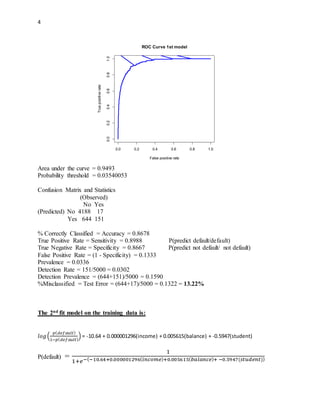
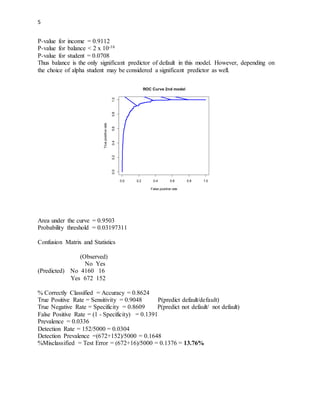
The document summarizes the analysis of a credit card default dataset to predict customer default status. A logistic regression model was created using income, balance, and student status as predictors. The model had good performance with an AUC of 0.9503, correctly classifying 86.24% of customers and reducing the default rate from 3.36% to 0.32% using a probability threshold of 0.03197311. Balance was the most significant predictor of default. The model provides a useful tool for credit card companies to identify high-risk customers.




![7
R Code and R OutPut:
>library(pROC)
>library(ROCR)
>library(mgcv)
>library(caret)
>library(e1071)
>library(ISLR)
> attach(Default)
> fix(Default)
> dim(Default)
[1] 10000 4
> ?Default
> summary(Default)
default student balance income
No :9667 No :7056 Min. : 0.0 Min. : 772
Yes: 333 Yes:2944 1st Qu.: 481.7 1st Qu.:21340
Median : 823.6 Median :34553
Mean : 835.4 Mean :33517
3rd Qu.:1166.3 3rd Qu.:43808
Max. :2654.3 Max. :73554
> #P(Default = Yes)
> 333/10000
[1] 0.0333
> #P(Default = No)
> 9667/10000
[1] 0.9667
> #Some Conditional Probabilities
> table(Default$default,Default$student)
No Yes
No 6850 2817
Yes 206 127
> #P(default = Yes given student = Yes)
> 127/(2817+127)
[1] 0.04313859
> #P(default = Yes given student = No)
> 206/(6850+206)
[1] 0.02919501
>#Box Plots
> par(mfrow=c(1,2))
> plot(default, balance, xlab="Default", ylab="Credit Card Balance", col="red")
> plot(default, income, xlab="Default", ylab="Income", col="green")
> par(mfrow=c(1,2))](https://image.slidesharecdn.com/adf6a9a5-51a9-43d0-b2cc-0611aa3369ae-150604170710-lva1-app6891/85/CreditCardDefaultModel-7-320.jpg)
![8
> plot(student,balance,xlab="Student Status",ylab="Credit Card Balance", col="red")
> plot(student,income,xlab="Student Status",ylab="Income", col="green")
> #Training and HoldOut Sets
> set.seed(23)
> ReSampleData = Default[sample(nrow(Default)),]
> Data.Set.Splits = cut(seq(1,nrow(ReSampleData)),breaks=2,labels=FALSE)
> tIndexes = which(Data.Set.Splits!=1,arr.ind=TRUE)
> Training.Set = ReSampleData[tIndexes, ]
> fix(Training.Set)
> HoldOut.Set = ReSampleData[-tIndexes,]
> fix(HoldOut.Set)
> #fit the 1st logistic regression on training data
> default.glm.training = glm(default~income + balance,
family=binomial(link="logit"),data=Training.Set)
> summary(default.glm.training)
Call:
glm(formula = default ~ income + balance, family = binomial(link = "logit"),
data = Training.Set)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.4201 -0.1489 -0.0604 -0.0231 3.6961
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.127e+01 6.000e-01 -18.778 <2e-16 ***
income 1.788e-05 7.088e-06 2.522 0.0117 *
