Couchbase Server is a distributed, open source NoSQL database engine that simplifies building modern applications. It provides a flexible data model and high availability, scalability, performance, and security. The core architecture includes components like connectivity, replication, storage, caching and security architectures. It also includes services like the cluster manager, data service, index service, query service and search service. Nodes in a cluster communicate to replicate data, maintain indexes and monitor health. Clients connect to clusters through APIs to perform data operations with low latency and high throughput.
This report describes how the Aucfanlab team used Azure’s Data Factory service to
implement the orchestration and monitoring of all data pipelines for our “Aucfan
Datalake” project.
This presentation explains why NoSQL databases came over SQL databases although SQL databases has been successfully technology for more than twenty years. Moreover, This presentation discuses the characteristics and classifications of NoSQL databases. Finally, These slides cover four NoSQL databases briefly.
This report describes how the Aucfanlab team used Azure’s Data Factory service to
implement the orchestration and monitoring of all data pipelines for our “Aucfan
Datalake” project.
This presentation explains why NoSQL databases came over SQL databases although SQL databases has been successfully technology for more than twenty years. Moreover, This presentation discuses the characteristics and classifications of NoSQL databases. Finally, These slides cover four NoSQL databases briefly.
In recent years, we have seen an overwhelming number of TV commercials that promise that the Cloud can help with many problems, including some family issues. What stands behind the terms “Cloud” and “Cloud Computing,” and what we can actually expect from this phenomenon? A group of students of the Computer Systems Technology department and Dr. T. Malyuta, whom has been working with the Cloud technologies since its early days, will provide an overview of the business and technological aspects of the Cloud.
Quantopix Analytics System (QAS) is a platform for data analysis and for developing analytics apps. QAS connects to most of Enterprise Class SQL Database Managers and provides instant capabilities to build datasets and data groups from disjointed databases to prepare it for analysis. QAS provides a comprehensive and extensible set of statistical functions to instantly profile your data. It comes with advanced yet easy to invoke charting capabilities for interactively visualizing the data as well as generating static chart images. QAS comes with a built-in PHP and JavaScript App builder to help users extend the system functions and create custom applications for specific business needs.
Rapid App Development
QAS lets you build analysis Apps within minutes using a powerful set of APIs for data manipulation including time-series and text classifications. QAS includes a comprehensive list of math, statistics, and matrix manipulation functions for numeric analysis. The APIs include Multiple Linear Regression model generation, k-means clustering model generation, and a Predict API for both models.
Design and Implementation of SOA Enhanced Semantic Information Retrieval web ...iosrjce
IOSR Journal of Computer Engineering (IOSR-JCE) is a double blind peer reviewed International Journal that provides rapid publication (within a month) of articles in all areas of computer engineering and its applications. The journal welcomes publications of high quality papers on theoretical developments and practical applications in computer technology. Original research papers, state-of-the-art reviews, and high quality technical notes are invited for publications.
Survey of SQL Azure, SQL Azure Data Sync, SQL Azure OData Feeds, SQL Azure Data Migration Wizard, Roadmap, and PowerPivot Integration. Given on Day of Azure 2, Dec 4th, 2010. Presented by Ike Ellis & Lynn Langit
In recent years, we have seen an overwhelming number of TV commercials that promise that the Cloud can help with many problems, including some family issues. What stands behind the terms “Cloud” and “Cloud Computing,” and what we can actually expect from this phenomenon? A group of students of the Computer Systems Technology department and Dr. T. Malyuta, whom has been working with the Cloud technologies since its early days, will provide an overview of the business and technological aspects of the Cloud.
Quantopix Analytics System (QAS) is a platform for data analysis and for developing analytics apps. QAS connects to most of Enterprise Class SQL Database Managers and provides instant capabilities to build datasets and data groups from disjointed databases to prepare it for analysis. QAS provides a comprehensive and extensible set of statistical functions to instantly profile your data. It comes with advanced yet easy to invoke charting capabilities for interactively visualizing the data as well as generating static chart images. QAS comes with a built-in PHP and JavaScript App builder to help users extend the system functions and create custom applications for specific business needs.
Rapid App Development
QAS lets you build analysis Apps within minutes using a powerful set of APIs for data manipulation including time-series and text classifications. QAS includes a comprehensive list of math, statistics, and matrix manipulation functions for numeric analysis. The APIs include Multiple Linear Regression model generation, k-means clustering model generation, and a Predict API for both models.
Design and Implementation of SOA Enhanced Semantic Information Retrieval web ...iosrjce
IOSR Journal of Computer Engineering (IOSR-JCE) is a double blind peer reviewed International Journal that provides rapid publication (within a month) of articles in all areas of computer engineering and its applications. The journal welcomes publications of high quality papers on theoretical developments and practical applications in computer technology. Original research papers, state-of-the-art reviews, and high quality technical notes are invited for publications.
Survey of SQL Azure, SQL Azure Data Sync, SQL Azure OData Feeds, SQL Azure Data Migration Wizard, Roadmap, and PowerPivot Integration. Given on Day of Azure 2, Dec 4th, 2010. Presented by Ike Ellis & Lynn Langit
Couchbase Server is a high-performance NoSQL distributed database with a flexible data model. It scales on commodity hardware to support large data sets with a high number of concurrent reads and writes while maintaining low latency and strong consistency.
A brief presentation outlining the basics of elasticsearch for beginners. Can be used to deliver a seminar on elasticsearch.(P.S. I used it) Would Recommend the presenter to fiddle with elasticsearch beforehand.
Big Data Day LA 2016/ NoSQL track - Spark And Couchbase: Augmenting The Opera...Data Con LA
For an operational database, Spark is like Batman’s utility belt: it handles a variety of important tasks from data cleanup and migration to analytics and machine learning that make the operational database much more powerful than it would be on its own. In this talk, we describe the Couchbase Spark Connector that lets you easily integrate Spark with Couchbase Server, an open source distributed NoSQL document database that provides low latency data management for large scale, interactive online applications. We’ll start with common use cases for Spark and Couchbase, then cover the basics of creating, persisting and consume RDDs and DataFrames from Couchbase’s key/value and SQL interfaces.
Spark and Couchbase– Augmenting the Operational Database with SparkMatt Ingenthron
How do NoSQL Document-Oriented Databases like Couchbase fit in with Apache Spark? This set of slides gives a couple of use cases, shows why Couchbase works great with Spark, and sets up a scenario for a demo.
Deep Dive on ElasticSearch Meetup event on 23rd May '15 at www.meetup.com/abctalks
Agenda:
1) Introduction to NOSQL
2) What is ElasticSearch and why is it required
3) ElasticSearch architecture
4) Installation of ElasticSearch
5) Hands on session on ElasticSearch
IEEE 2015 - 2016 | Combining Efficiency, Fidelity, and Flexibility in Resource...1crore projects
1 CRORE PROJECTS
chennai | kumbakonam
offers (2015-2016) M.E, BE, M. Tech, B. Tech, PhD, MCA, BCA, MSC & MBA projects and also a real time application projects.
Final Year Projects for BE, B. Tech - ECE, EEE, CSE, IT, MCA, ME, M. Tech, M SC (IT), BCA, BSC and MBA.
Project support:-
1.Abstract, Diagrams, Review Details, Relevant Materials, Presentation,
2.Supporting Documents, Software E-Books,
3.Software Development Standards & Procedure
4.E-Book, Theory Classes, Lab Working programs, Project design & Implementation
online support :
For other districts and states
1.we will help in skype and teamviewer support for project
For further details feel free to call us:
1 CRORE PROJECTS ,Door No: 214/215,2nd Floor, No. 172, Raahat Plaza, (Shopping Mall), Arcot Road, Vadapalani, Chennai,
Tamin Nadu, INDIA - 600 026.
Email id: 1croreprojects@gmail.com
website:1croreprojects.com
Phone : +91 97518 00789 / +91 72999 51536 / +91 77081 50152
Understand KUSTO Engine (ADX Pro and Cons, Query Processing and Concurrency)
How to use ADX to Kusto-mize data pipeline (Trigger2fill & Rewrite Patterns)
The real role of the Data Engineer (CD/CI for the Data Engineer, Git-ize Kusto statements, External Data integration)
This slide deck talks about Elasticsearch and its features.
When you talk about ELK stack it just means you are talking
about Elasticsearch, Logstash, and Kibana. But when you talk
about Elastic stack, other components such as Beats, X-Pack
are also included with it.
what is the ELK Stack?
ELK vs Elastic stack
What is Elasticsearch used for?
How does Elasticsearch work?
What is an Elasticsearch index?
Shards
Replicas
Nodes
Clusters
What programming languages does Elasticsearch support?
Amazon Elasticsearch, its use cases and benefits
GDG Cloud Southlake #33: Boule & Rebala: Effective AppSec in SDLC using Deplo...James Anderson
Effective Application Security in Software Delivery lifecycle using Deployment Firewall and DBOM
The modern software delivery process (or the CI/CD process) includes many tools, distributed teams, open-source code, and cloud platforms. Constant focus on speed to release software to market, along with the traditional slow and manual security checks has caused gaps in continuous security as an important piece in the software supply chain. Today organizations feel more susceptible to external and internal cyber threats due to the vast attack surface in their applications supply chain and the lack of end-to-end governance and risk management.
The software team must secure its software delivery process to avoid vulnerability and security breaches. This needs to be achieved with existing tool chains and without extensive rework of the delivery processes. This talk will present strategies and techniques for providing visibility into the true risk of the existing vulnerabilities, preventing the introduction of security issues in the software, resolving vulnerabilities in production environments quickly, and capturing the deployment bill of materials (DBOM).
Speakers:
Bob Boule
Robert Boule is a technology enthusiast with PASSION for technology and making things work along with a knack for helping others understand how things work. He comes with around 20 years of solution engineering experience in application security, software continuous delivery, and SaaS platforms. He is known for his dynamic presentations in CI/CD and application security integrated in software delivery lifecycle.
Gopinath Rebala
Gopinath Rebala is the CTO of OpsMx, where he has overall responsibility for the machine learning and data processing architectures for Secure Software Delivery. Gopi also has a strong connection with our customers, leading design and architecture for strategic implementations. Gopi is a frequent speaker and well-known leader in continuous delivery and integrating security into software delivery.
Dev Dives: Train smarter, not harder – active learning and UiPath LLMs for do...UiPathCommunity
💥 Speed, accuracy, and scaling – discover the superpowers of GenAI in action with UiPath Document Understanding and Communications Mining™:
See how to accelerate model training and optimize model performance with active learning
Learn about the latest enhancements to out-of-the-box document processing – with little to no training required
Get an exclusive demo of the new family of UiPath LLMs – GenAI models specialized for processing different types of documents and messages
This is a hands-on session specifically designed for automation developers and AI enthusiasts seeking to enhance their knowledge in leveraging the latest intelligent document processing capabilities offered by UiPath.
Speakers:
👨🏫 Andras Palfi, Senior Product Manager, UiPath
👩🏫 Lenka Dulovicova, Product Program Manager, UiPath
LF Energy Webinar: Electrical Grid Modelling and Simulation Through PowSyBl -...DanBrown980551
Do you want to learn how to model and simulate an electrical network from scratch in under an hour?
Then welcome to this PowSyBl workshop, hosted by Rte, the French Transmission System Operator (TSO)!
During the webinar, you will discover the PowSyBl ecosystem as well as handle and study an electrical network through an interactive Python notebook.
PowSyBl is an open source project hosted by LF Energy, which offers a comprehensive set of features for electrical grid modelling and simulation. Among other advanced features, PowSyBl provides:
- A fully editable and extendable library for grid component modelling;
- Visualization tools to display your network;
- Grid simulation tools, such as power flows, security analyses (with or without remedial actions) and sensitivity analyses;
The framework is mostly written in Java, with a Python binding so that Python developers can access PowSyBl functionalities as well.
What you will learn during the webinar:
- For beginners: discover PowSyBl's functionalities through a quick general presentation and the notebook, without needing any expert coding skills;
- For advanced developers: master the skills to efficiently apply PowSyBl functionalities to your real-world scenarios.
