Downloaded 277 times






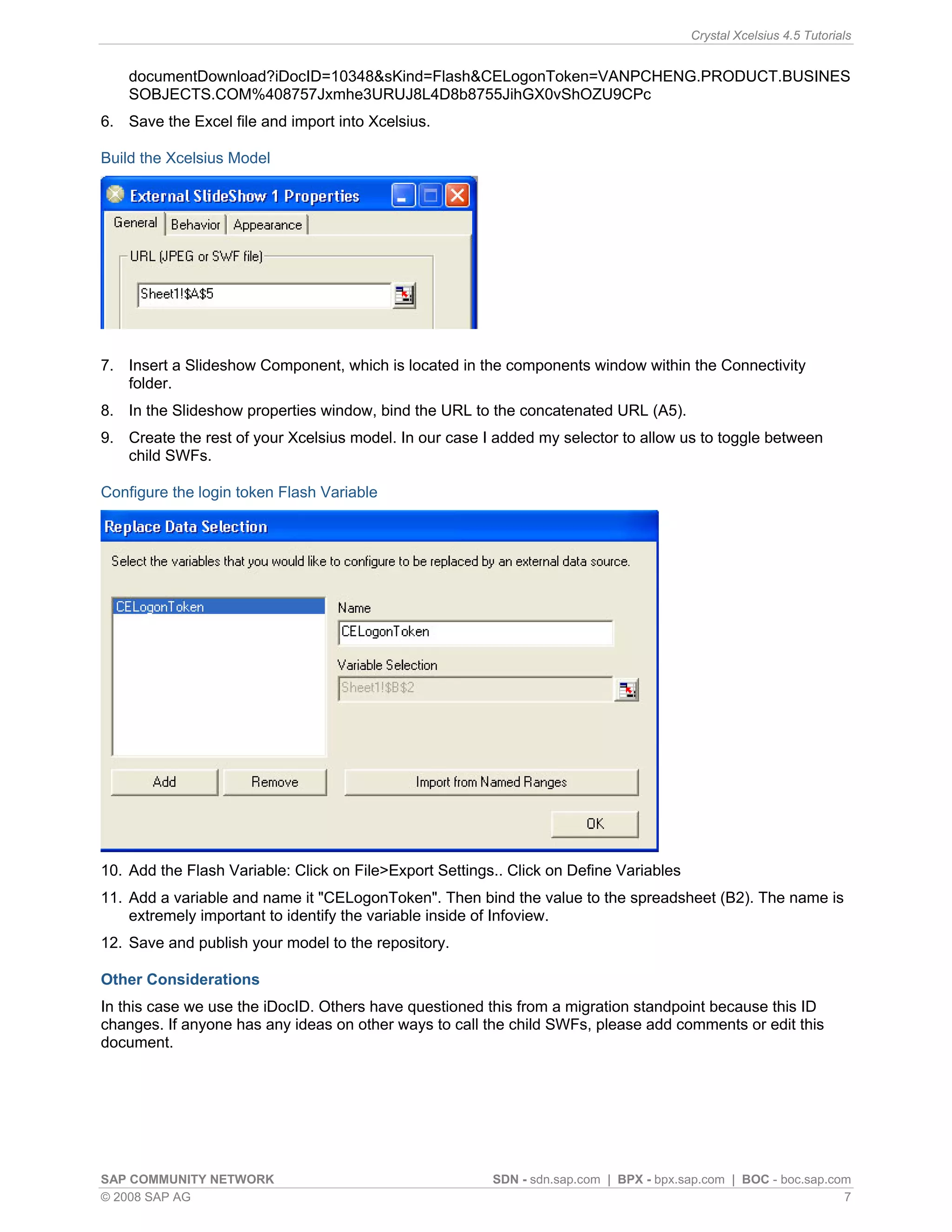
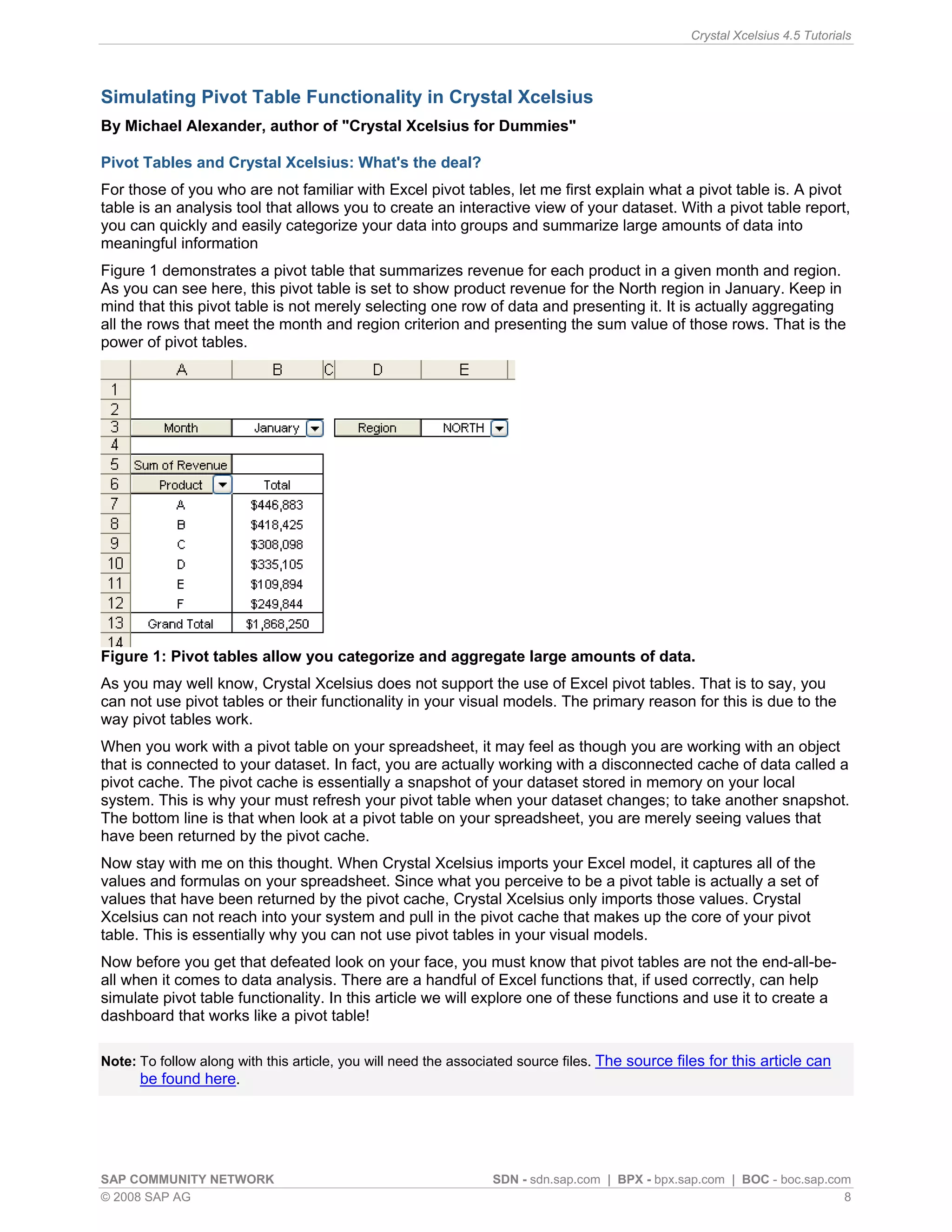