balance 5.538e-03 3.162e-04 17.516 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1450.21 on 4999 degrees of freedom
Residual deviance: 797.18 on 4997 degrees of freedom
AIC: 803.18
Number of Fisher Scoring iterations: 8
> #predicts probabilities for holdout set values using the training set model
> HoldOut.Set$predict.default.glm.hold=predict(default.glm.training,
type="response",newdata=data.frame(HoldOut.Set))
> fix(HoldOut.Set)](https://image.slidesharecdn.com/adf6a9a5-51a9-43d0-b2cc-0611aa3369ae-150604170710-lva1-app6891/85/CreditCardDefaultModel-8-320.jpg)
![9
> # Plot the ROC curve
> perf.AUC.glm =
performance(prediction(HoldOut.Set$predict.default.glm.hold,HoldOut.Set$default),"tpr","fpr")
> par(mfrow=c(1,1))
> plot(perf.AUC.glm,col="blue",lwd=3,main="ROC Curve 1st model")
> # Estimate of AUC ROC
> ROC.glm.hold=roc(HoldOut.Set$default,HoldOut.Set$predict.default.glm.hold
,percent=FALSE,plot=FALSE,ci=TRUE)
> AUC.glm.hold=ROC.glm.hold$auc
> AUC.glm.hold.lb=ROC.glm.hold$ci[1]
> AUC.glm.hold.ub=ROC.glm.hold$ci[3]
> AUC.glm.hold
Area under the curve: 0.9493
> AUC.glm.hold.lb
[1] 0.935706
> AUC.glm.hold.ub
[1] 0.9629286
> #Probability Threshold
> thresh.glm.hold.youden=coords(ROC.glm.hold, x="best", input="threshold",
best.method="youden")
> thresh.glm.hold=thresh.glm.hold.youden[1]
> specif.glm.hold=thresh.glm.hold.youden[2]
> sensit.glm.hold=thresh.glm.hold.youden[3]
> thresh.glm.hold
threshold
0.03540053
> specif.glm.hold
specificity
0.8667219
> sensit.glm.hold
sensitivity
0.8988095
> #Confusion Matrix and Statistics
> glm.pred.hold=rep("No",nrow(HoldOut.Set))
> glm.pred.hold[HoldOut.Set$predict.default.glm.hold>thresh.glm.hold]="Yes"
> xtab.glm.hold=table(glm.pred.hold,HoldOut.Set$default)
> xtab.glm.hold
glm.pred.hold No Yes
No 4188 17
Yes 644 151
> confusionMatrix(xtab.glm.hold,positive="Yes")
Confusion Matrix and Statistics
glm.pred.hold No Yes
No 4188 17
Yes 644 151](https://image.slidesharecdn.com/adf6a9a5-51a9-43d0-b2cc-0611aa3369ae-150604170710-lva1-app6891/85/CreditCardDefaultModel-9-320.jpg)
![10
Accuracy : 0.8678
95% CI : (0.8581, 0.8771)
No Information Rate : 0.9664
P-Value [Acc > NIR] : 1
Kappa : 0.2733
Mcnemar's Test P-Value : <2e-16
Sensitivity : 0.8988
Specificity : 0.8667
Pos Pred Value : 0.1899
Neg Pred Value : 0.9960
Prevalence : 0.0336
Detection Rate : 0.0302
Detection Prevalence : 0.1590
Balanced Accuracy : 0.8828
'Positive' Class : Yes
> #fit the 2nd logistic regression on training data
> default.glm.training2 = glm(default~balance+income+student,
family=binomial(link="logit"),data=Training.Set)
> summary(default.glm.training2)
Call:
glm(formula = default ~ balance + income + student, family = binomial(link = "logit"),
data = Training.Set)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.4127 -0.1455 -0.0595 -0.0226 3.7186
