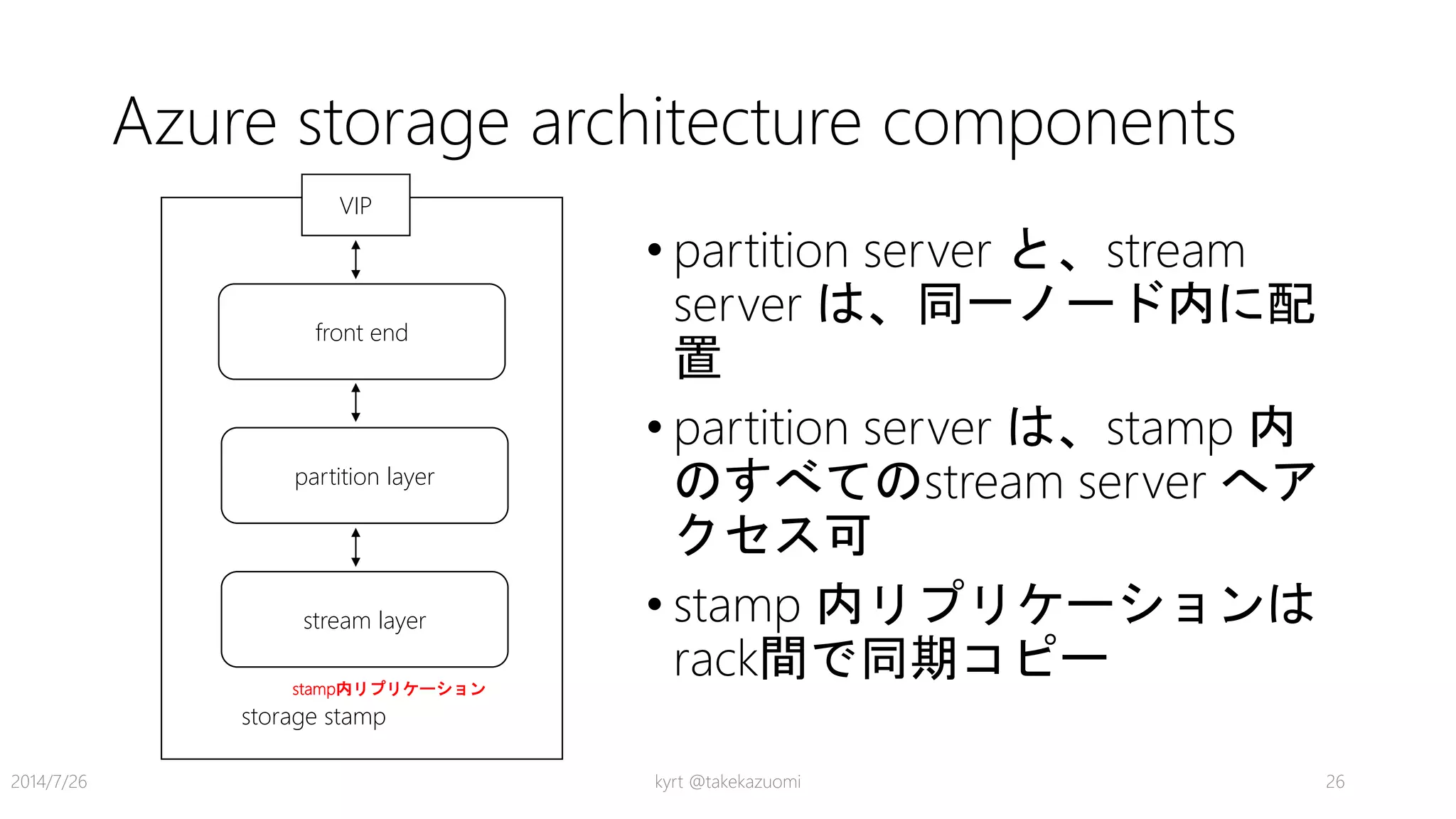
名称Availability Data Management
Design and
Implementati
on
Messaging
Manageme
nt and
Monitoring
Performanc
e and
Scalability
Resiliency Security
code
samples
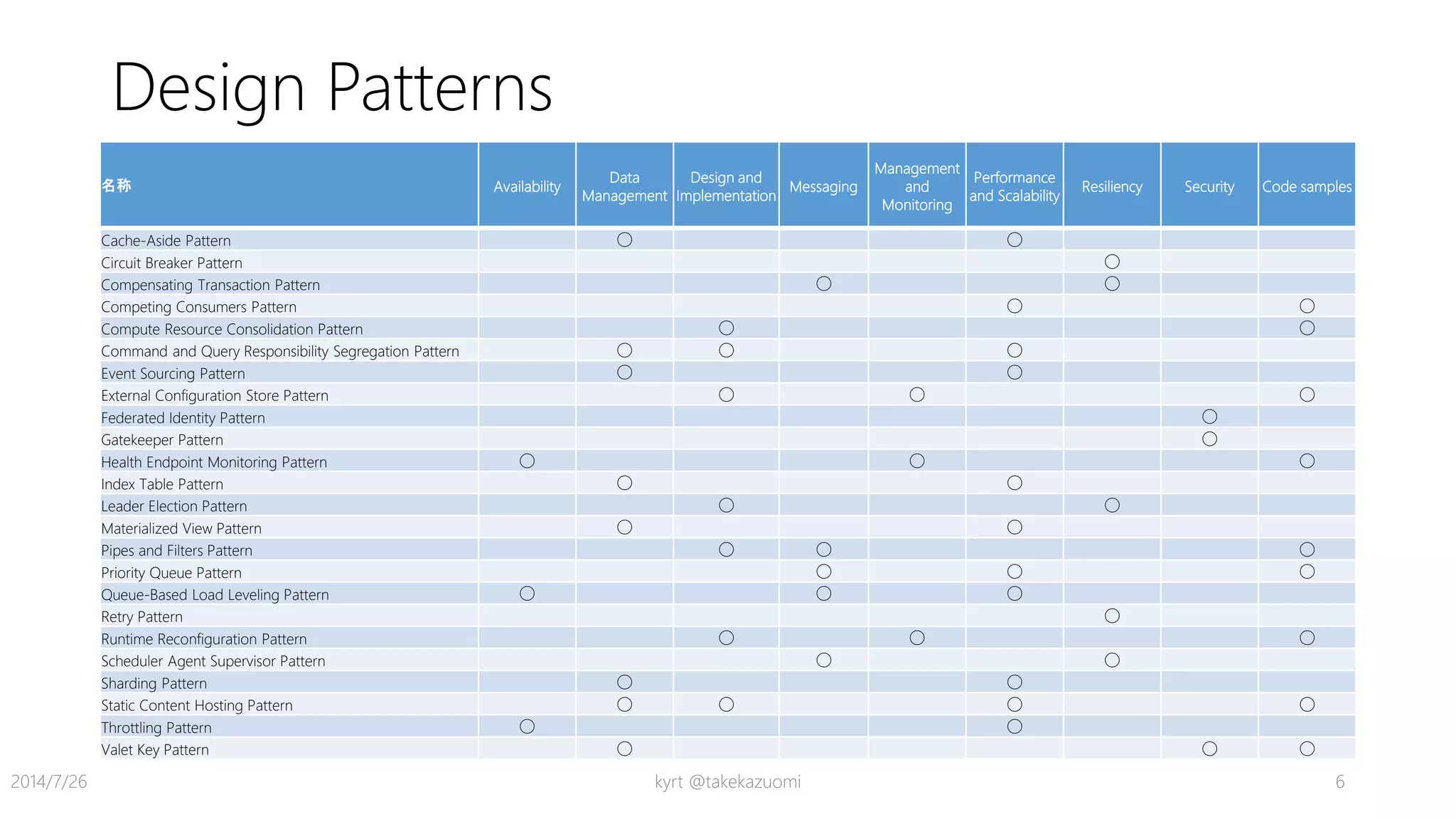
Guidance Asynchronous Messaging Primer ◯
Autoscaling Guidance ◯
Caching Guidance ◯ ◯
Compute Partitioning Guidance ◯
Data Consistency Primer ◯ ◯