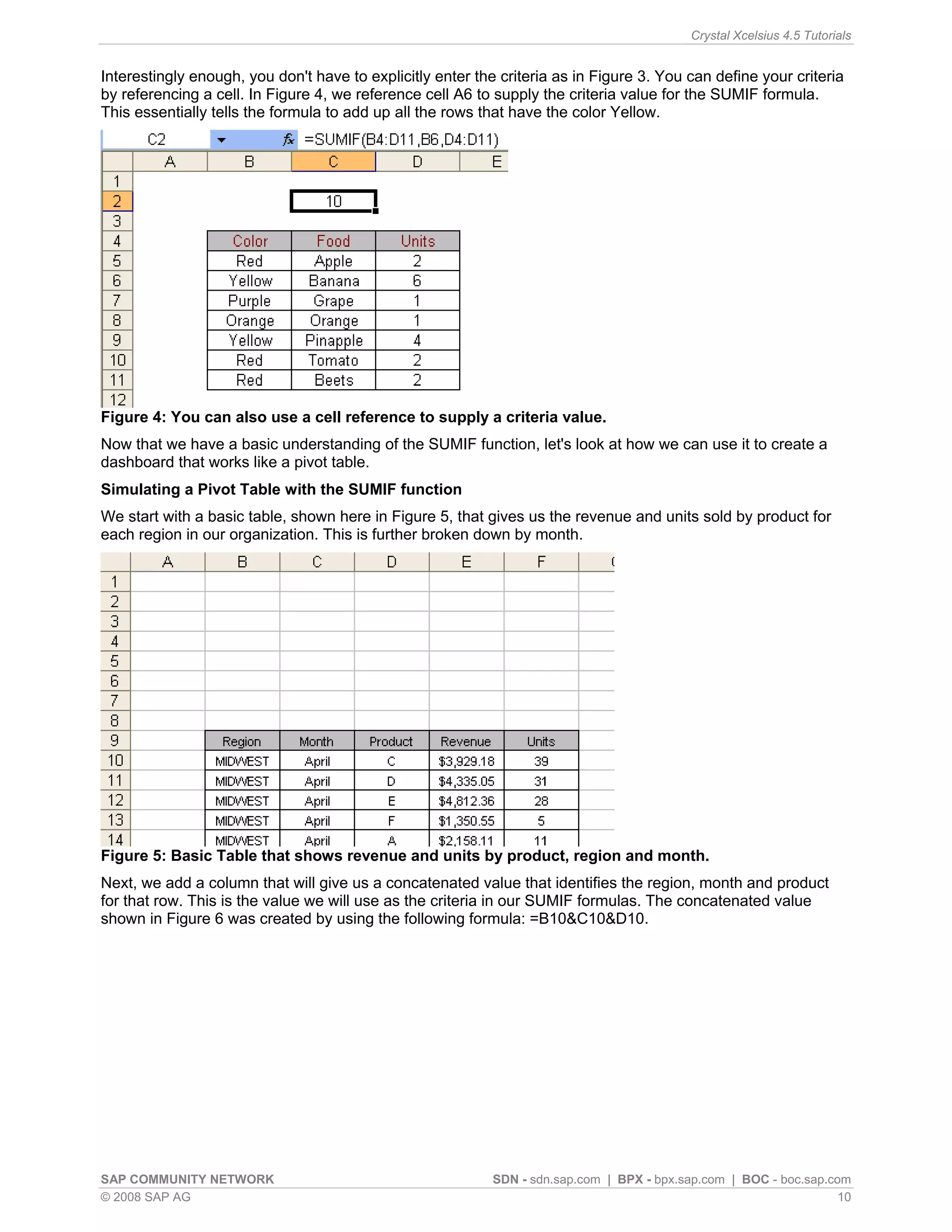
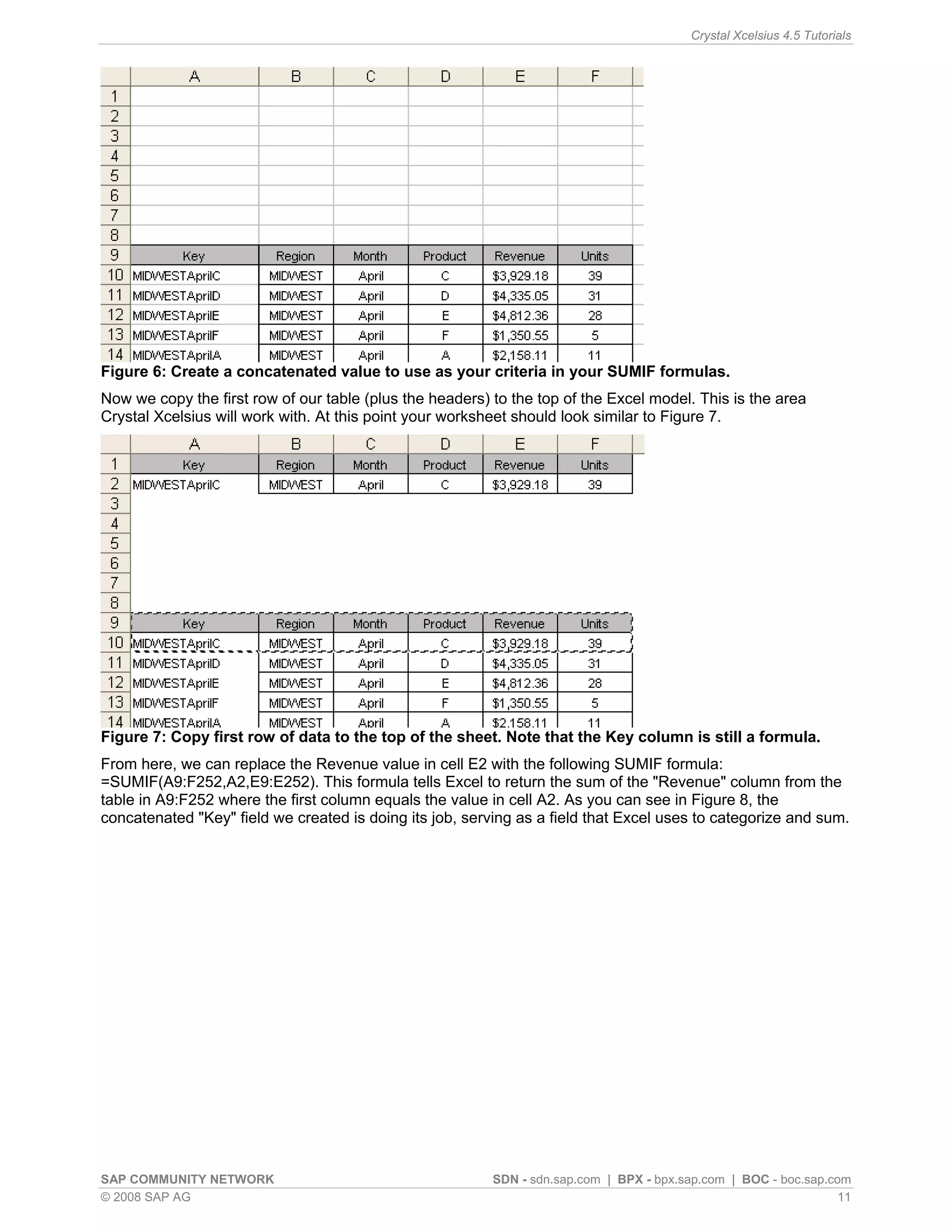
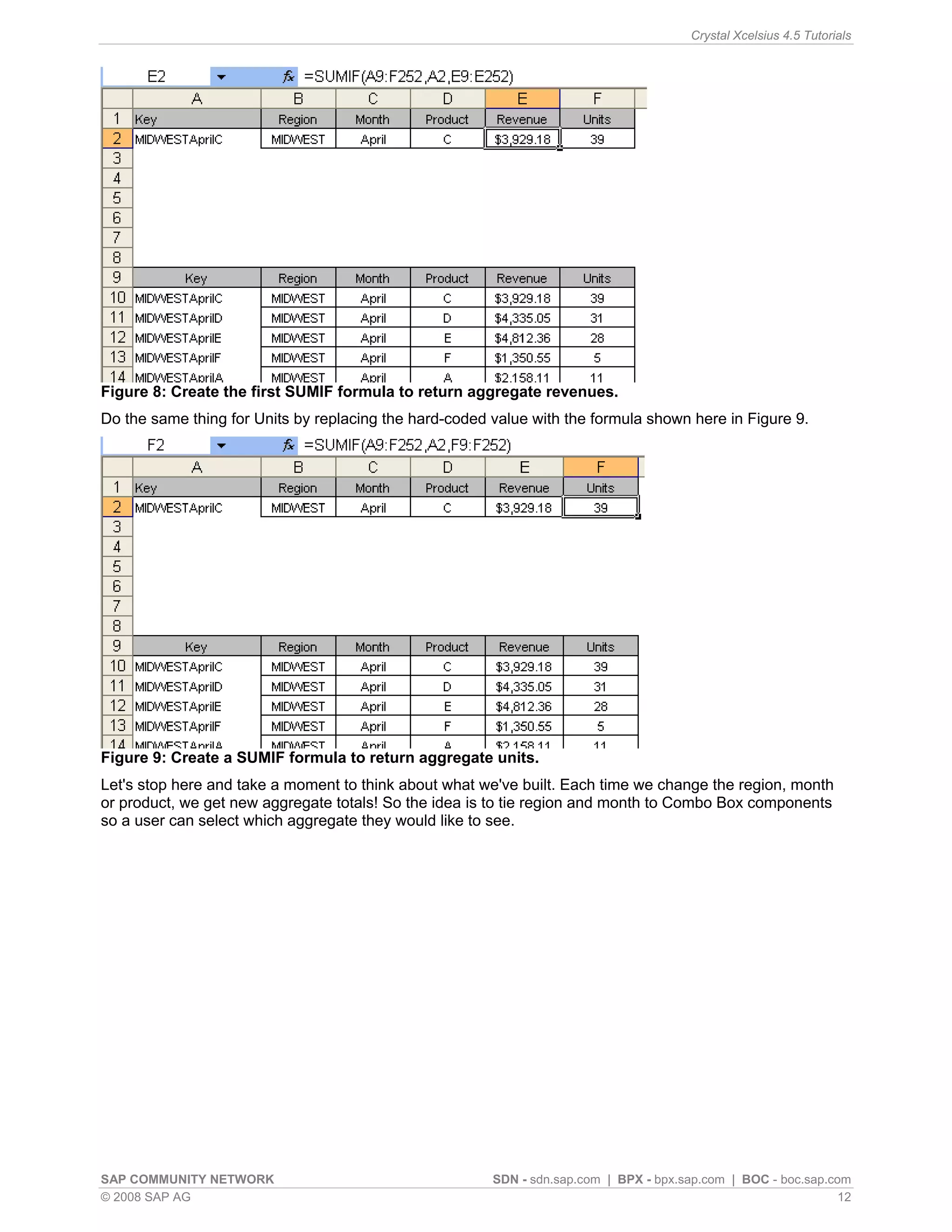
