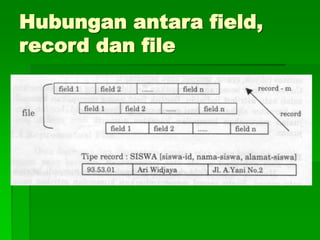
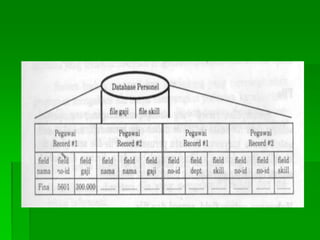
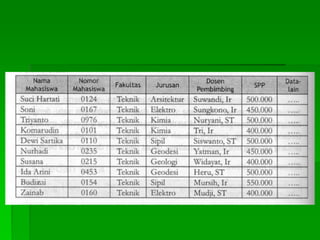
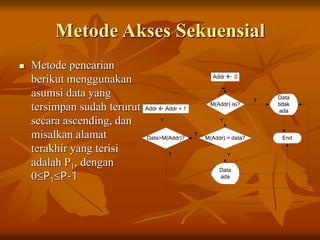
Dokumen ini membahas tentang sistem berkas, termasuk istilah-istilah seperti entitas, atribut, field, record, dan file. Ia menjelaskan metode organisasi file, termasuk akses langsung dan sekuensial, serta faktor-faktor yang mempengaruhi pemilihan metode penyimpanan dan pencarian yang efisien. Selain itu, dokumen ini juga mencakup penentuan ukuran memori dan pengukuran kinerja file.