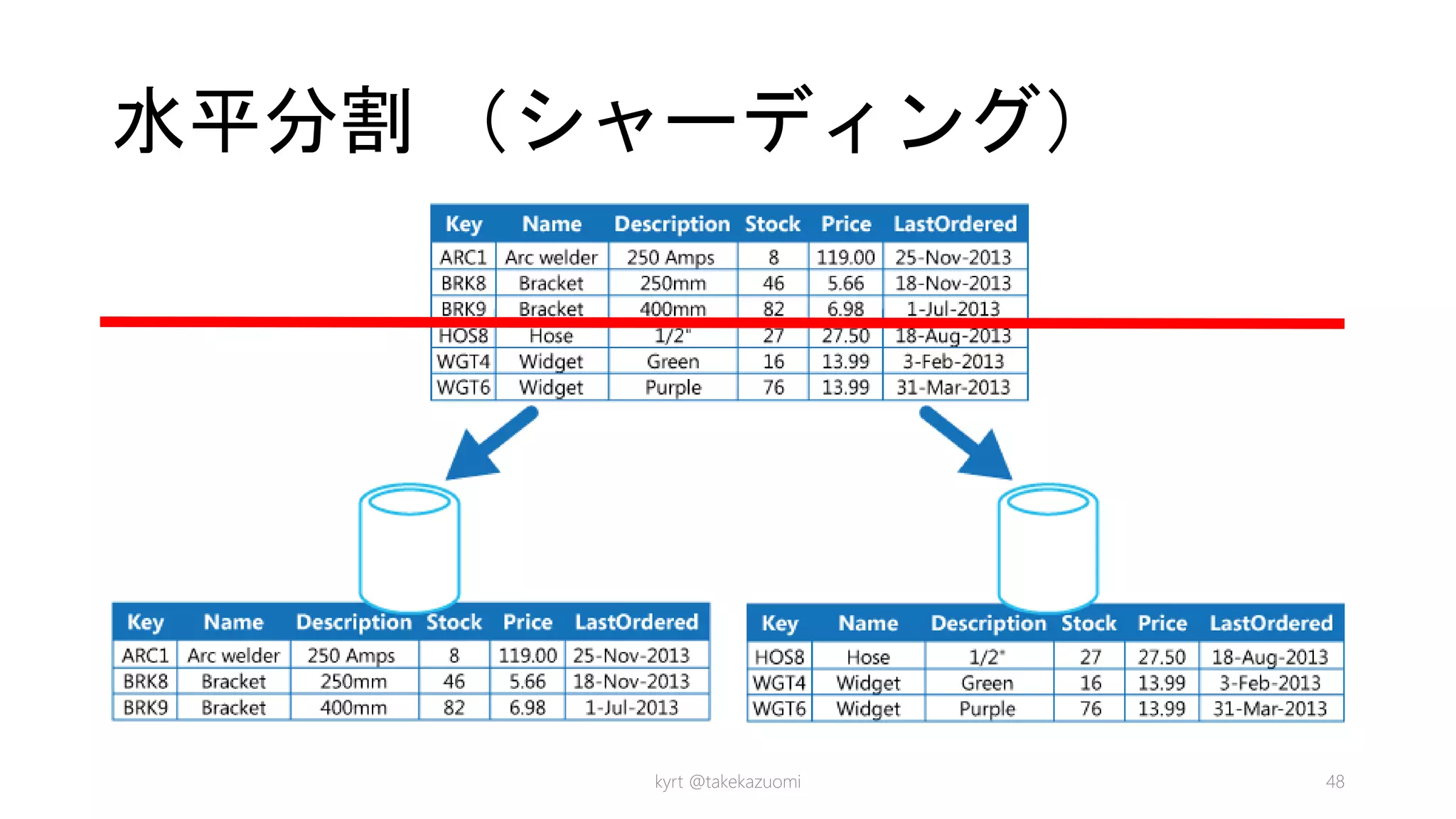
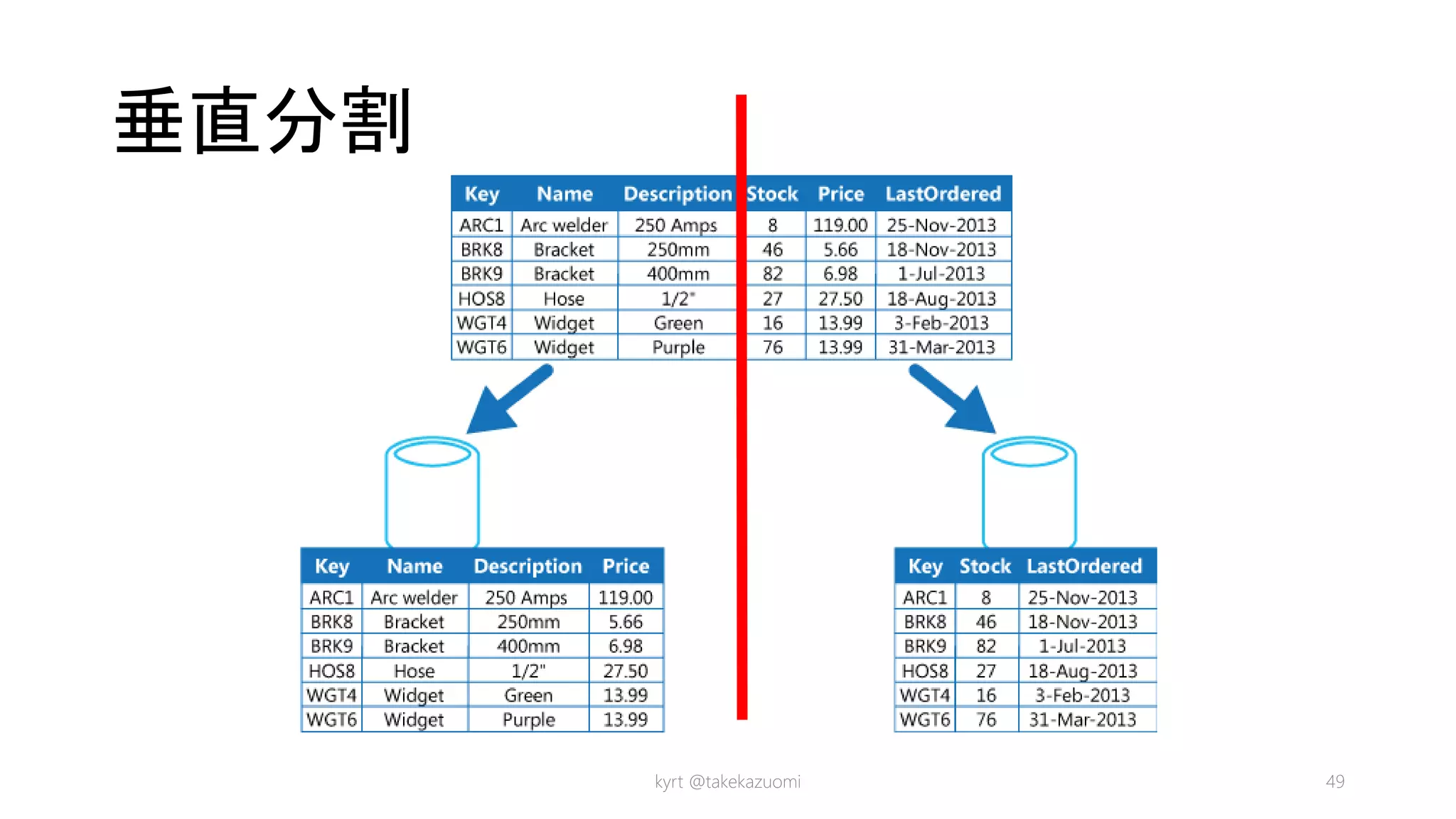
Data Partitioning Guidance ◯ ◯
Data Replication and Synchronization Guidance ◯ ◯
Instrumentation and Telemetry Guidance
Multiple Datacenter Deployment Guidance ◯
Service Metering Guidance
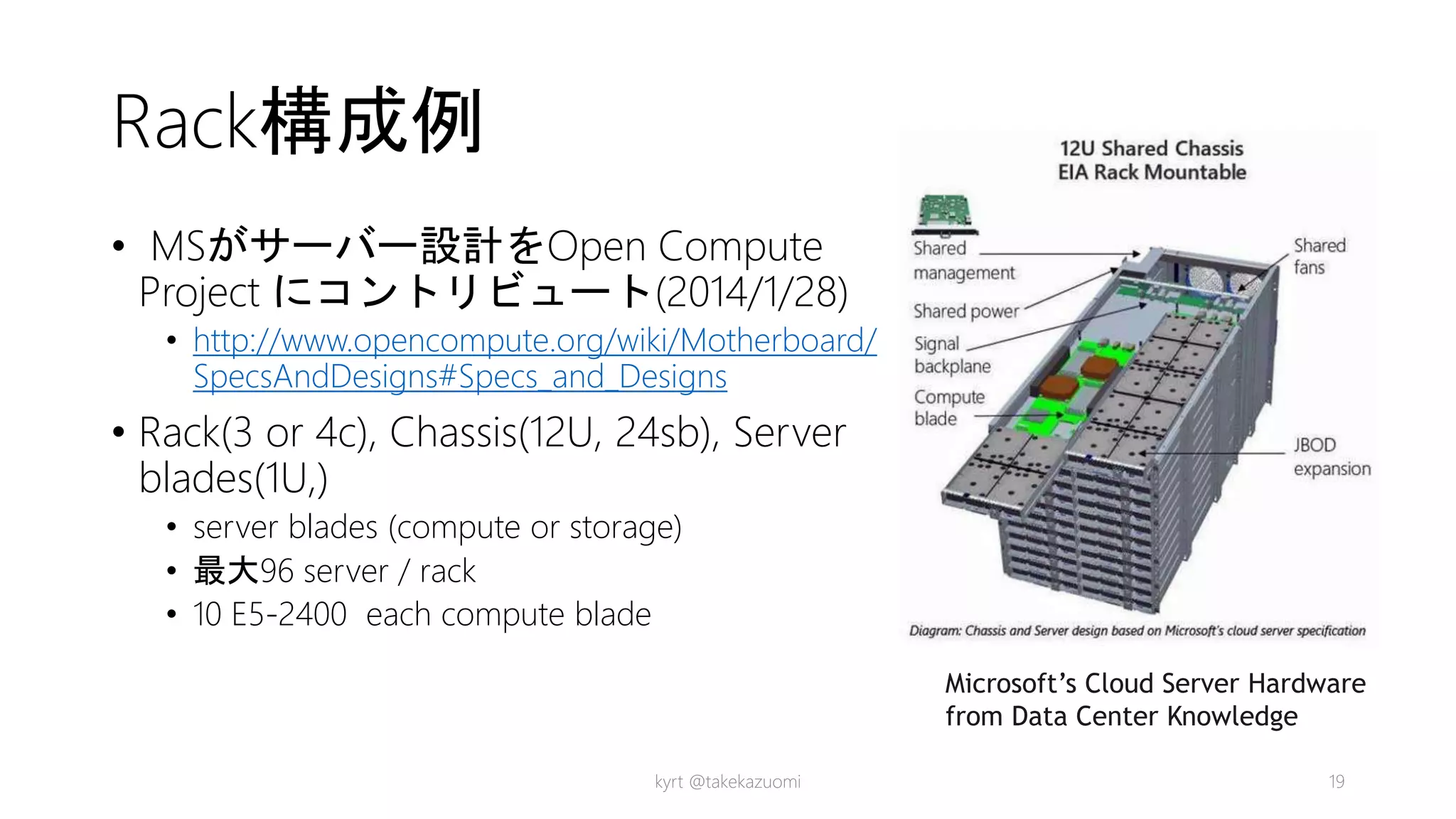
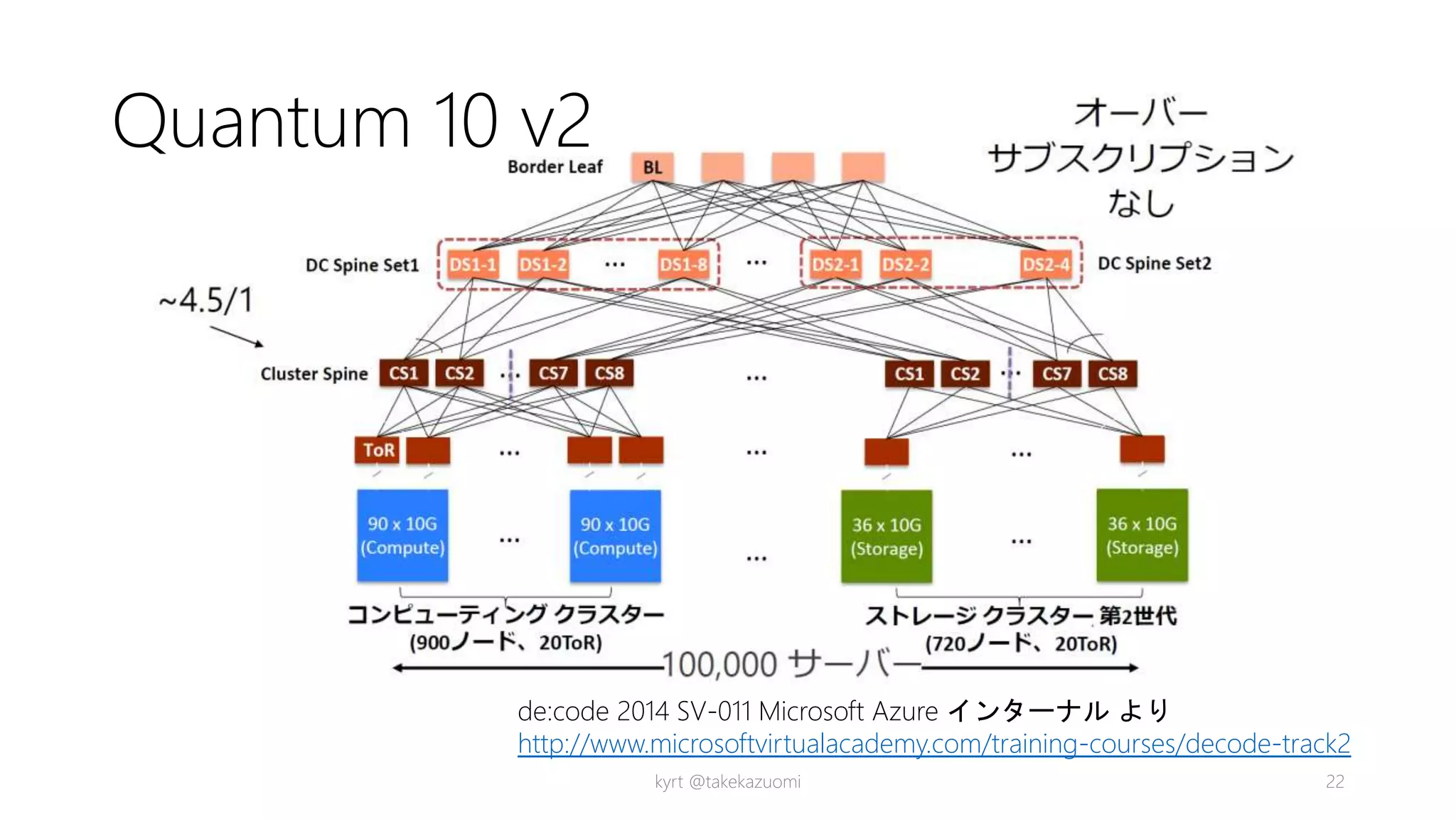
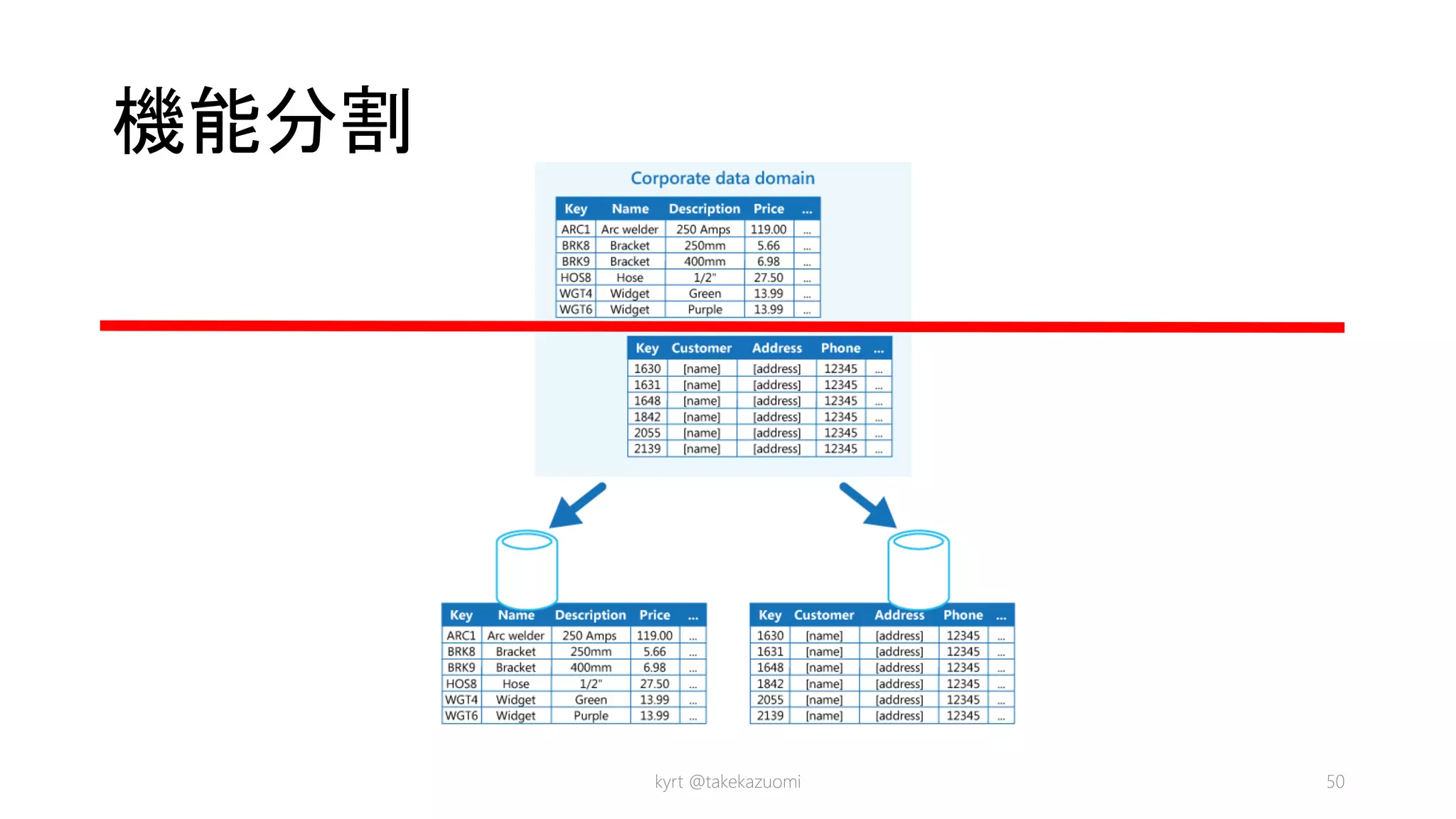
Rack構成例