UiPath Test Automation using UiPath Test Suite series, part 3DianaGray10
Welcome to UiPath Test Automation using UiPath Test Suite series part 3. In this session, we will cover desktop automation along with UI automation.
Topics covered:
UI automation Introduction,
UI automation Sample
Desktop automation flow
Pradeep Chinnala, Senior Consultant Automation Developer @WonderBotz and UiPath MVP
Deepak Rai, Automation Practice Lead, Boundaryless Group and UiPath MVP
Essentials of Automations: Optimizing FME Workflows with ParametersSafe Software
Are you looking to streamline your workflows and boost your projects’ efficiency? Do you find yourself searching for ways to add flexibility and control over your FME workflows? If so, you’re in the right place.
Join us for an insightful dive into the world of FME parameters, a critical element in optimizing workflow efficiency. This webinar marks the beginning of our three-part “Essentials of Automation” series. This first webinar is designed to equip you with the knowledge and skills to utilize parameters effectively: enhancing the flexibility, maintainability, and user control of your FME projects.
Here’s what you’ll gain:
- Essentials of FME Parameters: Understand the pivotal role of parameters, including Reader/Writer, Transformer, User, and FME Flow categories. Discover how they are the key to unlocking automation and optimization within your workflows.
- Practical Applications in FME Form: Delve into key user parameter types including choice, connections, and file URLs. Allow users to control how a workflow runs, making your workflows more reusable. Learn to import values and deliver the best user experience for your workflows while enhancing accuracy.
- Optimization Strategies in FME Flow: Explore the creation and strategic deployment of parameters in FME Flow, including the use of deployment and geometry parameters, to maximize workflow efficiency.
- Pro Tips for Success: Gain insights on parameterizing connections and leveraging new features like Conditional Visibility for clarity and simplicity.
We’ll wrap up with a glimpse into future webinars, followed by a Q&A session to address your specific questions surrounding this topic.
Don’t miss this opportunity to elevate your FME expertise and drive your projects to new heights of efficiency.
Slack (or Teams) Automation for Bonterra Impact Management (fka Social Soluti...Jeffrey Haguewood
Sidekick Solutions uses Bonterra Impact Management (fka Social Solutions Apricot) and automation solutions to integrate data for business workflows.
We believe integration and automation are essential to user experience and the promise of efficient work through technology. Automation is the critical ingredient to realizing that full vision. We develop integration products and services for Bonterra Case Management software to support the deployment of automations for a variety of use cases.
This video focuses on the notifications, alerts, and approval requests using Slack for Bonterra Impact Management. The solutions covered in this webinar can also be deployed for Microsoft Teams.
Interested in deploying notification automations for Bonterra Impact Management? Contact us at sales@sidekicksolutionsllc.com to discuss next steps.
Transcript: Selling digital books in 2024: Insights from industry leaders - T...BookNet Canada
The publishing industry has been selling digital audiobooks and ebooks for over a decade and has found its groove. What’s changed? What has stayed the same? Where do we go from here? Join a group of leading sales peers from across the industry for a conversation about the lessons learned since the popularization of digital books, best practices, digital book supply chain management, and more.
Link to video recording: https://bnctechforum.ca/sessions/selling-digital-books-in-2024-insights-from-industry-leaders/
Presented by BookNet Canada on May 28, 2024, with support from the Department of Canadian Heritage.
Epistemic Interaction - tuning interfaces to provide information for AI supportAlan Dix
Paper presented at SYNERGY workshop at AVI 2024, Genoa, Italy. 3rd June 2024
https://alandix.com/academic/papers/synergy2024-epistemic/
As machine learning integrates deeper into human-computer interactions, the concept of epistemic interaction emerges, aiming to refine these interactions to enhance system adaptability. This approach encourages minor, intentional adjustments in user behaviour to enrich the data available for system learning. This paper introduces epistemic interaction within the context of human-system communication, illustrating how deliberate interaction design can improve system understanding and adaptation. Through concrete examples, we demonstrate the potential of epistemic interaction to significantly advance human-computer interaction by leveraging intuitive human communication strategies to inform system design and functionality, offering a novel pathway for enriching user-system engagements.
UiPath Test Automation using UiPath Test Suite series, part 4DianaGray10
Welcome to UiPath Test Automation using UiPath Test Suite series part 4. In this session, we will cover Test Manager overview along with SAP heatmap.
The UiPath Test Manager overview with SAP heatmap webinar offers a concise yet comprehensive exploration of the role of a Test Manager within SAP environments, coupled with the utilization of heatmaps for effective testing strategies.
Participants will gain insights into the responsibilities, challenges, and best practices associated with test management in SAP projects. Additionally, the webinar delves into the significance of heatmaps as a visual aid for identifying testing priorities, areas of risk, and resource allocation within SAP landscapes. Through this session, attendees can expect to enhance their understanding of test management principles while learning practical approaches to optimize testing processes in SAP environments using heatmap visualization techniques
What will you get from this session?
1. Insights into SAP testing best practices
2. Heatmap utilization for testing
3. Optimization of testing processes
4. Demo
Topics covered:
Execution from the test manager
Orchestrator execution result
Defect reporting
SAP heatmap example with demo
Speaker:
Deepak Rai, Automation Practice Lead, Boundaryless Group and UiPath MVP
Connector Corner: Automate dynamic content and events by pushing a buttonDianaGray10
Here is something new! In our next Connector Corner webinar, we will demonstrate how you can use a single workflow to:
Create a campaign using Mailchimp with merge tags/fields
Send an interactive Slack channel message (using buttons)
Have the message received by managers and peers along with a test email for review
But there’s more:
In a second workflow supporting the same use case, you’ll see:
Your campaign sent to target colleagues for approval
If the “Approve” button is clicked, a Jira/Zendesk ticket is created for the marketing design team
But—if the “Reject” button is pushed, colleagues will be alerted via Slack message
Join us to learn more about this new, human-in-the-loop capability, brought to you by Integration Service connectors.
And...
Speakers:
Akshay Agnihotri, Product Manager
Charlie Greenberg, Host
Encryption in Microsoft 365 - ExpertsLive Netherlands 2024Albert Hoitingh
In this session I delve into the encryption technology used in Microsoft 365 and Microsoft Purview. Including the concepts of Customer Key and Double Key Encryption.
Mission to Decommission: Importance of Decommissioning Products to Increase E...
Couch db
1. Architecture Overview
Couchbase Server is a distributed, open source NoSQL database
engine. The core architecture is designed to simplify building modern
applications with a flexible data model and simpler high availability, high
scalability, high performance, and advanced security.
Couchbase Server consists of a single package that is installed on all
nodes. Using the SDKs, you can write applications in the language of
your choice (Java, node.js, .NET, or others). The applications connect
to a Couchbase Server cluster to perform read and write operations,
and run queries with low latencies (sub millisecond) and high
throughput (millions of operations per second).
To understand the Couchbase Server’s architecture, it is important to
understand both the core components of the system and the behavior of
core run time capabilities.
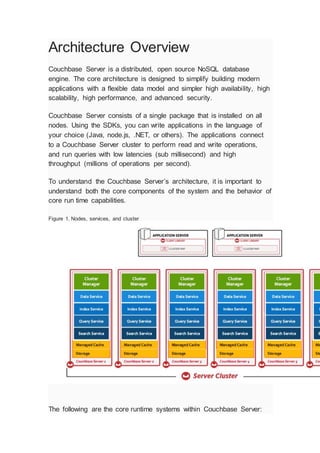
Figure 1. Nodes, services, and cluster
The following are the core runtime systems within Couchbase Server:
2. Connectivity architecture
Replication architecture
Storage architecture
Caching layer architecture
Security architecture
The runtimes such as replication, storage, caching, and so on can be
tuned to the needs of different services within the system. Couchbase
Server also consists of the following services:
Cluster manager
Data service
Index service
Query service
Search service (Developer Preview in 4.5)
Services
Couchbase services are components that run specific independent
workloads within the cluster. Databases handle three distinct workloads:
core data operations, indexing, and query processing. Couchbase
Server includes Data, Index, Search, and Query Services to enable
independent deployment of these workloads within a cluster.
Each node can run all services or a subset of the services. As an
administrator, you can create unique topologies using these
independent services and independently scale the three workloads. For
more information, see Services architecture and multidimensional
scaling.
Core data access and data service
Data Service provides the key-value API that you can use to
perform CRUD operations (create, retrieve, update, and delete)
on items with keys within buckets. For more information, see Data
service and core data access.
Indexing and index service
Indexes provide faster access to data in a bucket. Couchbase
Server supports the following indexers:
Incremental Map-Reduce View indexer
3. Global Secondary Index (GSI) indexer
Spatial Views indexer
Full Text Search indexer
Using these indexers, you can create two types of indexes:
Primary indexes which index all the keys in a given bucket and
are used when a secondary index cannot be used to satisfy a
query and a full bucket scan is required.
Secondary indexes can index a subset of the items in a given
bucket and are used to make queries targeting a specific
subset of fields more efficient.
In Couchbase Server, both MapReduce view and spatial view
indexers provide direct access to the indexes through the View
API. Both the indexers are placed within the data service as they
are partition-aligned to the core data distribution.
The full text search indexer (Developer Preview) provides direct
access to indexers through the FTS API. FTS index is placed
within its own service (FTS service) for independent scalability.
The Global Secondary Indexes (GSI) are deployed on nodes
hosting the index service and can be independently partitioned for
better performance and throughput with N1QL queries.
For more information about indexers and index services,
see Views, indexing, and index services.
Querying data and query service
With N1QL, you can query JSON documents using SQL-like
syntax. You can also run ad-hoc queries with filters and
aggregates over JSON data and reshape the JSON output. N1QL
API is available through the query service.
Incremental Map-Reduce views provide a View API that can
query data based on the keys defined by a view. Views can
define the keys using the MapReduce functions in JavaScript.
Incremental Map-Reduce view API are available through data
service.
4. Spatial views provide a Spatial View API that can query data
based on a bounding box (rectangle with coordinates). Spatial
views define the attributes that signify the coordinates a given
item represents using the MapReduce functions in JavaScript.
Spatial view API is available through the data service.
Full text search indexer provides a Search API that can perform
keyword searches directly on data in Couchbase Server. Search
API is available through the Search service.
For more information about querying and retrieving data,
see Querying data and query service.
CONTACT
LinkedIn
Terminology
This section defines the key terms and concepts used in the Couchbase
Server architecture documentation.
Node
A single Couchbase Server instance running on a physical
server, virtual machine, or a container. All nodes are identical:
they consist of the same components and services and provide
the same interfaces.
Cluster
A cluster is a collection of nodes that are accessed and managed
as a single group. Each node is an equal partner in orchestrating
the cluster to provide facilities such as operational information
(monitoring) or managing cluster membership of nodes and
health of nodes.
Clusters are scalable. You can expand a cluster by adding new
nodes and shrink a cluster by removing nodes.
The Cluster Manager is the main component that orchestrates the
cluster level operations. For more information, see Cluster
Manager.
Bucket
5. A bucket is a logical container for a related set of items such as
key-value pairs or documents. Buckets are similar to databases in
relational databases. They provide a resource management
facility for the group of data that they contain. Applications can
use one or more buckets to store their data. Through
configuration, buckets provide segregation along the following
boundaries:
Cache and IO management
Authentication
Replication and Cross Datacenter Replication (XDCR)
Indexing and Views
Item
Item is the basic unit of data in a Couchbase Server. An item is a
key-value pair where each stored value is identified by a unique
key within the bucket.
This is different from relational databases which store data in
databases grouped by tables. Tables have a strict schema (set of
columns) and data is stored in rows in tables.
Values for an item can be anything from a single bit, to a decimal
measurement, to JSON documents. Storing data as a JSON
document allows the Couchbase Server to provide extended
features such as indexing and querying. Items are also referred to
as documents, objects, or key-value pairs.
vBucket
vBuckets are physical partitions of the bucket data. By default,
Couchbase Server creates a number of master vBuckets per
bucket (typically 1024) to store the bucket data. Buckets may
store redundant copies of data calledreplicas. Each replica also
creates another set of vBuckets to mirror the active vBucket. The
vBuckets that maintain replica data are called replica vBuckets.