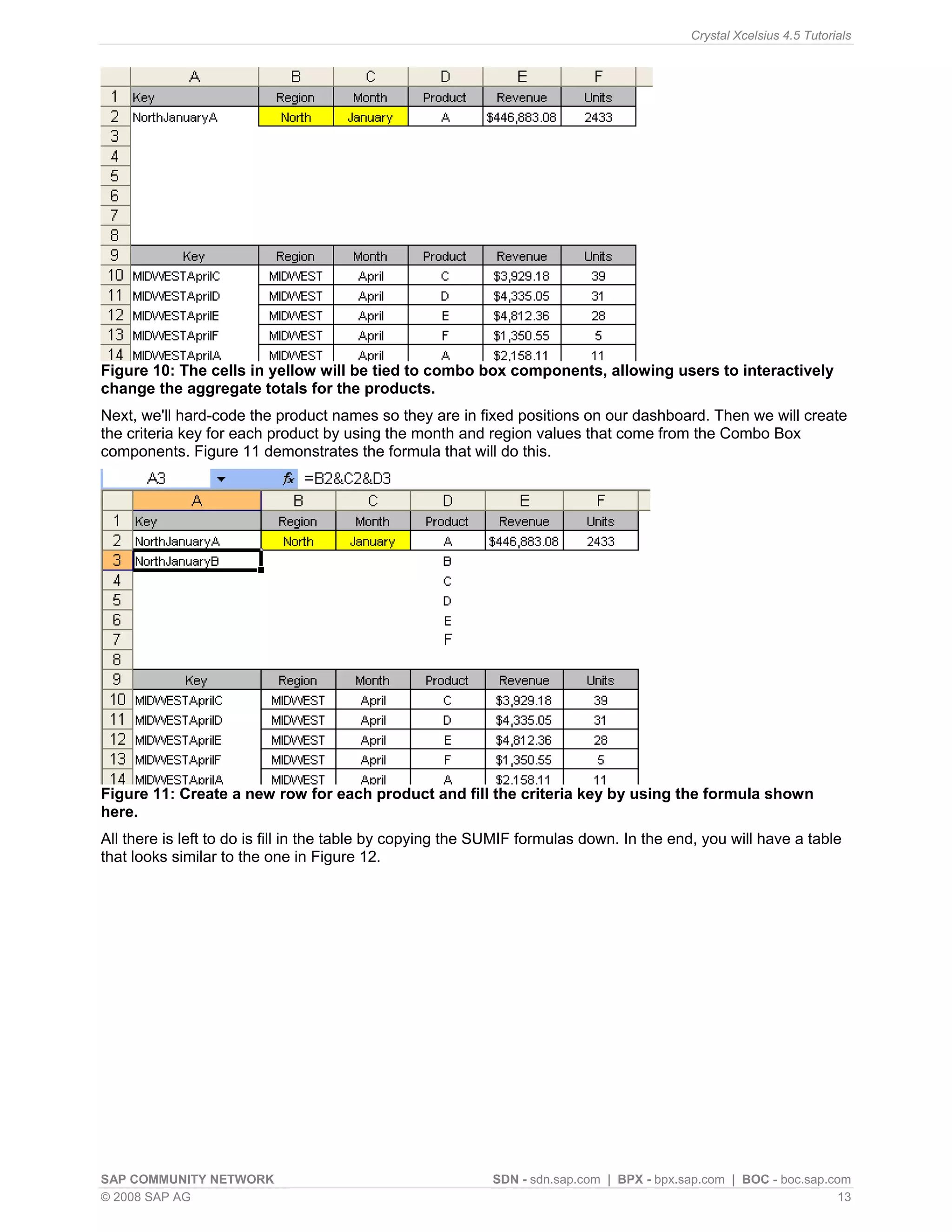
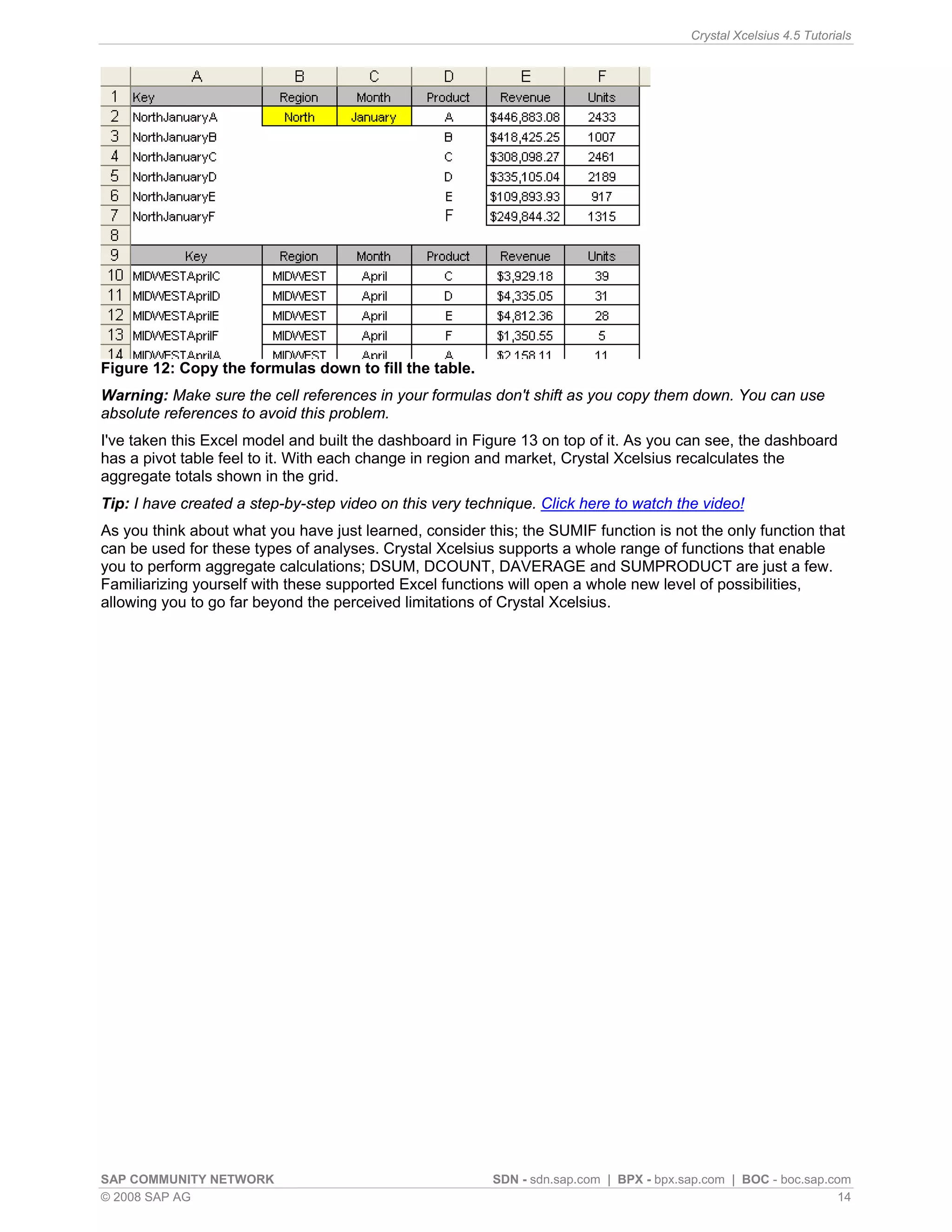


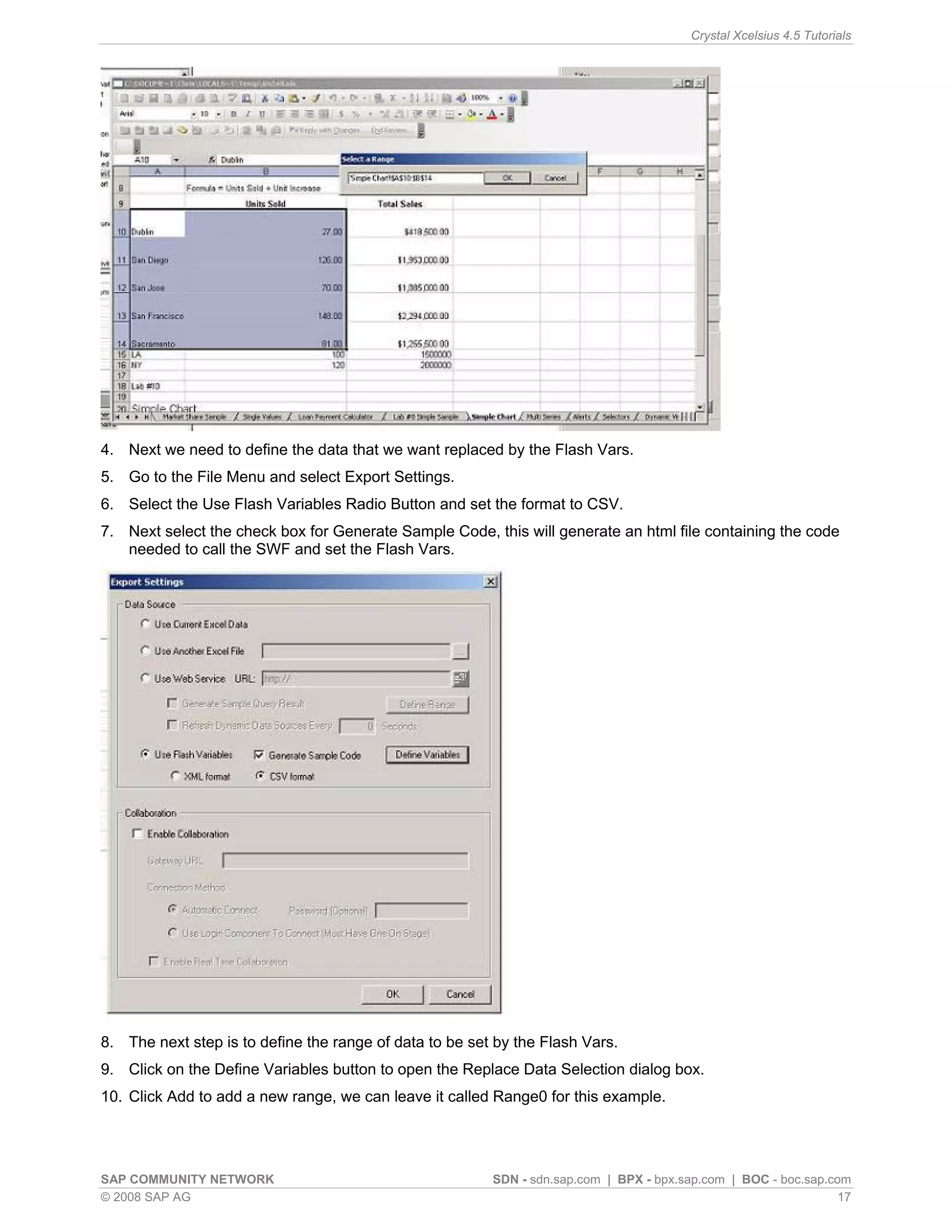















This article discusses simulating pivot table functionality in Crystal Xcelsius. Pivot tables allow categorizing and aggregating large amounts of data, but are not supported in Xcelsius models. The article explores using the SUMIF function to simulate pivot table functionality and create an interactive dashboard that aggregates data based on category selections, similar to how a pivot table works.














