• MSがサーバー設計をOpen Compute
Projectにコントリビュート(2014/1/28)
• http://www.opencompute.org/wiki/Motherboard/
SpecsAndDesigns#Specs_and_Designs
• Rack(3 or 4c), Chassis(12U, 24sb), Server
blades(1U,)
• server blades (compute or storage)
• 最大96 server / rack
• 10 E5-2400 each compute blade
kyrt @takekazuomi 19
Microsoft’s Cloud Server Hardware
from Data Center Knowledge






































































![[Azure Deep Dive] クラウド デザイン パターン ~優れたシステム構築のためのガイダンス~](https://cdn.slidesharecdn.com/ss_thumbnails/200151004madcdp-151216090016-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DO05] システムの信頼性を上げるための新しい考え方 SRE ( Site Reliability Engineering ) in Azure, o...](https://cdn.slidesharecdn.com/ss_thumbnails/do05-170616023431-thumbnail.jpg?width=640&height=640&fit=bounds)





![[G-Tech2014講演資料] Microsoft Azureで負荷分散された仮想マシンを作ってみよう ~Amazon Web Servicesと比べな...](https://cdn.slidesharecdn.com/ss_thumbnails/c-4microsoftazure-141020195818-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[修羅の街からこんにちわ♪JAZUG連動企画 by ふくあず] Windows Azureクラウド デザイン パターン](https://cdn.slidesharecdn.com/ss_thumbnails/20140308jazfukuokacdp-140308013605-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[AWS Summit 2012] クラウドデザインパターン#8 CDP アンチパターン編](https://cdn.slidesharecdn.com/ss_thumbnails/aws-summit-cdp-08-121001111025-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)















![[AWS Summit 2012] クラウドデザインパターン#5 CDP バッチ処理編](https://cdn.slidesharecdn.com/ss_thumbnails/aws-summit-cdp-05-121001104857-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[de:code 2018] [DA20] Azure データ サービスを使ったアーキテクチャ設計 ~ 「Azure データ アーキテクチャ ガイド」を中...](https://cdn.slidesharecdn.com/ss_thumbnails/20180523decode18da20adag-180528001534-thumbnail.jpg?width=640&height=640&fit=bounds)


![レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/attunityseminar20181206msnakagawa-181211014925-thumbnail.jpg?width=640&height=640&fit=bounds)





