Every bucket has its own set of active and replica vBuckets and
those vBuckets are evenly distributed across all nodes within the
data service.
Cluster map
The cluster map contains a mapping of which services belong to
which nodes at a given point in time. This map exists on all
6. Couchbase nodes as well as within every instantiation of the
client SDK. Through this map, the application is able to
transparently identify the cluster topology and respond when that
topology changes. Cluster map contains a vBucket map.
vBucket map
A vBucket map contains a mapping of vBuckets to nodes at a
given point in time. This map exists on all Couchbase nodes as
well as within every instantiation of the client SDK. Through this
map, the application is able to transparently identify the nodes
that contain the vBuckets for a given key and respond when the
topology changes.
Replication
Replication is the process of creating additional copies of active
data on alternate nodes. Replication is at the heart of the
Couchbase Server architecture enabling high availability, disaster
recovery, and data exchange with other big data products. It is
the core enabler for
Moving data between nodes to maintain replicas.
Geo-distribution of data with cross datacenter replication (XDCR)
Queries with incremental map-reduce and spatial views
Backups with full or incremental snapshots of data
Integration with Hadoop, Kafka and text search engines based on
Lucene like Solr
For more information about replication, see High availability and
replication architecture.
Rebalance
The topology of a cluster can change as nodes are added or
removed due to capacity requirements or node failures. As the
number of nodes changes, the rebalance operation is used to
redistribute the load and adapt to the new topology of nodes. At
its core, a rebalance operation for the data service is the
incremental movement of vBuckets from one node to another. By
moving vBuckets onto or off of nodes, these nodes become
responsible for more or less data and begin handling more or less
traffic from the applications. A rebalance operation also brings in
7. or takes out nodes from the various services. While the rebalance
operation is in progress, it also updates the cluster map on all
clients with any topology changes. The Cluster Manager
coordinates the movement and hand off of vBuckets and services
during the rebalance operation. Rebalance is performed
completely online and with minimal impact to the incoming
workload.
Failover
Failover is the process that diverts traffic away from failing nodes
to the remaining healthy nodes. Failover can be done
automatically by the Couchbase cluster based on the health
status of a node, or can be done manually by the administrator or
an external script. A node that is failed over does not accept any
new traffic.
Graceful failover
Graceful failover is the proactive ability to remove a Data service
node from the cluster in an orderly and controlled fashion. It is an
online operation with zero downtime, which is achieved by
promoting replica vBuckets on the remaining cluster nodes to
active and the active vBuckets on the node to failover to dead.
This type of failover is primarily used for planned maintenance of
the cluster.
Hard failover
Hard failover is the ability to drop a node quickly from the cluster
when it has become unavailable or unstable. This is achieved by
promoting replica vBuckets on the remaining cluster nodes to
active. Hard failover is primarily used when there is an unplanned
outage to a node in the cluster.
Automatic failover
Automatic failover is the built-in ability to have the Cluster
Manager detect and determine when a node is unavailable and
then initiate a hard failover.
Node lifecycle
As the cluster topology changes, nodes in the cluster go through
a set of state transitions. Operations such as Add Node, Remove
Node, Rebalance, and Failover cause state transitions. The
8. following diagram lists the states and state transitions of the
nodes in the cluster.Figure 1. Node lifecycle
CONTACT
LinkedIn
Twitter
Facebook
Connectivity Architecture
Couchbase Server is a fully distributed database, making connection
management and efficient communication key components of the
architecture. This section provides information about client to cluster,
node to node, cluster to cluster, and cluster to external products
9. communications. It also describes the phases of establishing a
connection.
Client to Cluster Communication
Client to Cluster Communication
Client applications communicate with Couchbase Server through a set of
access points tuned for the data access category such as CRUD operations,
N1QL queries, and so on. Each access point supports clear text and
encrypted communication ports.
There are four main types of access points that drive the majority of
client to server communications.
Table 1. Communication ports
Type Port API
REST 8091,
18091
(SSL)
Admin operations
with the REST
Admin API
Direct Connect to a single node
in the cluster to perform admin
operations, monitoring, and
alerting.
REST 8092,
18092
(SSL)
Query with View
(View and Spatial
View API)
Load balanced connection
across nodes of the cluster that
run the data service for View
queries.
REST 8093,
18093
(SSL)
Query with N1QL
(N1QL API)
Load balanced connection
across nodes of the cluster that
run the query service for N1QL
queries.
ONLINE 11210,
11207
(SSL)
Core Data
operations
Stateful connections from client
app to nodes of the cluster that
runs data service for CRUD
operations.
REST 8094 Search Service
(Developer
Preview)
Load balanced connections
across nodes of the cluster that
run the search service for full
10. Table 1. Communication ports
Type Port API
text search queries.
Note:This table lists a subset of the network ports. For a complete list of
network ports, see Network Configuration.
For information on how a connection is established when a request from
the client side is received, see Connectivity Phases.
Node to Node Communication
Node to Node Communication
Nodes of the cluster communicate with each other to replicate data, maintain
indexes, check health of nodes, communicate changes to the configuration of
the cluster, and much more.
Node to node communication is optimized for high efficiency operations
and may not go through all the connectivity phases (authentication,
discovery, and service connection). For more information about
connectivity phases, see Client to Cluster Communication.
Cluster to Cluster Communication
Cluster to Cluster Communication
Couchbase Server clusters can communicate with each other using the Cross
Datacenter Replication (XDCR) capability.
XDCR communication is set up from a source cluster to a destination
cluster. For more information, see Cross Datacenter Replication.
External Connector Communication
External Connector Communication
Couchbase Server also communicates with external products through
connectors.
Couchbase has built and supports connectors for Spark, Kafka,
Elasticsearch, SOLR, and so on.
The community and other companies have also built more connectors
for ODBC driver, JDBC driver, Flume, Storm, Nagios connectors for
Couchbase, and so on. External connectors are typically built using the
existing client SDKs, the direct service or admin APIs listed in the client
11. to cluster communication section, or feed directly from the internal APIs
such as the Database Change Protocol (DCP) API. For more
information about Database Change Protocol, seeIntra-cluster
Replication.
Connectivity Phases
Connectivity Phases
When a connection request comes in from the client side, the
connection is established in three phases: authentication, discovery,
and service connection.
1. Authentication: In the first phase, the connection to a bucket
is authenticated based on the credentials provided by the
client. In case of Admin REST API, admin users are
authenticated for the cluster and not just a bucket.
2. Discovery: In the second phase, the connection gets a cluster
map which represents the topology of the cluster, including the
list of nodes, how data is distributed on these nodes, and the
services that run on these nodes. Client applications using the
SDKs only need to know the URL or address to one of the
nodes in the cluster. Client applications with the cluster map
discover all other nodes and the entire topology of the cluster.
3. Service Connection: Armed with the cluster map, client SDKs
figure out the connections needed to establish and perform the
service level operations through key-value, N1QL, or View
APIs. Service connections require a secondary authentication
to the service to ensure the credentials passed on to the
service have access to the service level operations. With
authentication cleared, the connection to the service is
established.
At times, the topology of the cluster may change and the
service connection may get exceptions on its requests to the
services. In such cases, client SDKs go back to the previous
phase to rerun discovery and retry the operation with a new
connection.
CONTACT
LinkedIn
12. Twitter
Facebook
Google+
PRODUCTS
High Availability and Replication
Architecture
Couchbase Server provides high availability for reading and for writing
of data through a variety of features. For writing, the ability to get data
off of a single node as quickly as possible is paramount to avoid any
data loss due to a failure of that individual node.
Database Change Protocol (DCP)
Database Change Protocol (DCP)
Database Change Protocol (DCP) is the protocol used to stream bucket
level mutations. Given the distributed nature of Couchbase Server, DCP
sits at the heart of Couchbase Server architecture. DCP is used for high
speed replication of mutations to maintain replica vBuckets, incremental
MapReduce views and spatial views, Global Secondary Indexes (GSIs),
cross datacenter replication (XDCR), backups, and many other external
connectors.
DCP is a memory based replication protocol that is ordering, resumable,
and consistent. DCP immediately streams any changes made to
documents in memory to the destination. The memory based
communication reduces latency and greatly boosts availability, prevents
data loss, improves freshness of indexes, and more.
To work with DCP, you need to be familiar with the following concepts,
which are listed in alphabetical order for convenience.
Application client
A normal client that transmits read, write, update, delete, and
query requests to the server cluster, usually for an interactive web
application.
DCP client
13. A special client that streams data from one or more Couchbase
server nodes, for purposes of intra-cluster replication (to be a
backup in case the master server fails), indexing (to answer
queries in aggregate about the data in the whole cluster), XDCR
(to replicate data from one cluster to another cluster, usually
located in a separate data center), incremental backup, and any
3rd party component that wants to index, monitor, or analyze
Couchbase data in near real time, or in batch mode on a
schedule.
Failover log
A list of previously known vBucket versions for a vBucket. If a
client connects to a server and was previously connected to a
different version of a vBucket than that server is currently working
with, the failure log is used to find a rollback point.
History branch
Whenever a node becomes the master node for a vBucket in the
event of a failover or uncontrolled shutdown and restart, if it was
not the farthest ahead of all processes watching events on that
partition and starts taking mutations, it might reuse sequence
numbers that other processes have already seen on this partition.
This can be a history branch, and the new master must assign
the vBucket a new vBucket version so that DCP clients in the
distributed system can recognize that they are ahead of the new
master and roll back changes at the point this happened in the
stream. During a controlled handover from an old master to a new
master, the sequence history cannot have branches, so there is
no need to assign a new version to the vBucket being handed off.
Controlled handovers occur in the case of a rebalance for
elasticity (such as adding or removing a node) or a swap
rebalance in the case of an upgrade (such as adding a new
version of Couchbase Server to a cluster or removing an old
version of Couchbase Server).
Mutation
A mutation is an event that deletes a key or changes the value a
key points to. Mutations occur when transactions such as create,
update, delete or expire are executed.
Rollback point
14. The server uses the failover log to find the first possible history
branch between the last time a client was receiving mutations for
a vBucket and now. The sequence number of that history branch
is the rollback point that is sent to the client.
Sequence number
Each mutation that occurs on a vBucket is assigned a number,
which strictly increases as events are assigned numbers (there is
no harm in skipping numbers, but they must increase), that can
be used to order that event against other mutations within the
same vBucket. This does not give a cluster-wide ordering of
events, but it does enable processes watching events on a
vBucket to resume where they left off after a disconnect.
Server
A master or replica node that serves as the network storage
component of a cluster. For a given partition, only one node can
be master in the cluster. If that node fails or becomes
unresponsive, the cluster selects a replica node to become the
new master.
Snapshot
To send a client a consistent picture of the data it has, the server
takes a snapshot of the state of its disk write queue or the state of
its storage, depending on where it needs to read from to satisfy
the client’s current requests. This snapshot represents the exact
state of the mutations it contains at the time it was taken. Using
this snapshot, the server can send the items that existed at the
point in time the snapshot was taken, and only those items, in the
state they were in when the snapshot was taken. Snapshots do
not imply that everything is locked or copied into a new structure.
In the current Couchbase storage subsystem, snapshots are
essentially “free." The only cost is when a file is copy compacted
to remove garbage and wasted space, the old file cannot be freed
until all snapshot holders have released the old file. It’s also
possible to “kick” a snapshot holder if the system determines the
holder of the snapshot is taking too long. DCP clients that are
kicked can reconnect and a new snapshot will be obtained,
allowing it to restart from where it left off.
vBucket
15. Couchbase splits the key space into a fixed amount of vBuckets,
usually 1024. Keys are deterministically assigned to a vBucket,
and vBuckets are assigned to nodes to balance the load across
the cluster.
vBucket stream
A grouping of messages related to receiving mutations for a
specific vBucket. This includes mutation, deletion, and expiration
messages and snapshot marker messages. The transport layer
provides a way to separate and multiplex multiple streams of
information for different vBuckets. All messages between
snapshot marker messages are considered to be one snapshot.
A snapshot contains only the recent update for any given key
within the snapshot window. It might require several complete
snapshots to get the current version of the document.
vBucket version
A universally unique identifier (UUID) and sequence number pair
associated with a vBucket. A new version is assigned to a
vBucket by the new master node any time there might have been
a history branch. The UUID is a randomly generated number, and
the sequence number is the sequence number that vBucket last
processed at the time the version was created.
