Download to read offline

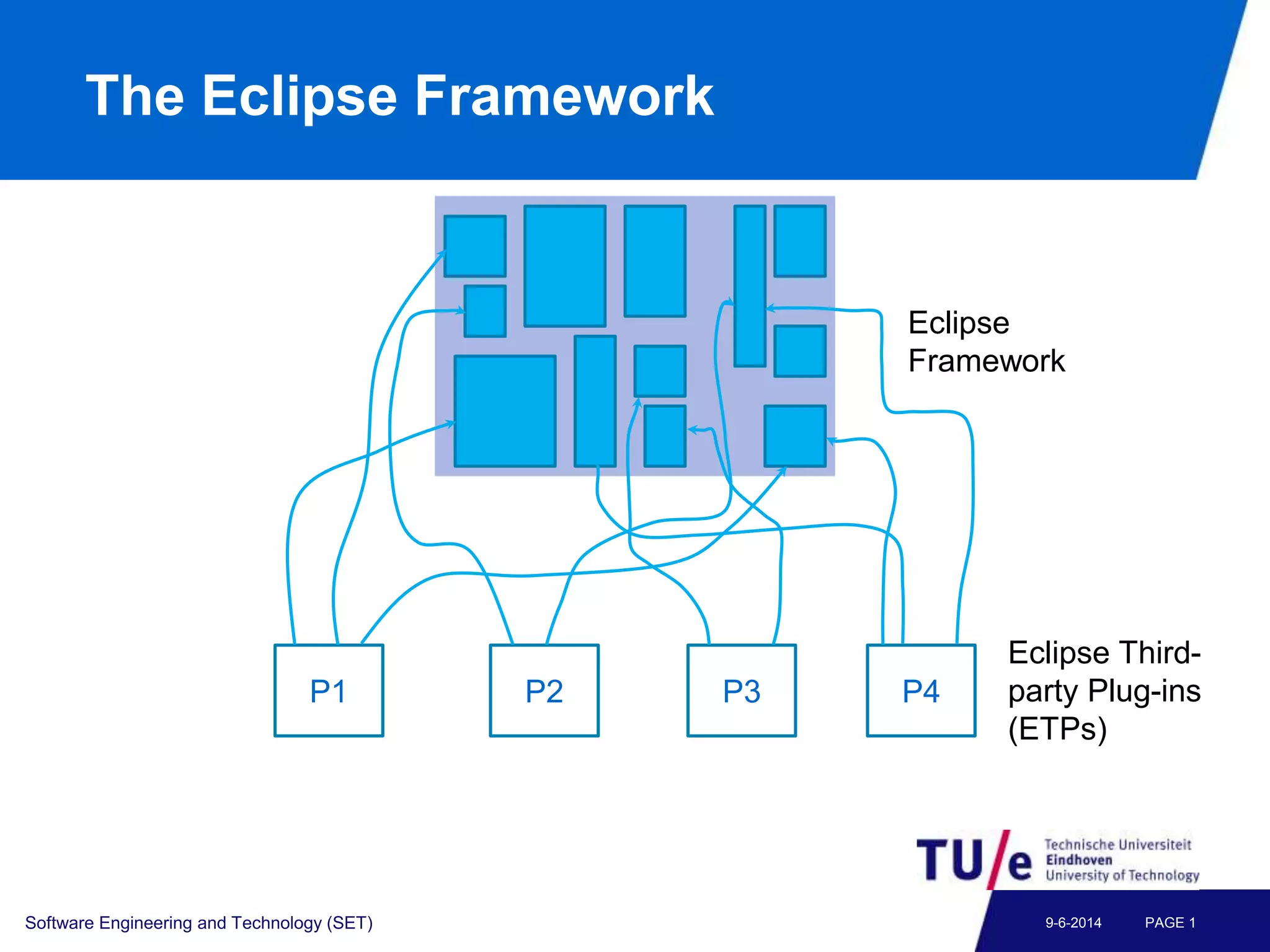
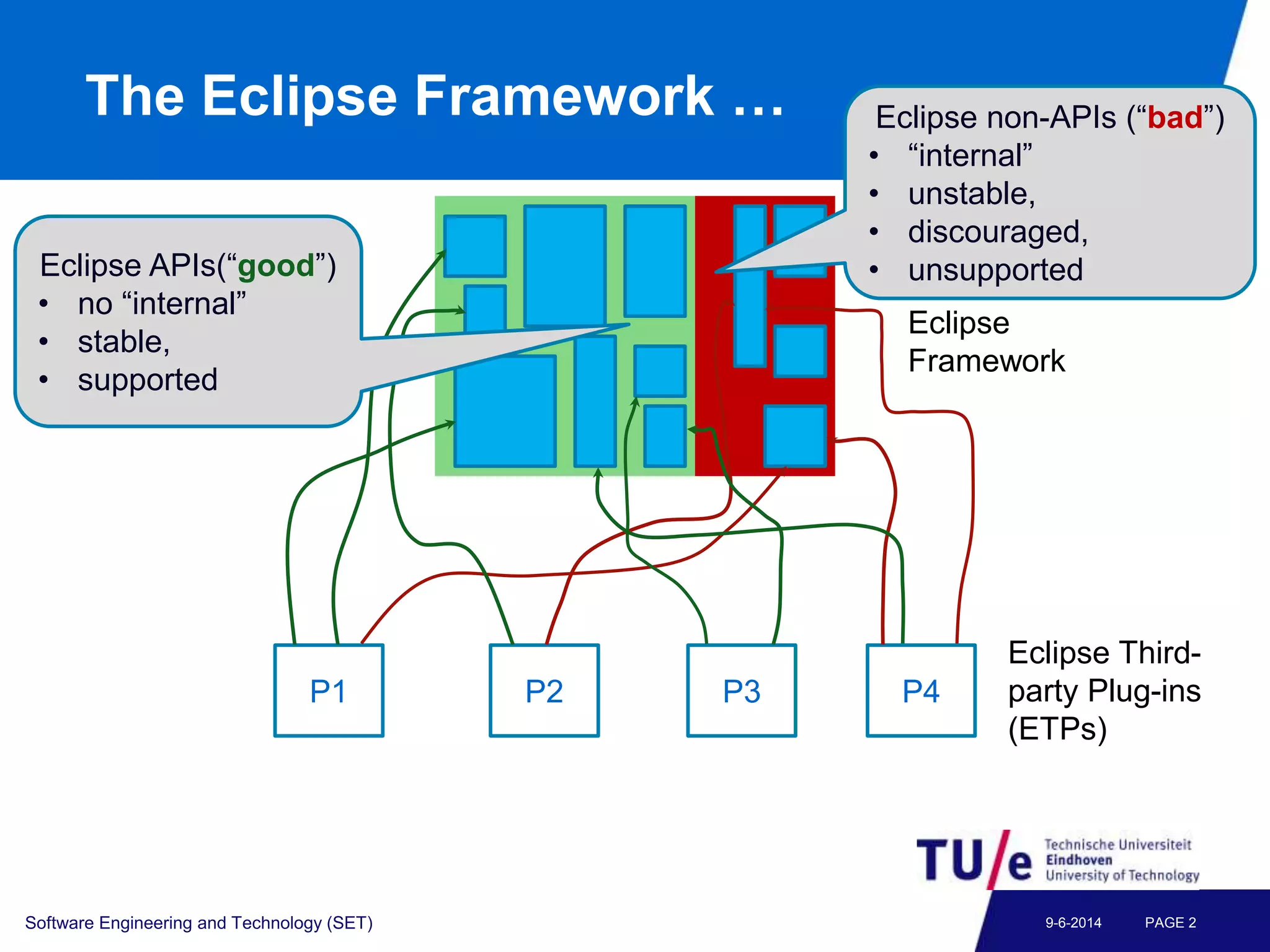
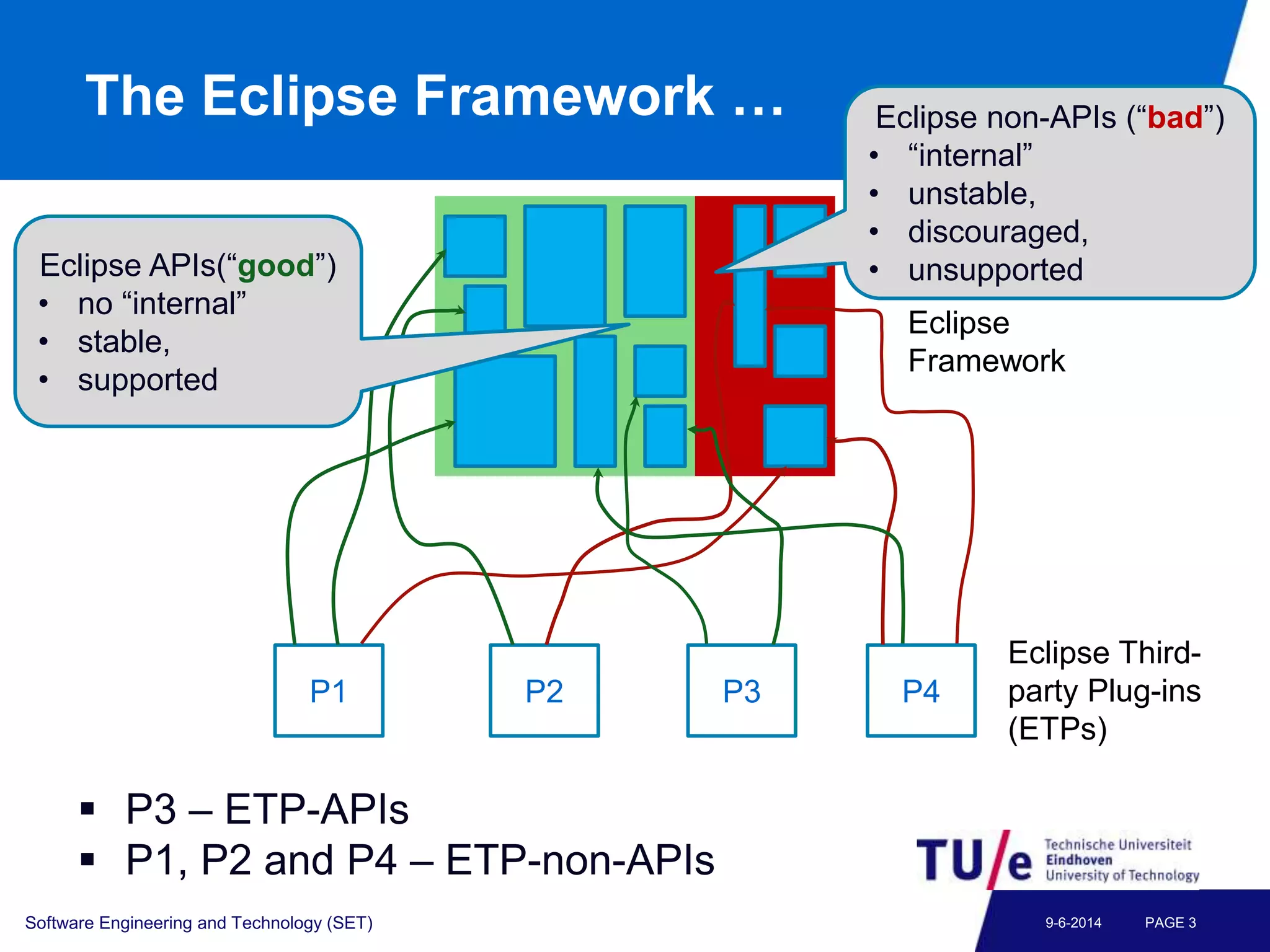