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.064e+01 6.846e-01 -15.536 <2e-16 ***
balance 5.615e-03 3.213e-04 17.476 <2e-16 ***
income 1.296e-06 1.161e-05 0.112 0.9112
studentYes -5.947e-01 3.292e-01 -1.807 0.0708 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1450.21 on 4999 degrees of freedom
Residual deviance: 793.95 on 4996 degrees of freedom](https://image.slidesharecdn.com/adf6a9a5-51a9-43d0-b2cc-0611aa3369ae-150604170710-lva1-app6891/85/CreditCardDefaultModel-10-320.jpg)
![11
AIC: 801.95
Number of Fisher Scoring iterations: 8
> #predicts probabilities for holdout set values using the training set model
> HoldOut.Set$predict.default.glm.hold2=predict(default.glm.training2,
type="response",newdata=data.frame(HoldOut.Set))
> fix(HoldOut.Set)
> # Plot the ROC curve
> perf.AUC.glm2 =
performance(prediction(HoldOut.Set$predict.default.glm.hold2,HoldOut.Set$default),"tpr","fpr"
)
> par(mfrow=c(1,1))
> plot(perf.AUC.glm2,col="blue",lwd=3,main="ROC Curve 2nd model")
> #Estimate of AUC ROC
> ROC.glm.hold2=roc(HoldOut.Set$default,HoldOut.Set$predict.default.glm.hold2
,percent=FALSE,plot=FALSE,ci=TRUE)
> AUC.glm.hold2=ROC.glm.hold2$auc
> AUC.glm.hold2.lb=ROC.glm.hold2$ci[1]
> AUC.glm.hold2.ub=ROC.glm.hold2$ci[3]
> AUC.glm.hold2
Area under the curve: 0.9503
> AUC.glm.hold2.lb
[1] 0.9369902
> AUC.glm.hold2.ub
[1] 0.9635711
> #Probability Threshold
> thresh.glm.hold2.youden=coords(ROC.glm.hold2, x="best", input="threshold",
best.method="youden")
> thresh.glm.hold2=thresh.glm.hold2.youden[1]
> specif.glm.hold2=thresh.glm.hold2.youden[2]
> sensit.glm.hold2=thresh.glm.hold2.youden[3]
> thresh.glm.hold2
threshold
0.03197311
> specif.glm.hold2
specificity
0.8609272
> sensit.glm.hold2
sensitivity
0.9047619
> #Confusion Matrix and Statistics
> glm.pred.hold2=rep("No",nrow(HoldOut.Set))
> glm.pred.hold2[HoldOut.Set$predict.default.glm.hold2>thresh.glm.hold2]="Yes"
> xtab.glm.hold2=table(glm.pred.hold2,HoldOut.Set$default)](https://image.slidesharecdn.com/adf6a9a5-51a9-43d0-b2cc-0611aa3369ae-150604170710-lva1-app6891/85/CreditCardDefaultModel-11-320.jpg)
![12
> xtab.glm.hold2
glm.pred.hold2 No Yes
No 4160 16
Yes 672 152
> confusionMatrix(xtab.glm.hold2,positive="Yes")
Confusion Matrix and Statistics
glm.pred.hold2 No Yes
No 4160 16
Yes 672 152
Accuracy : 0.8624
95% CI : (0.8525, 0.8718)
No Information Rate : 0.9664
P-Value [Acc > NIR] : 1
Kappa : 0.2654
Mcnemar's Test P-Value : <2e-16
Sensitivity : 0.9048
Specificity : 0.8609
Pos Pred Value : 0.1845
Neg Pred Value : 0.9962
Prevalence : 0.0336
Detection Rate : 0.0304
Detection Prevalence : 0.1648
Balanced Accuracy : 0.8828
'Positive' Class : Yes](https://image.slidesharecdn.com/adf6a9a5-51a9-43d0-b2cc-0611aa3369ae-150604170710-lva1-app6891/85/CreditCardDefaultModel-12-320.jpg)





























