Intra-cluster Replication
Intra-cluster Replication
Intra-cluster replication involves replicas that are placed on another
node in the same cluster.
Replicas
Replicas are copies of data that are placed on another node in a cluster.
The source of the replicated vBucket data is called the active vBucket.
Active vBuckets perform read and write operations on individual
documents. The destination vBucket is called the replica vBucket.
Replica vBuckets receive a continuous stream of mutations from the
active vBucket through the Database Change Protocol (DCP). Although
replica vBuckets are not accessed typically, they can respond to read
requests.
16. Within the data service, active vBuckets are spread across the cluster
for even distribution of data and best performance. Additional replicas
are optional. As an administrator, you can create between one and
three additional copies (replica vBuckets) of the active vBuckets.
Replica vBuckets are also spread across the cluster for best availability
and can use failure-domain definitions to guide distribution. For
example, to protect against the node failure-domain, Couchbase Server
places an active vBucket and its corresponding replica vBucket on
separate nodes or separate racks.Figure 1. Couchbase Server replicas
17. Cross Datacenter Replication
Cross Datacenter Replication
Using the cross datacenter replication (XDCR) capability you can set up
replication of data between clusters. XDCR helps protect against data
center failures and also helps maintain data locality in globally
distributed mission critical applications.
As an administrator, you can use XDCR to create replication
relationships that replicate data from a source cluster’s bucket to a
destination cluster’s bucket. You can also set up complex topologies
across many clusters such as bidirectional topologies, ring topologies,
tree structured topologies, and more.
XDCR uses DCP to stream mutations with an agent running on each
node within the data service. This XDCR agent is tuned to function with
low latency and high reliability over WAN type latencies and efficiently
handle frequent connectivity issues between clusters.Figure 2. Cross
datacenter replication (XDCR)
18. In XDCR, each replication stream is set up between a source and
destination bucket on separate clusters. Each bucket on each cluster
can be a source or a destination for many replication definitions in
XDCR. XDCR is a "push-based" replication and so each source node
runs the XDCR agent and pushes mutations to the destination bucket.
The XDCR agent on the source node uses direct access
communication (XMem) protocol to propagate mutations from the
source vBucket to the matching vBucket on the destination cluster.
Since there are equal number of vBuckets (default is 1024) on both the
source and the destination clusters, there is a one-to-one match for
each source and destination vBucket.
It is important to note that XDCR does not require source and
destination clusters to have identical topology. XDCR agents are
topology aware and match the destination vBucket with the local
vBucket, propagating mutations directly from vBucket to vBucket.
Conflict Resolution in XDCR
In case of bi-directional XDCR where the same dataset exists on both
the clusters, conflicts can arise. XDCR automatically performs conflict
resolution for different document versions on source and destination
clusters.
The algorithm is designed to consistently select the same document on
either a source or destination cluster. For each stored document, XDCR
perform checks of metadata to resolve conflicts. It checks the following:
Revision ID, a numerical sequence that is incremented on each
mutation
CAS value
Document flags
Expiration (TTL) value
XDCR conflict resolution uses revision ID as the first field to resolve
conflicts between two writes across clusters. Revision IDs are
maintained per key and are incremented with every update to the key.
Revision IDs keep track of number of mutations to a key, thus XDCR
19. conflict resolution can be best characterized as “the most updates
wins”.
If a document does not have the highest revision number, changes to
this document will not be stored or replicated; instead the document
with the highest score will take precedence on both clusters. Conflict
resolution is automatic and does not require any manual correction or
selection of documents.
By default XDCR fetches metadata twice from every document before it
replicates the document at a destination cluster. XDCR fetches
metadata on the source cluster and looks at the number of revisions for
a document. It compares this number with the number of revisions on
the destination cluster and the document with more revisions is
considered the ‘winner.’
If XDCR determines a document from a source cluster will win conflict
resolution, it puts the document into the replication queue. If the
document will lose conflict resolution because it has a lower number of
mutations, XDCR will not put it into the replication queue. Once the
document reaches the destination, this cluster will request metadata
once again to confirm the document on the destination has not changed
since the initial check. If the document from the source cluster is still the
‘winner’ it will be persisted onto disk at the destination. The destination
cluster will discard the document version with the lowest number of
mutations.
The key point is that the number of document mutations is the main
factor that determines whether XDCR keeps a document version or not.
This means that the document that has the most recent mutation may
not be necessarily the one that wins conflict resolution. If both
documents have the same number of mutations, XDCR selects a
winner based on other document metadata. Precisely determining
which document is the most recently changed is often difficult in a
distributed system. The algorithm Couchbase Server uses does ensure
that each cluster can independently reach a consistent decision on
which document wins.
CONTACT
LinkedIn
20. Twitter
Facebook
Google+
Storage Architecture
Couchbase Server consists of various services and components that
have different storage requirements. Each component uses the
optimized storage engine purpose-built and configured for the workload
of relevant components.
As an administrator, you can independently control data and index
storage paths within the file system on a per node basis. This ensures
data and index storage can utilize separate I/O subsystems to enable
independent tuning and isolation. There are multiple storage engines in
use in Couchbase Server:
Data Service, MapReduce Views, Spatial Views, and Couchstore
For core data operations, MapReduce views, and spatial views,
Couchbase Server uses Couchstore. Each vBucket is represented as
a separate Couchstore file in the file system. Couchstore uses a
B+tree structure to quickly access items through their keys. For
efficient writes, Couchstore uses an append-only write model for each
file for efficient and safe writes.
Index Service, Search Service, and ForestDB
For indexing with GSI in the Index service and full-text index in the
search service, Couchbase Server uses ForestDB. With ForestDB,
each index is represented as a separate ForestDB file in the file
system. Unlike Couchstore, ForestDB uses a B+trie structure to
quickly access item through its index key. B+trie provides a more
efficient tree structure compared to B+trees and ensures a shallower
tree hierarchy to better scale large item counts and very large index
keys. ForestDB offers multiple options for its writes. ForestDB can be
configured to use an append-only write model for each file for efficient
writes which also requires regular compaction for cleanup. ForestDB
can also be configured to use “circular reuse” which allows incoming
writes to reuse the existing orphaned space within the file instead of
simply just append only writes. In the “circular reuse” mode,
21. compaction is still needed but with much less frequency (typically
once a week). For more information on ForestDB and B+trie,
see https://github.com/couchbase/forestdb.
Couchstore Versus ForestDB
Couchstore Versus ForestDB
Couchbase Server uses multiple storage engines to optimize specific I/O
patterns required by the services. Couchstore is used for storage under data
service for both database engine and for view engine. ForestDB is used by the
index service for storage of global secondary indexes.
There are a few similarities between Couchstore and ForestDB.
Both come with an append-only write approach. Additionally, ForestDB
supports the circular reuse write approach.
Both storage engines perform compression using the SNAPPY library
when persisting.
Both storage engines require compaction to periodically clean up
orphaned pages. However, the ForestDB circular reuse write model
requires less frequent compactions.
There are a few important differences between Couchstore and ForestDB.
Tree Structure: Unlike Couchstore, ForestDB does not maintain a
B+tree structure. ForestDB uses an optimized tree structure called
B+trie. B+trie can handle large keys much more efficiently. This helps in
cases where a large set of attributes or a single large attribute in the
document need to be indexed. B+tree with large index keys can end up
with many levels in the tree. The depth of the tree impacts the write
amplification and access times to get to the leaf of the tree during scans.
With a B+trie, the same key size can achieve much shallower tree
structure reducing both write amplification and retrieval times.
Caching: Unlike Couchstore, ForestDB maintain its own cache. This
cache holds the mutations before they are persisted to disk.
Append-only and Compaction
Append-only and Compaction
As mutations arrive, the writes append new pages to the end of the file and
invalidate links to previous versions of the updated pages. With these append-
only write models, a compaction process is needed to clean up the orphaned or
fragmented space in the files.
22. In Couchbase Server, the compaction process reads the existing file and writes
a new contiguous file that no longer contains the orphaned items. The
compaction process runs in the background and is designed to minimize the
impact on the front end performance.
The compaction process can be manual, scheduled, or automated based on
percentage of fragmentation. Compaction of an entire dataset is parallelized
across multiple nodes as well as multiple files within those nodes.
In the figure below, as updated data is received by Couchbase Server, the
previous versions are orphaned. After compaction, the orphaned
references are removed and a continuous file is created.Figure 1.
Compaction in Couchbase Server
Writes with Circular Reuse
Writes with Circular Reuse
When you enable writes with “circular reuse”, as mutations arrive, instead of
simply appending new pages to the end of the file, write operations look for
reusing the orphaned space in the file. If there is not enough orphaned space
available in the file that can accommodate the write, the operation may still do
a write with append. With writes with circular reuse, a compaction process is
still needed to create a continuous (defragmented) file.
With circular reuse, full compaction still operates the same way. The
compaction process reads the existing file and writes a new contiguous file that
23. no longer contains the orphaned items, and is written as a contiguous file in
order of the keys. The compaction process runs less often with writes with
circular reuse. Compaction still runs in the background and is designed to
minimize the impact on the front end performance.
The compaction process can be manual, scheduled, or automated based on
percentage of fragmentation. See Auto-compaction Settings for details.
Compaction of an entire dataset is parallelized across multiple nodes as well as
multiple files within those nodes.
Managed Caching Layer
Architecture
Couchbase Server is built on a memory-first architecture and managing
memory effectively is central to achieving high performance and
scalability.
Caching Layer
Caching Layer
Each service in Couchbase Server tunes its caching based on its
needs.
Data service uses a managed cache that is tuned to enable fast key
based read and write operations with low latency under high
concurrency.
Index and Search services manage the cache to ensure index
maintenance and fast scans for the most popular indexes in the
system.
Query service manages memory to calculate query responses by
processing streams effectively for the execution plans generated by
the optimizer.
The Couchbase SDK never access the persistence layer directly, but
communicate through the caching layer. Couchbase Server moves the
data to and from the disk internally as needed, thereby acting as both a
read-through and a write-through cache. This facilitates extremely high
read-write rates and eliminates the need for an external caching tier.
Unlike many other database systems, Couchbase Server does not
24. depend on external caching systems. This simplifies development as
developers do not have to deal with complex cache coherency issues or
varying performance capabilities across technologies.
Couchbase Server automatically manages the caching layer and
coordinates with persistent storage to ensure that enough cache space
exists to maintain performance. It automatically places items that come
in to the caching layer into a disk queue so that it can write these items
to disk. If the server determines that a cached item is infrequently used,
it removes the item from RAM to free up space for other incoming
operations. Similarly, when infrequently used items are requested, the
server retrieves the items from disk and stores them in the caching
layer. In order to provide the most frequently-used data while
maintaining high performance, Couchbase Server manages a working
set of your entire dataset. The working set is the data most frequently
accessed and is kept in memory for high performance.
By default, the Couchbase Server automatically keeps frequently used
data in memory and less frequently used data on disk. Couchbase
Server moves data from the managed cache to disk asynchronously, in
the background, to ensure there is enough memory that can be freed up
for incoming operations. The server constantly monitors the information
accessed by clients and decides how to keep the active data within the
caching layer. Items may be ejected from memory when additional
memory is needed to perform incoming operations. These items have
already been persisted to disk and require no additional I/O. The
managed cache ensures that reads and writes are handled at a very
fast rate, while removing the typical load and performance spikes that
would otherwise cause a traditional RDBMS to produce erratic
performance.
RAM quotas
RAM quotas
RAM quota allocation is governed through individual services. Each
service in Couchbase Server tunes its caching based on its needs.
The Data service uses a managed cache based on memcached that
is tuned to enable fast key based read and write operations with low
latency under high concurrency.
25. The Index and Search services manage cache to ensure index
maintenance and scans can be serviced fast for the most popular
indexes in the system.
Query service manages its memory to calculate query responses by
processing streams effectively for the execution plans generated by
the optimizer and caches certain parts of those query plans.
Allocation of memory to services is governed through RAM quota
allocations. Data, Index and Search services both configure RAM
quotas per node in the cluster. Query service automatically manages its
memory without a defined quota.