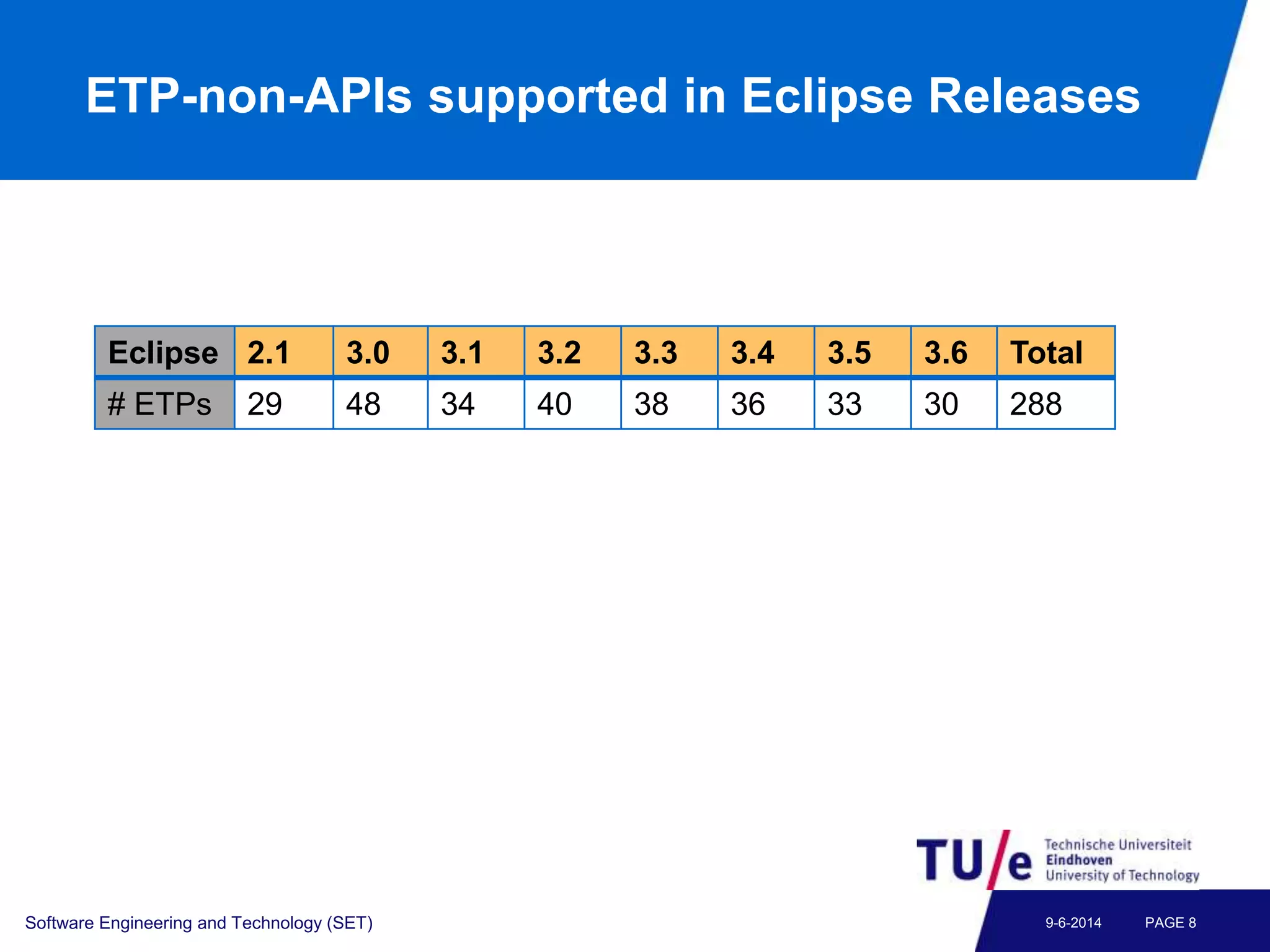






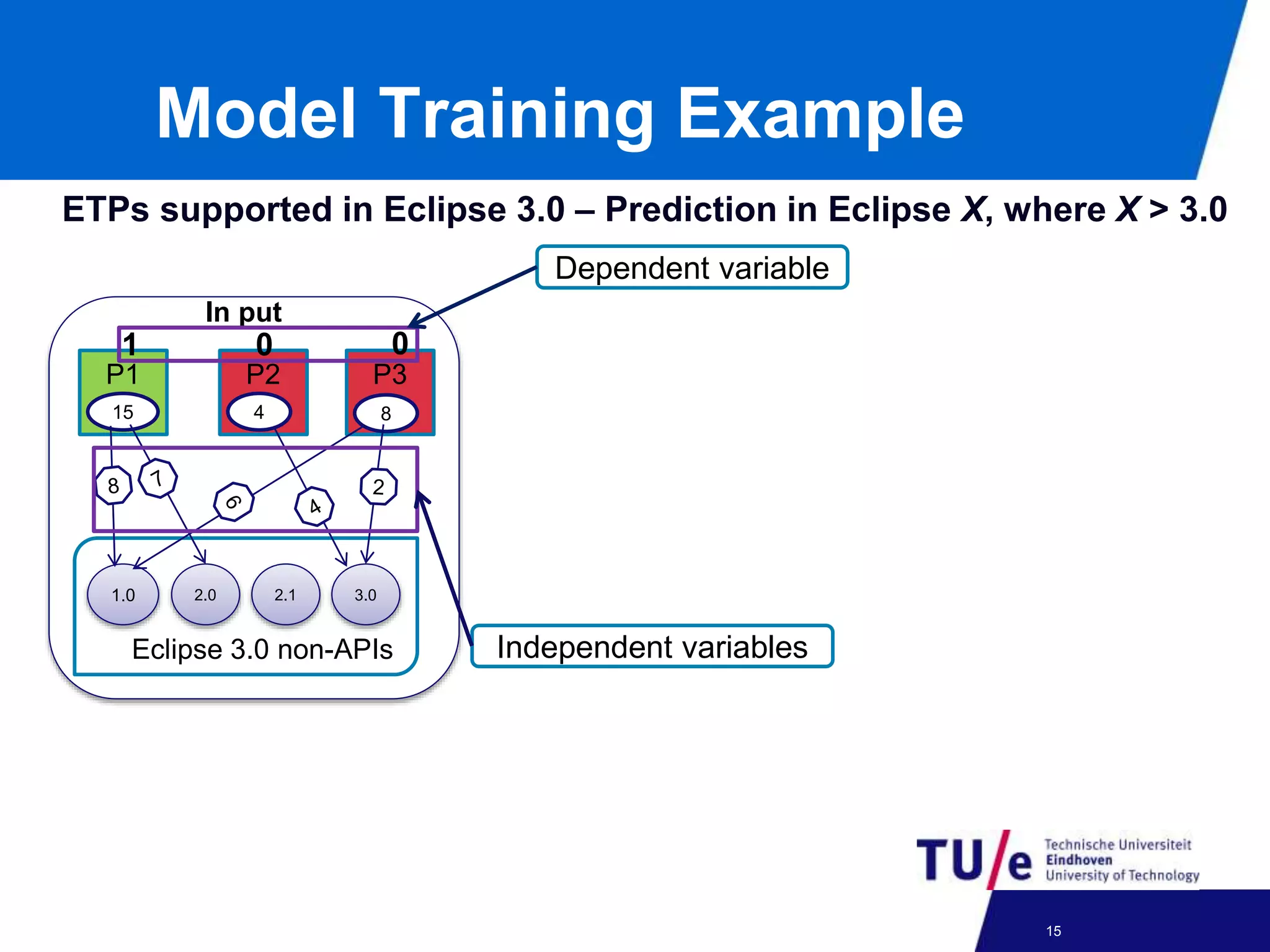
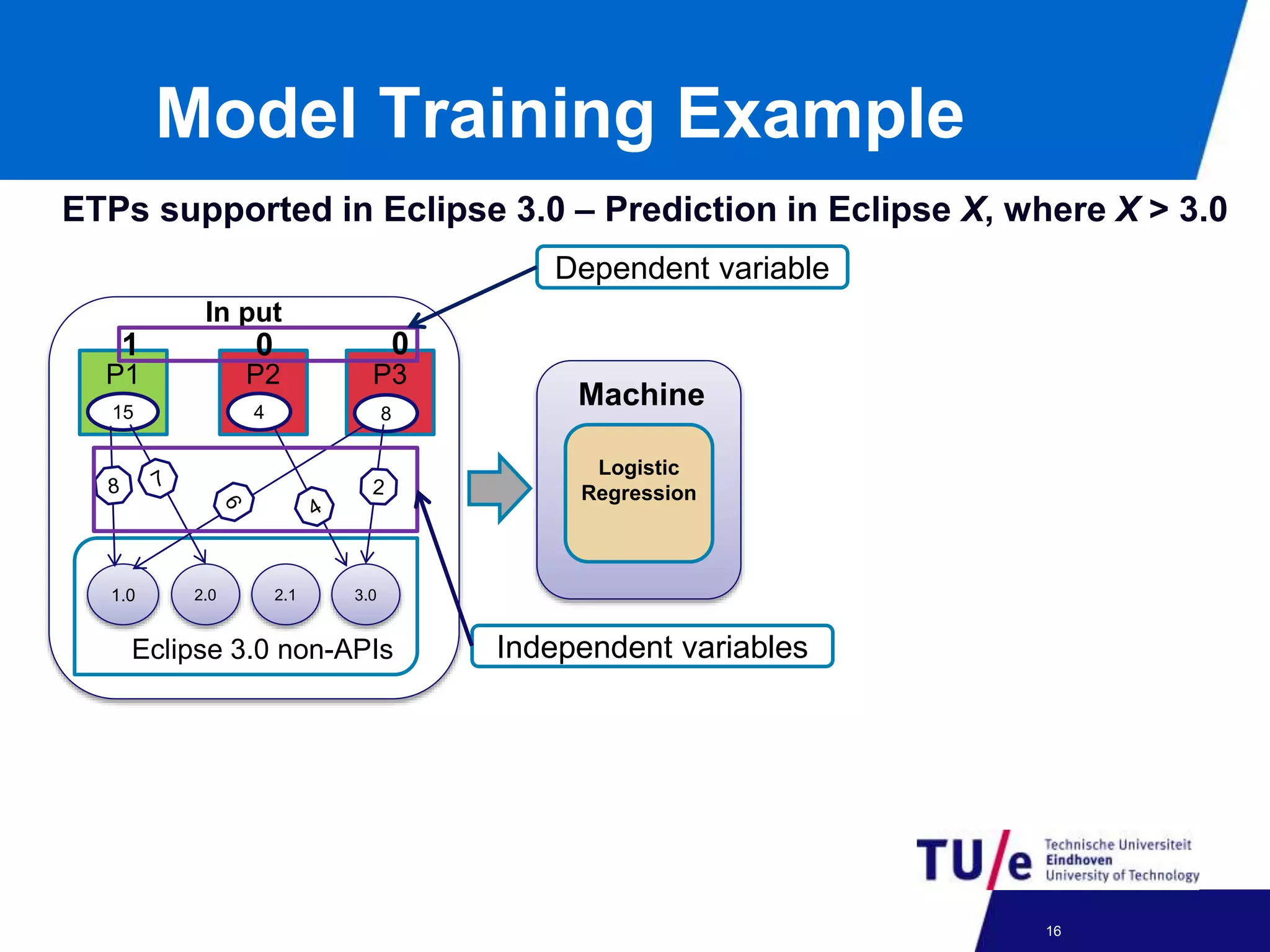
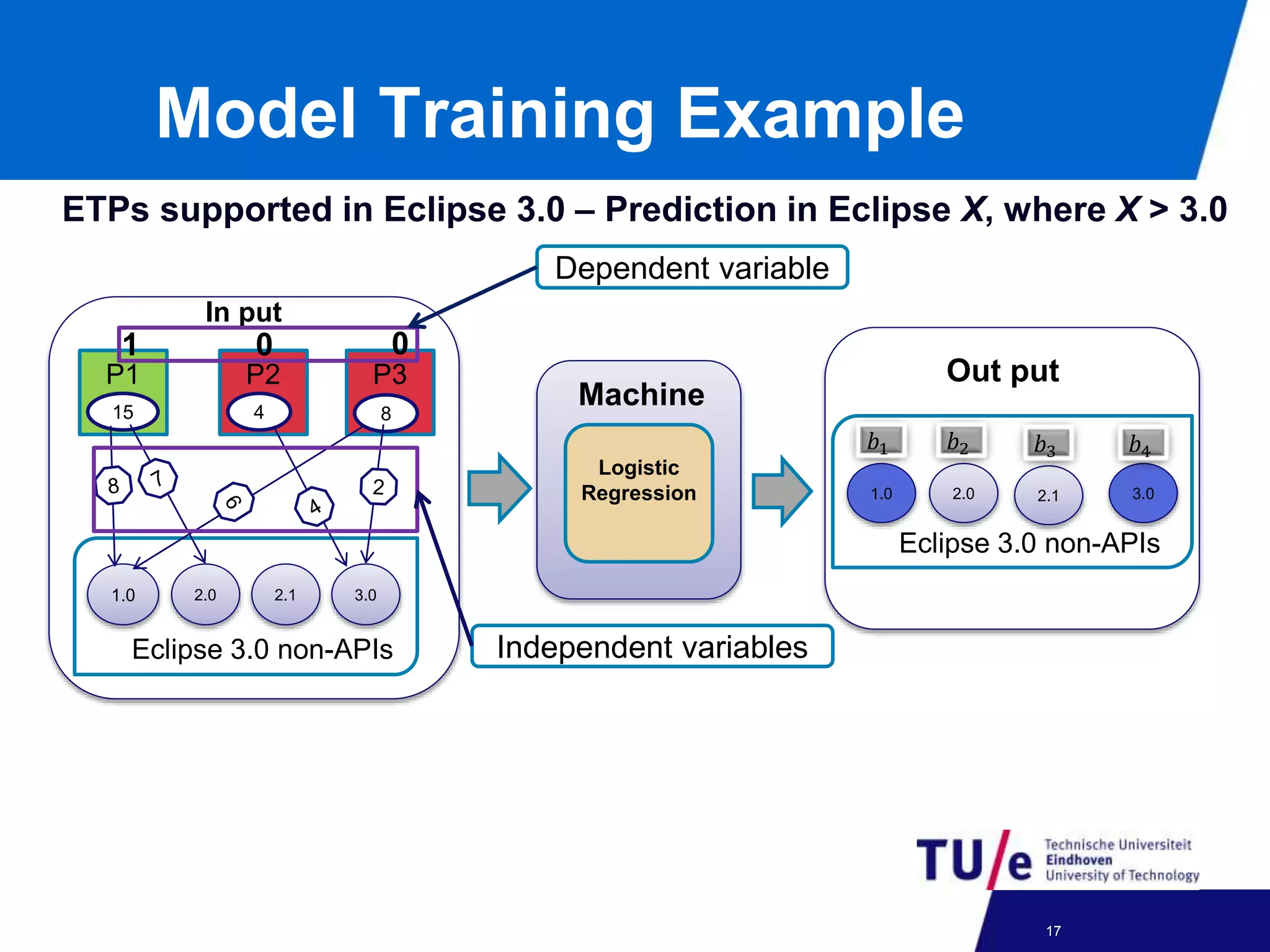
