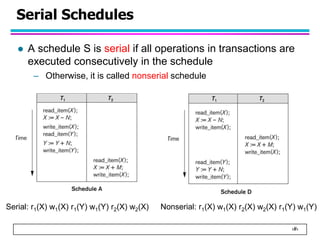
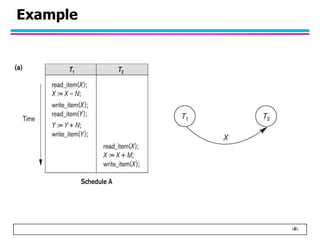
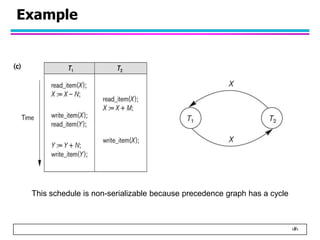
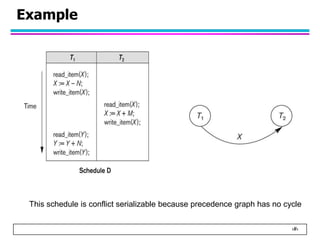
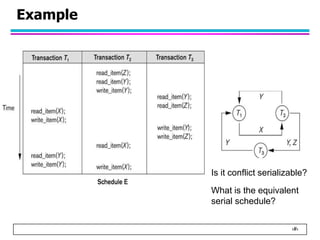
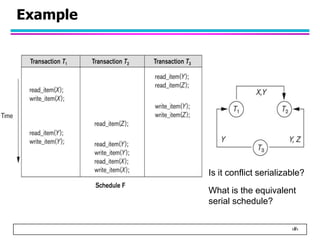
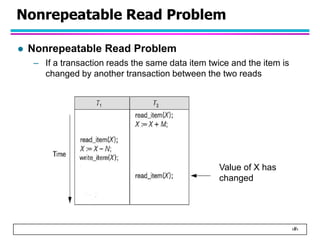
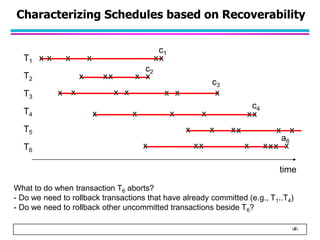
This document summarizes concurrency control in database systems. It discusses reasons for concurrency control such as the lost update, dirty read, and non-repeatable read problems. It introduces transaction scheduling and defines recoverable, cascadeless, strict, serializable, and conflict serializable schedules. Conflict serialization graphs are used to test whether a schedule is serializable. Maintaining serializable schedules ensures correctness when transactions execute concurrently.












![‹#›
Recovery using System Log
From previous lecture, if the database system crashes,
we can recover to a consistent database state by
examining the log
Example of entries in a log record (T: transaction ID)
1. [start_transaction,T4]
2. [read_item,T4.X]
3. [write_item,T4.X,4,11] (before image = 4, after image = 11)
4. [abort,T4]
– During recovery, we may undo the change in T4.X by using its
“before image” (i.e., replace new value 11 with old value 4)](https://image.slidesharecdn.com/lecture24-240227052915-f32f2bea/85/concurrencycontrol_databasemanagement_system-15-320.jpg)