Each node in the cluster running the relevant services inherits the value
and may allocate up to the specified amount.
Index RAM Quota governs the index service RAM quota allocation
per node. Each node running the index service inherits the value of
Index RAM Quota for caching Global Secondary Indexes (GSI).
Search RAM Quota governs the search service RAM quota
allocation per node. Each node running the search service inherits
the value of search RAM Quota for caching Full Text Indexes.
Data RAM Quota governs the data service RAM quota allocation per
node. Each node running the data service inherits the value set for
Data RAM Quota for caching bucket data.
Bucket RAM Quotas are allocated out of the Cluster Data RAM quota.
As an administrator, you can control the total RAM quota allocated to
each bucket through Bucket RAM Quota under bucket settings. The
total RAM configured across all buckets cannot exceed the total Data
RAM Quota allocated for the data service at the cluster level.
CONTACT
LinkedIn
Twitter
Facebook
Cluster Manager
Cluster Manager runs on all the nodes of the cluster and orchestrates
cluster wide operations.
26. The Cluster Manager is responsible for the following operations:
Cluster topology and node membership
o Managing node membership, adding and removing nodes
o Discovery of cluster topology by internal and external connections
o Service layout for data, index, and query services across nodes
o Rebalancing the load as cluster topology changes
o Node health, and failure and service monitoring
Data placement
o Smart distribution of primary and secondary replicas with node,
rack failure domain awareness for best failure-protection
Central statistics and logging
o Operational statistics gathering and aggregation to cluster level
statistics
o Logging services for cluster supportability
Authentication
o Authentication of connections to the cluster
27. Figure 1. Cluster Manager Architecture
The Cluster Manager consists of the following modules to perform the
tasks above:
REST API and Auth modules: Cluster Manager communication and
authentication happen through the REST API and Auth modules. All
administrative operations performed through CLI tools or Admin
Portal are executed through the admin REST API.
Master Services module manages global cluster level operations
such as master and replica vbucket placement, auto failover and
rebalance.
Bucket Services module manages bucket level operations such as
establishing or handing off replication for replica maintenance or
bucket level stats collection.
Per-node Services module manage node health and process/service
monitoring and restart.
28. Cluster manager generic local and distributed facilities also
manage local and distributed configuration management, cluster-wide
logging and more.
Node Membership: Adding and Removing Nodes Without Downtime
Node Membership: Adding and Removing
Nodes Without Downtime
The Cluster Manager is responsible for cluster membership. When the
topology of a cluster changes, the Cluster Manager walks through a set
of carefully orchestrated operations to redistribute the load while
keeping the existing workload running without a hiccup.
The following workflow describes the high-level operations to add a new
node to the data service:
1. The Cluster Manager ensures the new nodes inherit the cluster
configuration.
2. In order to redistribute the data to the new nodes, the Cluster
Manager initiates rebalance and recalculates the vBucket map.
3. The nodes which are to receive data initiate DCP replication
streams from the existing nodes for each vBucket and begin
building new copies of those vBuckets. This occurs for both
active and replica vBuckets depending on the new vBucket
map layout.
4. Incrementally as each new vBucket is populated, the data
replicated and the indexes optionally updated, an atomic
switchover takes place from the old vBucket to the new
vBucket.
5. As the new vBuckets on the new nodes become active, the
Cluster Manager ensures that the new vBucket map and
cluster topology is communicated to all the existing nodes and
clients. This process is repeated until the rebalance operation
completes running.
Removal of one or more nodes from the data service follows a similar
process by creating new vBuckets within the remaining nodes of the
cluster and transitioning them off of the nodes to be removed. When
there are no more vBuckets assigned to a node, the node is removed
from the cluster.
29. When adding or removing nodes from the indexing and query services,
no data is moved and so their membership is simply added or removed
from the cluster map. The client SDKs automatically begin load
balancing across those services using the new cluster map.
Smart Data Placement with Rack and Zone Awareness
Smart Data Placement with Rack and Zone
Awareness
Couchbase Server buckets physically contain 1024 master and 0 or
more replica vBuckets. The Cluster Manager master services module
governs the placement of these vBuckets to maximize availability and
rebalance performance.
The Cluster Manager master services module calculates a vBucket map
with heuristics to maximize availability and rebalance performance. The
vBucket map is recalculated whenever the cluster topology changes.
The following rules govern the vBucket map calculation:
Master and replica vBuckets are placed on separate nodes to protect
against node failures.
If a bucket is configured with more than 1 replica vBucket, each
additional replica vBucket is placed on a separate node to provide
better protection against node failures.
If server groups are defined for master vBuckets (such as rack and
zone awareness capability), the replica vBuckets are placed in a
separate server group for better protection against rack or availability
zone failures.
Centralized Management, Statistics, and Logging
Centralized Management, Statistics, and
Logging
The Cluster Manager simplifies centralized management with
centralized configuration management, statistics gathering and logging
services. All configuration changes are managed by the orchestrator
and pushed out to the other nodes to avoid configuration conflicts.
In order to understand what your cluster is doing and how the cluster is
performing, Couchbase Server incorporates a complete set of statistical
30. and monitoring information. The statistics are accessible through all the
administration interfaces - CLI ( cbstats tool), REST API, and the
Couchbase Web Console.
The Couchbase Web Console provides a complete suite of statistics
including the built-in real-time graphing and performance data. It gives
great flexibility as you (as an Administrator) can aggregate the statistics
for each bucket and choose to view the statistics for the whole cluster or
per node.
The statistics information is grouped into categories, allowing you to
identify different states and performance information within the cluster.
Statistics on hardware resources
Node statistics show CPU, RAM and I/O numbers on each of the
servers and across your cluster as a whole. This information is
useful to identify performance and loading issues on a single
server.
Statistics on vBuckets
The vBucket statistics shows the usage and performance
numbers for the vBuckets. This is useful to determine whether
you need to reconfigure your buckets or add servers to improve
performance.
Statistics on views and indexes
View statistics display information about individual views in your
system such as number of reads from the index or view and its
disk usage, so that you can monitor the effects and loading of a
view on the Couchbase nodes. This information can indicate that
your views need optimization, or that you need to consider
defining views across multiple design documents.
Statistics on replication (DCP, TAP, and XDCR)
The Database Change Protocol (DCP) interface is used to
monitor changes and updates to the database. DCP is widely
used internally to replicate data between the nodes, for backups
with cbbackup, to maintain views and indexes and to integrate
with external products with connectors such as Elasticsearch
connector, Kafka connector or the Sqoop connector. XDCR
replicates data between clusters and uses DCP in conjunction
31. with an agent that is tuned to replicate data under higher WAN
latencies.
TAP is similar to DCP, but is a deprecated protocol. Legacy tools
may still use the protocol and stats are still available through the
console.
Given the central role of replication in a distributed system like
Couchbase Server, identifying statistics on replication is critical.
Statistics in replication help visualize the health of replication and
bottlenecks in replication by displaying replication latency and
pending items in replication streams.
CONTACT
Data Service and Core Data
Access
Data service in Couchbase Server provides the core data access with
the database engine and incremental MapReduce view processing with
the views engine.
Couchbase Server stores data as items. An item is made up of a key
(also known as a document key or a document ID) and a document
value, along with associated metadata. Couchbase Server organizes
data into Buckets.
Couchbase Server provides simple to use and efficient GET and SET
methods to mutate and retrieve items by keys, and a number of query
methods to filter, group, and aggregate data. Data can be accessed
concurrently from many applications and through a mix of these
methods at any moment in time. The database engine can process
these highly concurrent requests at a sub-millisecond latency at scale. It
achieves this through a managed cache, a high throughput storage
engine, and a memory based replication architecture. For more
information, see Database engine architecture.
Durability
Couchbase Server database engine stores and retrieves
information using memory first on a single node that carries the
32. master vBucket. This is the fastest option for storing data.
Depending on the bucket type, data gets stored on disk
eventually. Couchbase Server also provides tunable durability
options to store data in the RAM of multiple nodes (using
the replicateTo flag) or on disk on one or more nodes (using the
persistTo flag). Storing data in the RAM of multiple nodes
protects against node failures and also provides a fast and
durable way to store data. Storing data on disk can be slow as
the operational latency depends on the disk subsystem and
typically disk subsystems are much slower than memory access.
Consistency
When retrieving data using a key, Couchbase Server database
engine provides full consistency (sometimes referred to as read-
your-own-write semantics) by ensuring access to the master
vBucket or optionally allowing access to eventually consistent
replica vBuckets for reads (also known as replica reads).
Items are organized into buckets, which provide grouping of items
(keys and values). Buckets govern resource allocation and
usage, high availability settings, and security for the group of
items. Buckets use vBuckets to physically organize storage and
distribution of items. Items in a bucket are indexed through Views
and indexes created on the buckets’ data. Items in a bucket can
also be replicated between clusters using cross datacenter
replication (XDCR).
Creating items
Information is stored in the database using a variant of
memcached binary protocol interface that stores a value against
a specified key. As a developer, you typically use this key through
one of the Couchbase client SDKs. Bulk operations to set the
key-value pairs of a large number of documents at the same time
are available, and are more efficient than multiple smaller
requests.
The value stored can be a JSON document or any binary value,
including structured and unstructured strings, serialized objects
(from the native client language), and native binary data (for
example, images or audio). Each bucket can mix the types of
data stored with JavaScript Object Notation (JSON) or binary
33. value types. However, using the JSON format gives access to a
more powerful query functionality.
Updating items
You can update information in the database using the
memcached protocol interface through a Couchbase client SDK.
The protocol includes functions to directly update the entire
content, and also to perform simple operations, such as
appending information to an existing record, or incrementing and
decrementing integer values.
Expiration flag
Each document stored in the database has an optional expiration
flag (TTL: Time To Live) that is used to automatically delete
items. This flag can be set when creating or updating an item.
Use the expiration flag for data that has a limited life and needs to
be deleted automatically. This flag is useful when storing
temporary data such as session state next to your persisted data
or when using Couchbase as a caching store in front of another
database for high speed access.
You can specify the value of an expiration flag (TTL) in seconds
or as Unix epoch time (number of seconds that have elapsed
since January 01, 1970). However, if the TTL for an item is
greater than 30 days, specify the value in Unix epoch time, for
example 1451606399. By default, the expiration flag is set to
infinite, that is, the information is stored indefinitely.
Deleting items
You can delete information from the Couchbase Server using a
Couchbase client SDK which includes an explicit delete
command to remove a key-value pair from the server.
Retrieving items
You can retrieve items from the Couchbase Server with or without
referencing keys. You can retrieve values by key using the Data
Service.
If you know the key used to store a particular value, then you can
use the memcached protocol (or an appropriate memcached
compatible client-library) to retrieve the value stored against a
specific key. You can also perform bulk retrieve operations.
34. There are two main ways to retrieve data without referencing
keys:
Use N1QL to submit a SQL-like query to retrieve your data.
Note:You must enable Query Service to run N1QL queries.
Use views to define and query an alternate projection over the
data in the bucket that provides an alternative key that you can
use to query. Views are a part of the data service.
Buckets
Buckets are logical groups of items (keys and values) which can be
used to organize, manage, and analyze the group of items.
Bucket types
Bucket types
There are two types of buckets:
Couchbase buckets use vBuckets to organize disk and memory
storage on the nodes and distribution of items across the cluster.
Items in a Couchbase bucket can be indexed through Views and
Indexes created on the data in the buckets. These items can also be
replicated between nodes and clusters using Database Change
Protocol (DCP) and Cross Datacenter Replication (XDCR).
Memcached buckets exhibit special behavior.
Table 1. Bucket types in Couchbase Server
Bucket
type
Description
Couchbase Provides highly-available and dynamically reconfigurable
distributed data storage, with persistence and replication
services.
100% protocol compatible with, and built in the spirit of,
the memcached open source distributed key-value cache.
Memcached Provides a directly-addressed, distributed (scale-out), in-
memory, key-value cache.
35. Table 1. Bucket types in Couchbase Server
Bucket
type
Description
Designed to be used alongside other database platforms
such as relational database technology.
