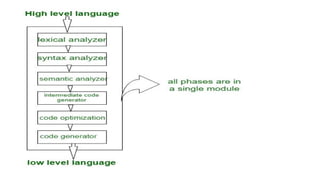
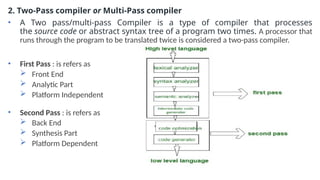
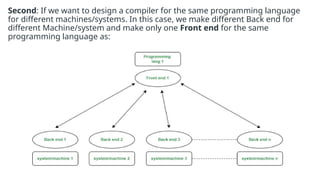
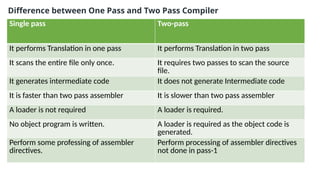
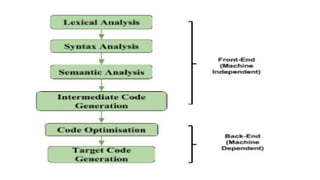
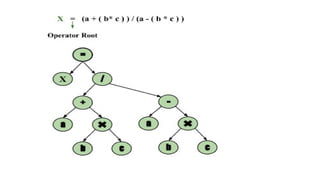
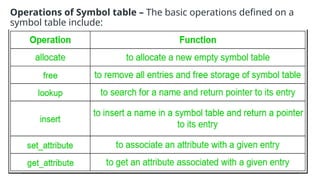
The document provides an overview of compiler construction, detailing the types of compiler passes, specifically single-pass and multi-pass compilers, including their functionalities, advantages, and disadvantages. It explores intermediate code generation, its benefits such as portability and optimization, as well as various representations of intermediate code like three-address code and syntax trees. Additionally, the document discusses the symbol table's role in a compiler, including its structure, operations, advantages, and applications in error checking and code generation.






















































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)







![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)






