Downloaded 102 times














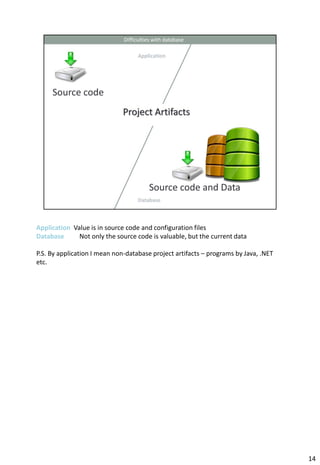
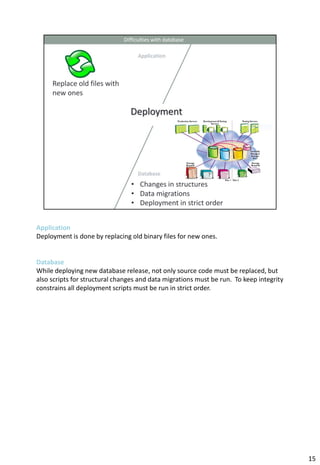















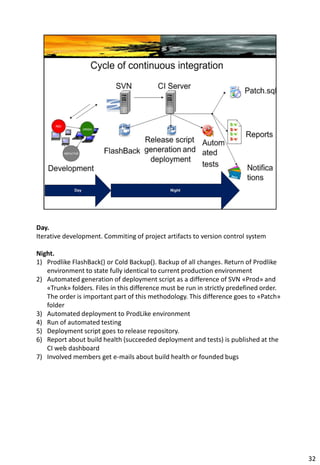
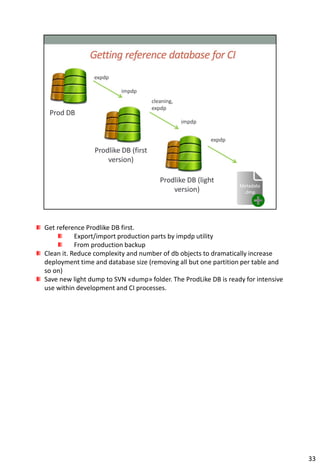




















The document provides information about continuous integration (CI) for database development projects. It discusses how version control, automated testing, and continuous deployment can be applied to database code and artifacts. Key points include: - Storing database scripts, structures, and data migrations in version control to allow for automated deployment and rollbacks. - Maintaining a "trunk" version that serves as the single source of truth for all changes. - Taking nightly backups of a production-like environment and deploying changes since the last build to test integration. - Generating deployment scripts by comparing the trunk to the current production version. - Running automated tests after each deployment to catch errors early.























































