By caching frequently-used data, they reduce the number
of queries a database server must perform for web
servers delivering a web application.
Important: With memcached buckets, the server provides only in-RAM
storage and data does not persist on disk. If Couchbase Server runs out
of space in the bucket’s RAM quota, it uses the Least Recently Used
(LRU) algorithm to evict items from the RAM. This means the server
removes the key, metadata, and all other data for the item from the
RAM. Once evicted, you cannot retrieve the item.
The different bucket types support different capabilities.
Table 2. Bucket types and supported capabilities
Capability Memcached buckets Couchbase buckets
Item size limit 1 MB 20 MB
Persistence No Yes
Replication No Yes
Rebalance No Yes
Statistics Limited set for in-memory
statistics
Full suite
Client support Ketama consistent hashing Full smart client
support
XDCR No Yes
Backup No Yes
TAP/DCP No Yes
36. Table 2. Bucket types and supported capabilities
Capability Memcached buckets Couchbase buckets
Encrypted data
access
Yes Yes
Couchbase buckets provide a highly-available and dynamically
reconfigurable distributed data store. They survive node failures and
allow cluster reconfiguration while continuing to service requests.
Table 3. Couchbase bucket capabilities
Couchbase
bucket
capability
Description
Caching Couchbase buckets operate through RAM. The data is
stored in RAM and persisted to disk. The data is cached in
RAM until the configured RAM is exhausted and data is
ejected from the RAM. If the requested data is not
currently in the cache (RAM), it will be loaded
automatically from disk.
Persistence Couchbase server persists data objects asynchronously
from memory to hard disk. This provides protection from
server restarts. You can set persistence properties at the
bucket level.
Replication You can configure the number of replica servers that
receive copies of all data objects. If the host machine fails,
a replica server is promoted to be the host server,
providing high availability cluster operations via failover.
You can configure replication at the bucket level.
Rebalancing Rebalancing enables load distribution across resources
and dynamic addition or removal of buckets and servers
in the cluster.
Bucket authentication
37. Bucket authentication
Both Memcached and Couchbase buckets allow anonymous access
and support SASL authentication.
SASL buckets: You can access SASL authenticating Couchbase
buckets through port 11210. Each bucket is identified by its name and
password, and you can use vBucket aware smart clients (SDKs) to
access a SASL bucket. You cannot use legacy ASCII clients to reach
these buckets.
Non-SASL buckets: You can place non-SASL buckets on any
available port except port 11211, which is reserved for the default
bucket. Port numbers are unique and help identify the buckets.
Hence, you can place only one non-SASL bucket on any individual
port. You can access non-SASL buckets using vBucket aware smart
client (SDKs), as ASCII client or a binary client that does not use
SASL authentication.
Smart clients discover changes in the cluster using the Couchbase
Management REST API. Using SASL buckets you can isolate individual
applications to provide multi-tenancy, or isolate data types in the cache
to enhance performance and visibility. Using the Couchbase Server,
you can configure different ports to access one of the following:
non-SASL buckets
isolated buckets using the binary protocol with SASL authentication,
or
isolated buckets using the ASCII protocol with no authentication
You can use a mix of bucket types (Couchbase and memcached) in
your environment. Buckets of different types share the same resource
pool and cluster resources.
You can configure the quotas for RAM and disk usage per bucket,
enabling you to manage resource usage across the cluster. As an
administrator, you can modify quotas on a running cluster and re-
allocate resources when usage patterns or priorities change.
The default bucket
The default bucket
38. The default bucket is a special bucket in Couchbase Server. When you
first install Couchbase Server, the default bucket is optionally set up
during installation. The default bucket is a non-SASL authenticating
bucket that always resides on port 11211. You can remove the default
bucket after installation and re-add it at a later time. When re-adding the
default bucket, ensure that you place it on port 11211 and it must be a
non-SASL authenticating bucket. You can access the default bucket
using vBucket aware smart client (SDKs), an ASCII client, or a binary
client that does not use SASL authentication.
Parent topic: Services Architecture and Multidimensional Scaling
CONTACT
LinkedIn
Twitter
Facebook
vBuckets and vBucket Maps:
Bucket Partitions
vBuckets help distribute data effectively across a cluster and support
replicas on more than one node.
A vBucket is the owner of a subset of the key disk space of a
Couchbase cluster. Although vBuckets are not user-accessible
components, they are a critical component of the Couchbase Server
and are vital to support high availability and elasticity.
You can access the information stored in a bucket by communicating
directly with the node responsible for the corresponding vBucket. This
direct access enables clients to communicate with the node storing the
data, rather than using a proxy or redistribution architecture. The result
abstracts the physical topology from the logical partitioning of data,
giving Couchbase Server its elasticity and flexibility.
Every document ID belongs to a vBucket. A mapping function is used to
calculate the vBucket in which a given document belongs. In
Couchbase Server, that mapping function is a hashing function that
takes a document ID as input and generates a vBucket identifier as the
output. After the vBucket identifier is computed, a table is consulted to
39. lookup the server that “hosts” that vBucket. The table containing one
row per vBucket provides a pairing between the vBucket and its hosting
server. A server appearing in this table can be responsible for multiple
vBuckets.
Consider a scenario where a cluster contains three servers. The
following diagram shows how the Key to Server mapping (vBucket
mapping) works when a client looks up the value of KEY using the GET
operation.Figure 1. vBucket mapping using the GET operation
1. By hashing the key, the client calculates the vBucket which
owns KEY. In this example, the hash resolves to vBucket 8
(vB8).
2. The client examines the vBucket map to determine that Server
C hosts vB8.
3. The client sends the GET operation directly to Server C.
Consider a second scenario where a server is added to the original
cluster of three servers. After adding a new node, Server D, to the
cluster, the vBucket map is updated during the rebalance operation.
The updated map is then sent to all the cluster participants including
other nodes, any connected smart clients, and the Moxi proxy service.
The following diagram shows the vBucket mapping for the updated
cluster containing four nodes.Figure 2. vBucket mapping using the GET
operation
40. When a client looks up the value of KEY using the GET operation in the
updated cluster, the hashing algorithm still resolves to vBucket 8 (vB8).
However, the new vBucket map maps vB8 to Server D. The client then
sends the GET operation directly to Server D.
Note:This architecture enables Couchbase Server to cope with
changes without using the typical RDBMS sharding method.
Additionally, this architecture is different from the method used by
Memcached as it uses client-side key hashes to determine the server
from a defined list. The memcached method, on the other hand,
requires active management of the list of servers and specific hashing
algorithms such as Ketama to cope with changes to the topology.
Parent topic: Services Architecture and Multidimensional Scaling
CONTACT
LinkedIn
Twitter
Bucket Disk Storage
When storing data in a Couchbase bucket, the server first writes data to
the caching layer and eventually stores all data to disk to provide a
higher level of reliability.
The Couchbase Server first writes data to the caching layer and puts
the data into a disk write queue to be persisted to disk. Disk persistence
enables you to perform backup and restore operations and to grow your
datasets larger than the built-in caching layer. This disk storage process
41. is called eventual persistence because the server does not block a
client while it writes to disk.
If a node fails and all data in the caching layer is lost, the items can be
recovered from disk. When the server identifies an item that needs to be
loaded from disk because it is not in active memory, it places it in a load
queue. A background process processes the load queue and reads the
information back from disk and into memory. The client waits until the
data is loaded back into memory before returning the information.
Multiple readers and writers
Multithreaded readers and writers provide simultaneous read and
write operations for data on disk. Simultaneous reads and writes
increase I/O throughput. The multithreaded engine includes
additional synchronization among threads that are accessing the
same data cache to avoid conflicts. To maintain performance
while avoiding conflicts over data, Couchbase Server uses a form
of locking between threads and thread allocation among vBuckets
with static partitioning.
When Couchbase Server creates multiple reader and writer
threads, the server assesses a range of vBuckets for each thread
and assigns each thread exclusively to certain vBuckets. With this
static thread coordination, the server schedules threads so that
only a single reader and single writer thread can access the same
vBucket at any given time. The following diagram shows six pre-
allocated threads and two data buckets. Each thread has the
range of vBuckets that is statically partitioned for read and write
access.Figure 1. Bucket disk storage
42. Item deletion
Items can be deleted explicitly by the client applications or
deleted using an expiration flag. Couchbase Server never deletes
items from disk unless one of these operations are performed.
However, after deletion or expiration, a tombstone is maintained
as the record of deletion. Tombstones help communicate the
deletion or the expiration to downstream components. Once all
downstream components have been notified, the tombstone gets
purged as well.
Tombstone purging
Tombstones are records of expired or deleted items that include
item keys and metadata.
43. Couchbase Server and other distributed databases maintain
tombstones in order to provide eventual consistency between
nodes and between clusters. Tombstones are records of expired
or deleted items and they include the key for the item and
metadata. Couchbase Server stores the key plus several bytes of
metadata per deleted item in two structures per node. With
millions of mutations, the space taken up by tombstones can
grow quickly. This is especially the case if there are a large
number of deletions or expired documents.
The Metadata Purge Interval sets frequency for a node to
permanently purge metadata of deleted and expired items. The
Metadata Purge Interval setting runs as part of auto-compaction.
This helps reduce the storage requirement by roughly 3x times
than before and also frees up space much faster.
Parent topic: Services Architecture and Multidimensional Scaling
CONTACT
LinkedIn
Twitter
Facebook
Database Engine Architecture
The memory-first architecture of the Couchbase Server enables it to
maintain sub-millisecond latencies with core data access.
The Couchbase Server depends on the following key components:
A highly efficient listener that manages networking and
authentication.
A bucket engine that stores and retrieves information at the speed of
memory access.
With Couchbase buckets, data is stored on disk eventually through the
storage engine. The storage engine enables the server to efficiently
hold data much larger than the size of memory.Figure 1. Database
engine architecture
44. Listeners
Listeners
When client connection requests arrive at the database engine, the listener
service receives the requests and authenticates the client. Upon successful
authentication, the listener service assigns a worker thread to the connection to
service its request. A single worker thread can handle multiple client
connections using a non-blocking event loop.
The number of worker threads that can be created is automatically determined
based on the number of CPU threads present on the node. By default the
number of worker threads is 0.75 x number of CPU threads.
vBucket manager and managed cache
vBucket manager and managed cache
After executing mutation and read requests, the server uses the managed cache
to hold updated and newly created values. However, with a high flow of
incoming operations, the system can run out of memory quickly. In order to
reuse the memory, mutations are also queued for disk persistence. Once the
mutated items are persisted, the server frees up the memory consumed by these
items, making space for newer operations. This operation is called cache
eviction. With a highly concurrent set of operations consuming memory and a
45. high throughput disk subsystem persisting data to disk, there can be many
pages eligible for reuse. The server uses the Least Recently Used (LRU)
algorithm to identify the memory pages that can be reused.
It is important to size the RAM capacity appropriately for your working set: the
portion of data that your application is working with at any given point in time
and needs very low latency and high throughput access. In some applications,
the working set is the entire data set, while in others it is a smaller subset.
Initialization and Warmup
Initialization and Warmup
Whenever you restart the Couchbase Server or restore the data, the node goes
through a warmup process before it starts handling data requests again. During
warmup, the Couchbase Server loads data persisted on disk into RAM.
Couchbase Server provides an optimized warmup process that loads data
sequentially from disk into RAM. It divides the data to be loaded and
handles it in multiple phases. After the warmup process completes, the
data is available for clients to read and write. The time needed for a node
warmup depends on the system size, system configuration, the amount of
data persisted in the node, and the ejection policy configured for the
buckets.
Note:The Couchbase Server is capable of serving data before it actually
loads all the keys and data from the vBuckets.
Couchbase Server identifies items that are frequently used, prioritizes them,
and loads them before sequentially loading the remaining data. The frequently-
used items are prioritized in an access log. The server performs a prefetch to
get a list of the most frequently accessed keys and then fetches these keys
before fetching any other items from disk.
The server runs a configurable scanner process that determines the keys that
are most frequently used. The scanner process is preset and is configurable.
You can use the command-line tool,cbepctl flush_param, to change the
initial time and interval for the scanner process. For example, you can
configure the scanner process to run during a specific time period when a given
list of keys need to be identified and made available sooner.