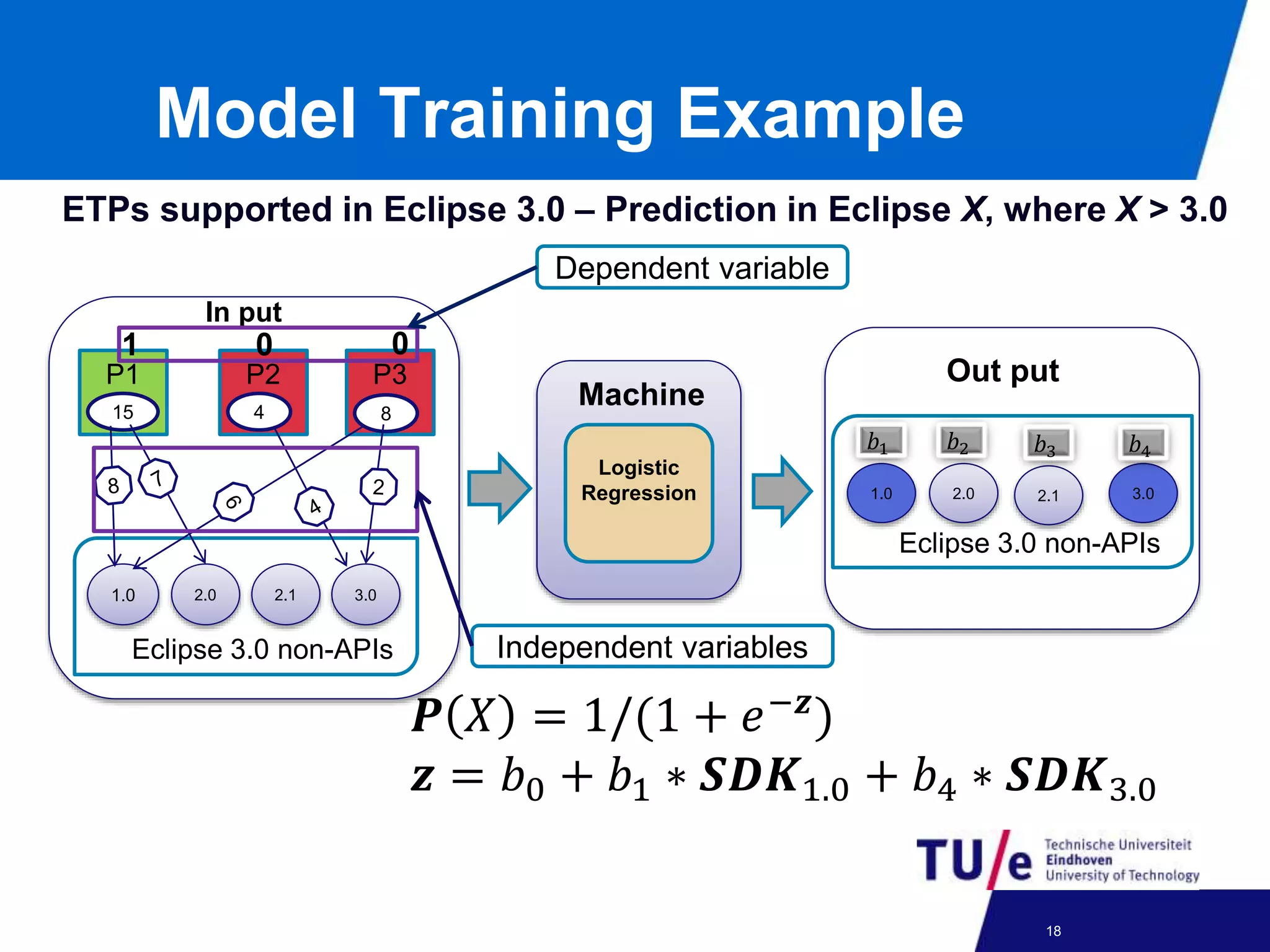
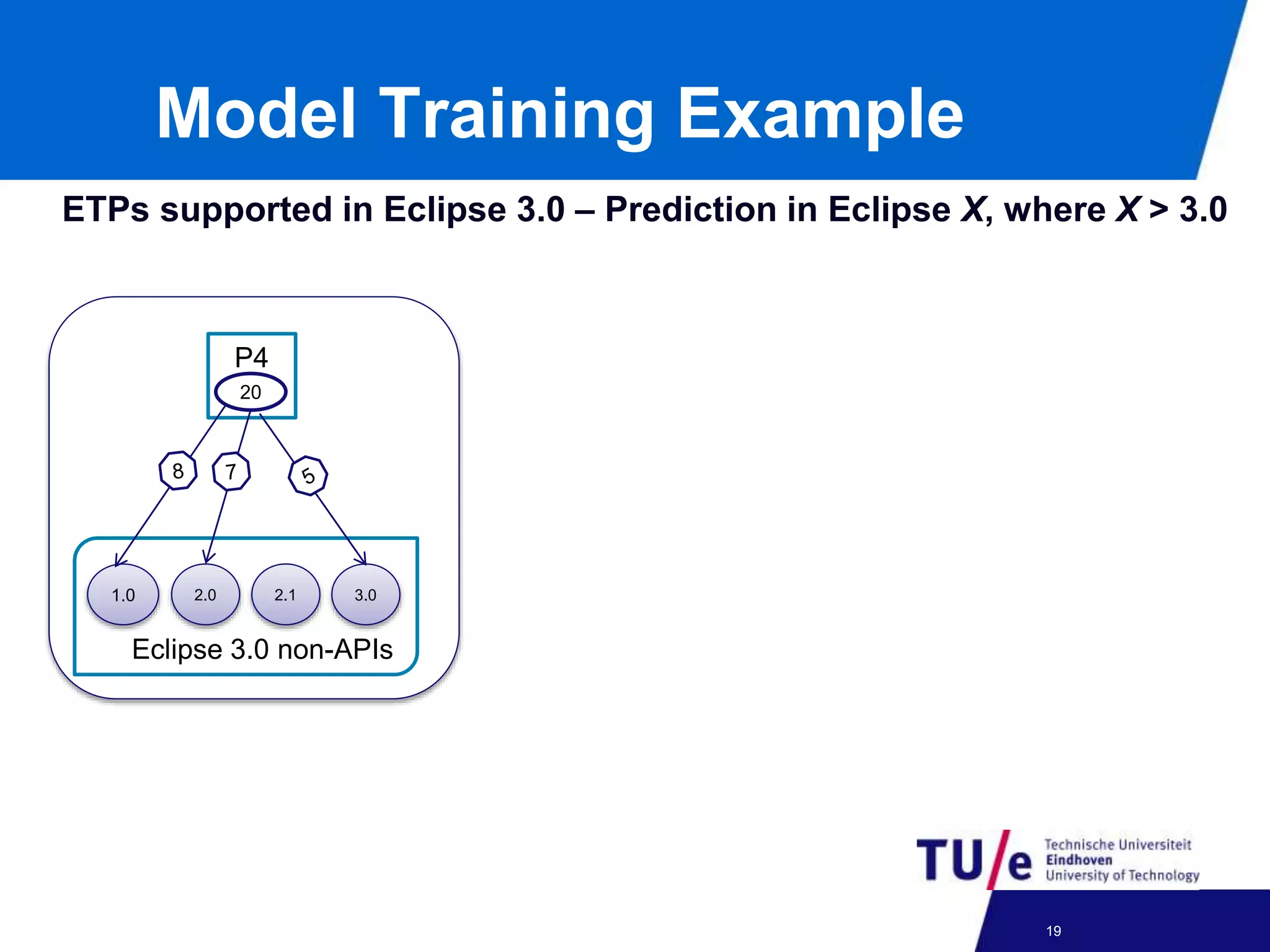

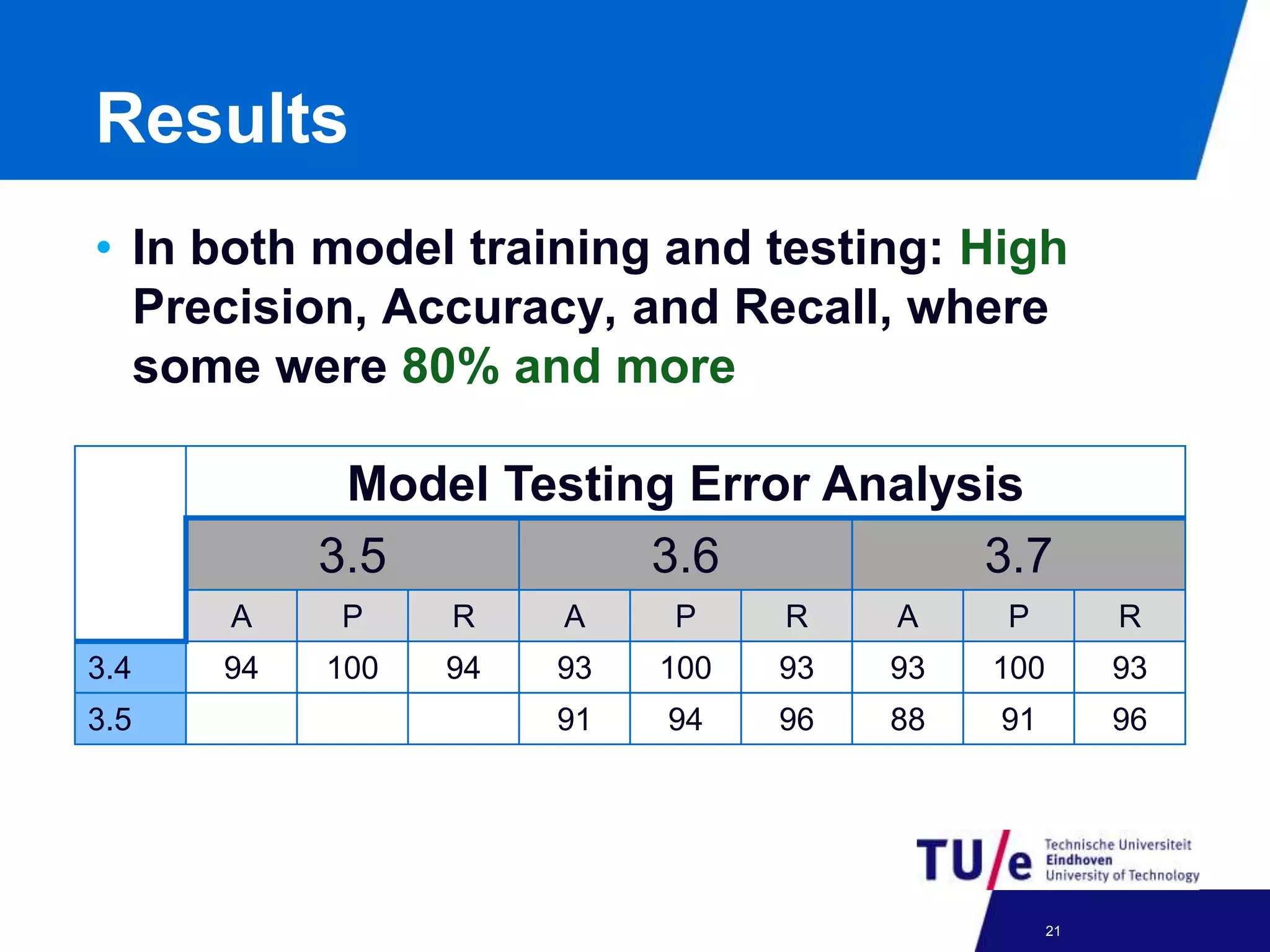



This document discusses a study on predicting the compatibility of Eclipse third-party plugins (ETPs) with new Eclipse releases. The researchers built prediction models using logistic regression based on ETPs' usage of Eclipse APIs versus non-APIs. They trained and tested 36 models and found high accuracy, precision, and recall over 80% in many cases. The models show promise for predicting compatibility and could be developed into a tool to help ETP users and developers.




















































![Studying Humans in Software Engineering [Keynote talk at BPM 2024]](https://cdn.slidesharecdn.com/ss_thumbnails/bpmkeynotewithpresenternotes-240905145618-ea77e59b-thumbnail.jpg?width=640&height=640&fit=bounds)





