The server can also switch into a ready mode before it has actually retrieved all
documents for keys into RAM, thereby enabling data to be served before all the
46. stored items are loaded. Switching into ready mode is a configurable setting
that enables you to adjust the server warmup time.
Tunable Memory with Ejection Policy
Tunable Memory with Ejection Policy
Tunable memory enables you to configure the ejection policy for a bucket
as one of the following:
Value-only ejection (default) removes data from the cache but keeps all
keys and metadata fields for non-resident items. When a value bucket
ejection occurs, the value of the item is reset. Value-only ejection, also
referred to as value ejection, is well suited for cases where low latency
access is critical to the application and the total item keys for the bucket
can easily fit in the allocated Data RAM quota.
Full metadata ejection removes all data including keys, metadata, and
key-value pairs from the cache for non-resident items. Full ejection is
well suited for cases where the application has cold data that is not
accessed frequently or the total data size is too large to fit in memory
plus higher latency access to the data is accepted. The performance of
full eviction cache management is significantly improved by Bloom
filters. Bloom filters are enabled by default and cannot be disabled.
Important
Note:Full ejection may involve additional disk I/O per operation. For
example, when the request get_miss which requests a key that does not
exist is received, Couchbase Server will check for the key on the disk
even if the bucket is 100% resident.
Working Set Management and Ejection
Working Set Management and Ejection
Couchbase Server actively manages the data stored in a caching layer; this
includes the information which is frequently accessed by clients and which
needs to be available for rapid reads and writes. When there are too many items
in RAM, Couchbase Server removes certain data to create free space and to
maintain system performance. This process is called “working set
management” and the set of data in RAM is referredto as the “working set”. In
general, the working set consists of all the keys, metadata, and associated
documents which are frequently used require fast access. The process the
server performs to remove data from RAM is known as ejection.
47. Couchbase Server performs ejections automatically. When ejecting
information, it works in conjunction with the disk persistence system to ensure
that data in RAM is persisted to disk and can be safely retrieved back into
RAM whenever the item is requested.
In addition to the Data RAM quota for the caching layer, the engine uses two
watermarks, mem_low_wat andmem_high_wat, to determine when it
needs to start persisting more data to disk.
As more and more data is held in the caching layer, at some point in time it
passes the mem_low_wat value. At this point, no action is taken. As data
continues to load, it eventually reaches the mem_high_wat value. At this
point, the Couchbase Server schedules a background job called item pager
which ensures that items are migrated to disk and memory is freed up for
other Couchbase Server items. This job runs until measured memory
reaches mem_low_wat. If the rate of incoming items is faster than the
migration of items to disk, the system returns errors indicating there is not
enough space until there is sufficient memory available. The process of
migrating data from the cache to make way for actively used information is
called ejection and is controlled automatically through thresholds set on
each configured bucket in the Couchbase Server cluster.Figure 2. Working
set management and ejection
Depending on the ejection policy set for the bucket, the vBucket Manager
removes just the document or both the document, key and the metadata
for the item being ejected. Keeping an active working set with keys and
metadata in RAM serves three important purposes in a system:
48. Couchbase Server uses the remaining key and metadata in RAM if a
client requests for that key. Otherwise, the node tries to fetch the item
from disk and return it into RAM.
The node can also use the keys and metadata in RAM for miss access.
This means that it can quickly determine whether an item is missing and
if so, perform some action, such as add it.
The expiration process in Couchbase Server uses the metadata in RAM
to quickly scan for items that have expired and later removes them from
disk. This process is known as expiry pager and runs every 60 minutes
by default.
Not Recently Used (NRU) Items
Not Recently Used (NRU) Items
All items in the server contain metadata indicating whether the item has been
recently accessed or not. This metadata is known as not-recently-used (NRU).
If an item has not been recently used, then the item is a candidate for ejection.
When data in the cache exceeds the high water mark (mem_high_wat), the
server evicts items from RAM.
Couchbase Server provides two NRU bits per item and also provides a
replication protocol that can propagate items that are frequently read, but not
mutated often.
NRUs are decremented or incremented by server processes to indicate an
item that is more frequently or less frequently used. The following table
lists the bit values with the corresponding scores and statuses:
Table 1. Scoring for NRU bit values
Binary
NRU
Score Access pattern Description
00 0 Set by write access to 00.
Decremented by read access or no
access.
Most heavily used
item.
01 1 Decremented by read access. Frequently
accessed item.
10 2 Initial value or decremented by Default value for
49. Table 1. Scoring for NRU bit values
Binary
NRU
Score Access pattern Description
read access. new items.
11 3 Incremented by item pager for
eviction.
Less frequently
used item.
There are two processes that change the NRU for an item:
When a client reads or writes an item, the server decrements NRU and
lowers the item's score.
A daily process which creates a list of frequently-used items in RAM.
After the completion of this process, the server increments one of the
NRU bits.
Because these two processes change NRUs, they play an important role in
identifying the candidate items for ejection.
You can configure the Couchbase Server settings to change the behavior during
ejection. For example, you can specify the percentage of RAM to be consumed
before items are ejected, or specify whether ejectionshould occur more
frequently on replicated data than on original data. Couchbase recommends
that the default settings be used.
Understanding the Item Pager
Understanding the Item Pager
The item pager process runs periodically to remove documents from RAM.
When the amount of RAM used by items reaches the high water mark (upper
threshold), both active and replica data are ejected until the amount of RAM
consumed (memory usage) reaches the low water mark (lower threshold).
Evictions of active and replica data occur with the ratio probability of 60%
(active data) to 40% (replica data) until the memory usage reaches the low
watermark. Both the high water mark and low water mark are expressed as a
percentage amount of RAM, such as 80%.
You can change the high water mark and low water mark settings for a
node by specifying a percentage amount of RAM, for example, 80%.
Couchbase recommends that you use the following default settings:
Table 2. Default setting for RAM water marks
50. Version High water mark Low water mark
2.0 75% 60%
2.0.1 and higher 85% 75%
The item pager ejects items from RAM in two phases:
1. Eject items based on NRU: The item pager scans NRU for items,
creates a list of items with a NRU score 3, and ejects all the
identified items. It then checks the RAM usage and repeats the
process if the usage is still above the low water mark.
2. Eject items based on algorithm: The item pager increments the
NRU of all items by 1. For every item whose NRU is equal to 3, it
generates a random number. If the random number for an item is
greater than a specified probability, it ejects the item from RAM.
The probability is based on the current memory usage, low water
mark, and whether a vBucket is in an active or replica state. If a
vBucket is in an active state, the probability of ejection is lower
than if the vBucket is in a replica state.
Table 3. Probability of ejection based on active vBuckets versus
replica vBuckets
Active vBucket Replica vBucket
60% 40%
Active Memory Defragmenter
Active Memory Defragmenter
Over time, the memory used by the managed cache of a running Couchbase
Server can become fragmented. The storage engine now includes an Active
Defragmenter task to defragment cache memory.
Cache fragmentation is a side-effect of how Couchbase Server organizes cache
memory to maximize performance. Each page in the cache is typically
responsible for holding documents of a specific size range. Over time, if
memory pages assigned to a specific size range become sparsely populated
(due to documents of that size being ejectedor items changing in size), then the
unused space in those pages cannot be used for documents of other sizes until a
complete page is free and that page is re-assigned to a new size. Such effects
51. are highly workload dependent and can result in memory that cannot be used
efficiently by the managed cache.
The Active Memory Defragmenter attempts to address any fragmentation by
periodically scanning the cache to identify pages which are sparsely used, and
repacking the items stored on those pages to free up whole pages.
High Performance Storage
High Performance Storage
The scheduler and the shared thread pool provide high performance storage to
the Couchbase Server.
Scheduler
The scheduler is responsible for managing a shared thread-pool
and providing a fair allocation of resources to the jobs waiting to
execute in the vBucket engine. Shared thread pool services
requests across all buckets.
As an administrator, you can govern the allocation of resources
by configuring a bucket’s disk I/O prioritization setting to be either
high or low.
Shared thread pool
A shared thread pool is a collection of threads which are shared
across multiple buckets for long running operations such as disk
I/O. Each node in the cluster has a thread pool that is shared
across multiple vBuckets on the node. Based on the number of
CPU cores on a node, the database engine spawns and allocates
threads when a node instance starts up.
Using a shared thread pool provides the following benefits:
Better parallelism for worker threads with more efficient I/O
resource management.
Better system scalability with more buckets being serviced with
fewer worker threads.
Availability of task priority if the disk bucket I/O priority setting is
used.
Disk I/O priority
Disk I/O priority
Disk I/O priority enables workload priorities to be set at the bucket level.
52. You can configure the bucket priority settings at the bucket level and set the
value to be either high or low. Bucket priority settings determine whether I/O
tasks for a bucket must be queued in the low or high priority task queues.
Threads in the global pool poll the high priority task queues more often than
the low priority task queues. When a bucket has a high priority, its I/O tasks are
picked up at a higher frequency and thus, processed faster than the I/O tasks
belonging to a low priority bucket.
You can configure the bucket I/O priority settings during initial setup and
change the settings later, if needed. However, changing a bucket I/O
priority after the initial setup results in a restart of the bucket and the
client connections are reset.Figure 3. Create bucket settings
53.
54. The previous versions of Couchbase Server, version 3.0 or earlier, required
the I/O thread allocation per bucket to be configured manually. However,
when you upgrade from a 2.x version to a 3.x or higher version, Couchbase
Server converts an existing thread value to either a high or low priority
based on the following criteria:
Buckets allocated six to eight (6-8) threads in Couchbase Server 2.x are
marked high priority in bucket setting after the upgrade to 3.x or later.
Buckets allocated three to five (3-5) threads in Couchbase Server 2.x are
marked low priority in bucket settings after the upgrade to 3.x or later.
Monitoring Scheduler
Monitoring Scheduler
You can use the cbstats command with the raw workload option to
view the status of the threads as shown in the following example.
# cbstats 10.5.2.54:11210 -b default raw workload ep_workload:LowPrioQ
ep_workload:LowPrioQ_AuxIO:OutQsize: 0 ep_workload:LowPrioQ_NonIO:InQsize:
ep_workload:LowPrioQ_Reader:InQsize: 12 ep_workload:LowPrioQ_Reader:OutQsiz
ep_workload:LowPrioQ_Writer:OutQsize: 0 ep_workload:num_auxio:
ep_workload:num_readers: 1 ep_workload:num_shards:
ep_workload:num_writers: 1 ep_workload:ready_tasks:
ep_workload:shard0_pendingTasks: 0 ep_workload:shard1_locked:
ep_workload:shard2_locked: false ep_workload:shard2_pendingTasks:
ep_workload:shard3_pendingTasks: 0
Bloom Filters
A Bloom filter is a probabilistic data structure used to test whether an
element is a member of a set. False positive matches are possible, but
false negatives are not. This means a query returns either "possibly in
set" or "definitely not in set". It is a bit array with a predefined size that is
calculated based on the expected number of items and the probability of
false positives or the probability of finding a key that doesn't exist.
Bloom filter significantly improves the performance of full ejection
scenarios and XDCR.
In the full ejection mode, the key and metadata are evicted along with
the value. Therefore, if a key is non resident, there is no way of knowing
if a key exists or not, without accessing the disk. In such a scenario, if a
client issues a lot of GETs on keys that may not even exist in server,
Bloom filters help eliminate many unnecessary disk accesses. Similarly
55. for XDCR, when we set up remote replication to a brand new cluster,
we would be able to avoid many unnecessary GetMeta-disk-fetches
with the help of the bloom filter.
With Bloom filters, the probability of false positives decreases as the
size of the array increases and increases as the number of inserted
elements increases. Based on the algorithm that takes into account the
number of keys and the probability of false positives, you can estimate
the size of the Bloom filter and the number of bits to store each key.
For value eviction only the deleted keys will be stored, while in case of
full eviction both the deleted keys and non-resident items will be stored.
The algorithm calculates the almost exact probability of false positives,
including the number of hash functions (k), size of the bit array (m), and
the number of inserted elements (n):
k = m/n (ln 2)
You can expect an increase in memory usage or memory overhead
while using the Bloom filter:
Table 1. Memory overhead for Bloom filter use
False positive
probability
0.01 0.05
Estimated number of keys 10,000.000 (=>
=10,000 keys per
vBucket)
10,000.000 (=>
=10,000 keys per
vBucket)
Number of bits per key in
the filter
7 bits 4 bits
Size of the Bloom filter to
fit the estimated keys
with desired false positive
probability
95851 bits (=> =12
KB per vBucket) (=>
=12 MB for 1024
vBuckets)
62353 bits (=> =8 KB
per vBucket) (=> =8
MB for 1024
vBuckets)
In a case of full eviction, you will not know whether an item exists in the
memory until you perform a background fetch. Therefore, use of the
56. Bloom filter helps to avoid unnecessary background fetches and
improves latency.
For more information about working set management and eviction,
see Database Engine Architecture
Parent topic: Services Architecture and Multidimensional Scaling
CONTACT
Sub-Document API
The sub-document API enables you to access parts of JSON
documents (sub-documents) efficiently without requiring the transfer of
the entire document over the network. This improves performance and
brings better efficiency to the network IO path, especially when working
with large JSON documents.
The key-value APIs in Couchbase operate on entire documents. In use
cases where small documents or binary values are used, operations
that retrieve and update the entire document are acceptable and
desirable. However, in use cases where large documents are used,
retrieving an entire document to read or update a single field isn't
practical. Modifying a single field involves retrieving the entire document
over the network, modifying the field locally, and then passing the
modified document back over the network to save it in the database.
Key-value APIs are well suited for binary values and small JSON
documents.
Note:The key-value APIs can also operate on binary formats which are
not supported by sub-document APIs. Append operations on binary
values are always atomic and do not retrieve the document to perform
the append.
With the addition of the sub-document API, you can now access and
operate on individual JSON fields, sub-document fragments, within a
larger JSON document. Consider the following example which uses a
sub-document API to retrieve just the last name from a user profile
JSON document.
57. Only the requested or modified fields are sent over the network as
opposed to the entire document being sent over the network when
using key-value APIs.
Note:The above example shows the underlying Memcache protocol
operations. The sub-document APIs are exposed through convenient
builder APIs in each of the SDKs. All sub-document operations are
atomic at the document level.
Atomically modifying fields within a JSON document is typically suited to
the following scenarios:
An application does not have the existing document available locally
and wishes to make a predetermined change to a specific field as
part of a routine operation. For example, incrementing a statistics
counter or a login counter.
An application already has the existing document available locally,
but wishes to use an atomic operation for modifying it, to save
bandwidth and be more efficient. For example, an existing web
session where the user modifies or stores some data such as an
updated profile or an updated score.
Cross-referencing scenarios, where an application-defined
relationship exists between two documents. In the context of social
gaming, this may be thought of as sending messages between
inboxes.
1. User #1 sends a message to User #2.
2. This may be implemented as: generate a key for the inbox
message, store it somewhere.
3. docAddValue(‘user:1’, ‘sent’, [‘user:2’,
‘keyToMessage’]
58. 4. docAddValue(‘user:2’, ‘inbox’, [‘user:1’,
‘keyToMessage’]
Note:The following blogs explain how the sub-document API is
expressed using different SDKs:
Java Walk-through of the Sub-document API
GO Walk-through of the Sub-document API
Consider a simple Java example that uses the sub-document API to
connect to the travel-sample bucket, fetch the name field from the
document “ airline_13633”, and then print it.
Fetch.java
// Fetch and print the name from an airline DocumentFragment<Lookup> resultLooku
bucket.lookupIn("airline_13633").get("name").doLookup(); LOGGER.info(resultLookup
The API for sub-document operations use the dot notation syntax to
identify the logical location of an attribute within a document. This is
also consistent with N1QL's path syntax to refer to individual fields in a
document. In the example below, the path to the last name field is
"name.last".
Updates to a field are atomic and do not collide with updates to a
different field on the same key. For example, the following operations do
not collide although they are updating the same document.
[Thread 1] bucket.mutateIn("user").upsert("name.last","Lennon",false).doM
bucket.mutateIn("user").upsert("email","jlennon@abc.com",false).doMutate();
Commands
Commands
This section lists the available sub-document commands. There are two
categories of commands exposed through builder APIs in the SDKs:
lookupIn commands which are used to read data from existing
documents.
mutateIn commands which are used to modify documents.
Sub-document commands are named similar to their full-document
counterparts, but they perform the logical key-value operation within a single
document rather than operating on the entire document. In addition to
retrieving and setting fields, the sub document API allows true "append" and
59. "prepend" operations on arrays, as well as increment and decrement operations
on numeric values.
Lookup Commands
There are two sub-document lookup commands - get and exists.
get returns a specific path from a single document. It can be used to
return any JSON primitive, assuming a suitable path is constructed. For
example, consider the following document from the travel-
sample dataset:
{ "id": 55136, "type": "route", "airline": "U2", "airlineid": "airline_22
"AMS", "stops": 0, "equipment”: [“320", "319”], “active": true, "schedule
"U2219" }, { "day": 1, "utc": "07:58:00", "flight": "U2839" }
Using the sub-document get command the following fields of varying
types can be returned via these paths:
"id" - 55136 (number) "active" - true (boolean) "schedule[0]" - { "day": 0, "ut
- ["320", "319"] (array)
The exists command is similar to get, except that it only checks for
the existence of a given path, and does not return the document fragment itself.
This command can be used to check if a particular path exists in a document,
without having to actually receive the fragment.
Mutation Commands
The sub-document API supports the addition of new fields, and modification or
deletion of existing fields in a JSON document. Different commands are used
depending on the type of the field being mutated.
Mutating Dictionary Fields
The sub-document API supports four commands on JSON dictionaries
(also known as objects):
Creating of a new name/value pair using insert.
Replacing an existing name/value pair using replace.
Creating a new name/value pair or replacement of an existing one
using upsert.
Deleting an existing name/value using remove.
60. The MutateDict.java example below shows the use of replace to update
the callsign field in for a particular airline document (which is
composed of a top-level dictionary):
Mutate.java
// Update CallSign for "Pan Am" to "Clipper" DocumentFragment<Mutation> resultMu
bucket.mutateIn("airline_13633").upsert("callsign","CLIPPER",false).doMutate();
resultLookup = bucket.lookupIn("airline_13633").get("callsign").doLookup(); LOGGE
Mutating Array Fields
The sub-document API supports a similar set of commands on arrays as on
dictionaries. It also adds the ability to push items to the beginning or the
end of an array, without having to explicitly check the current length of the
array.
Adding a new element to an array at a specific index
using arrayInsert.
Pushing a new element to the start or the end of an array
using pushFront or pushBack.
Replacing an existing index with a new value using replace.
Deleting an existing array element (reducing the array size by 1)
using remove.
Adding a new element only if the value is not already present in the
array using addUnique.
The ArraysAndDicts.java example below shows the use of upsert to
create a new " fleet" array in an existing document, and then appends
two new aircraft dictionaries (containing the aircraft name and engine
count) to the "fleet" array:
ArraysAndDicts.java
// Creates a "fleet" array and pushes aircraft into it bucket.mutateIn("airline_
JsonObject.create().put("name", "747-200B").put("heavy",true).put("engines",4),
200").put("engines",2) ), false).doMutate();
The sub-document API also supports enforcing that values are unique in an
array, which allows the construction ofmathematical sets.
The Unique.java example below shows an example of mathematical sets -
each airline has a models array recording what models of aircraft an
airline operates. There is a constraint that the elements in models should
be unique (a model shouldn’t appear more than once), so
the addUnique command is used when adding new models:
61. Unique.java
// Creates a "models" array and adds UNIQUE values into it
bucket.mutateIn("airline_13633").upsert("models",JsonArray.empty(),false).doMutat
bucket.mutateIn("airline_13633").addUnique("models","747-200B",false).addUnique("
The Array already contains the 747-120 try { bucket.mutateIn("airline_136
} catch (PathExistsException ex){ LOGGER.info("Whoops! Model is al
Arithmetic commands
The sub-document API allows basic arithmetic operations (addition and
subtraction) to be performed on integer fields in a document using
the counter command.
This allows simple counters to be implemented server-side, without the client
application having to explicitly fetch the field, update the numeric value and
then replace it back again. It also prevents the possibility of another client
attempting to perform the update at the same time and the increment or
decrement being lost.
Arithmetic operations can only be performed on integer numeric values which
can be represented as a signed 64 bit value (i.e. the C type int64_t) and the
delta being added or subtracted also needs to be an int64_t.
The Counter.java example below demonstrates the use of counter to
increment two fields -
passengers.servedand passengers.complained:
Counter.java
// Increment passenger_served counter on the airline bucket.mutateIn("airline_13
Simulate some randomness that a passenger complained while being served if (new R
bucket.mutateIn("airline_13633").counter("passengers.complained",1L,true).doMutat
Maintaining Data Consistency
Maintaining Data Consistency
When using key-value APIs, updates to a single field requires CAS to maintain
consistency. In case of highly contended documents, if a CAS mismatch occurs
the operation needs to be restarted even though the modified field remains the
same. Sub-document APIs do not require the use of CAS when updating single
fields. However, you can still use the CAS protectionfor the document if your
application requires it. For more information on CAS, see Concurrent
Document Mutations.
62. The application logic may require a document modification to be either:
Locally consistent with regards to the immediate parent object which
contains the value being modified. For example, ensure that a specific
object key is unique, or ensure that a specific list item is not duplicated.
Globally consistent with regards to the entire document. For example, if
the existence of one field in the document only makes sense when
another field is in a specific state.
In Couchbase Server 4.1 or earlier versions, both these scenarios require
the application to make use of CAS to ensure consistency. With the sub-
document API model, the local consistency requirement does not require
CAS as the server can ensure that the data is consistent atomically. For
global consistency requirements, you can use CAS through the SDKs to
ensure that a document's state has not already changed.
Multi-path Operations
Multi-path Operations
As demonstrated in the examples above, the sub-document API supports
operating on multiple paths in a single key with potentially different
commands. The builder APIs allow commands to be chained together for
efficiency. Multi-path operations can retrieve multiple disjoint fields from a
single key atomically. Multi-path operations can also modify multiple disjoint
fields from a single key atomically.
Important: A multi-path operation through either
the lookupIn or mutateIn builder APIs can only perform a retrieval or
a mutation, not both.
Sub-Document API Suitability
Sub-Document API Suitability
The sub-document API is a trade-off in server resource usage, between
CPU and network bandwidth. When using a sub-document command the
client only transmits the key, path and fragment to change, as opposed to
sending the key, and complete (whole) value. Depending on the size of the
document being operated on and the size of the fragment, this can result in
a significant saving of network bandwidth. For example, operating on a
100KB document named " user::j.bloggs" where a 30 byte fragment
is added to a path of length 20 bytes would require sending the following
over the network:
Size (bytes)
63. Header Key Path Value Total
Full document
(SET)
24 14 - 100,240 100,278
Sub-document
(SUBDOC_DICT_ADD)
24 14 20 30 88
In this example, there is a saving of 100,190 bytes using sub-document
compared to existing full document operations, or a 99.91% saving in
network bandwidth.
However, this bandwidth saving is only possible because the cluster node
performs the additional processing to handle this request. The cluster
node needs to parse the current JSON value for " user::j.bloggs",
apply the requested modification (inserting an element into a dictionary in
the above example), and then store the result. The exact CPU required for
this will vary considerably depending on a number of factors, including:
Size of the existing document.
Complexity (different levels of nesting, etc) of the existing document.
Type of sub-document operation being performed.
Size of the fragment being applied.
In general, sub-document API is a good fit for applications where network
bandwidth is at a premium, and at least one of the following is true:
The document being operated on is not very small.
The fragment being requested/modified is a small fraction of the total
document size.
Incremental MapReduce Views
MapReduce views (also called views) uses a user defined map and
reduce function that can define arbitrarily complex logic for indexing.
This makes views a powerful solution for interactive reporting queries
that require powerful reshaping of data that can provide responses at
low latencies.
Views process the map and reduce functions to precalculate and store
the answer, hence reducing the need for just-in-time calculations to