Downloaded 42 times














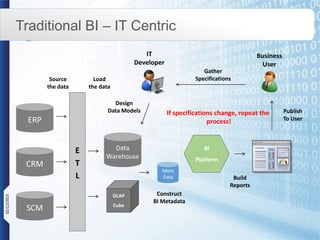
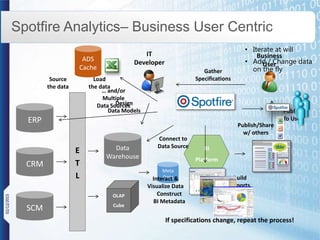
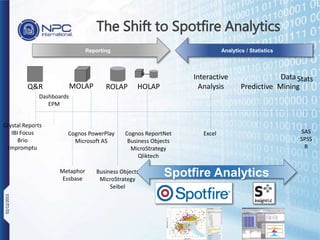
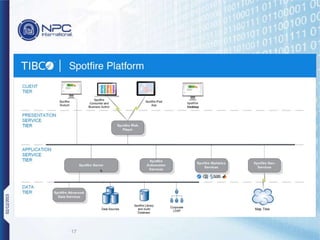
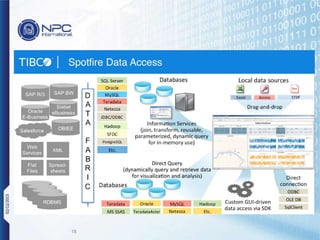




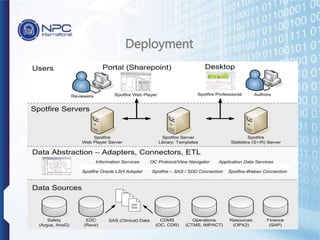
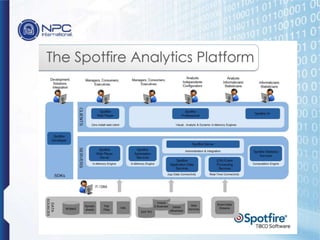
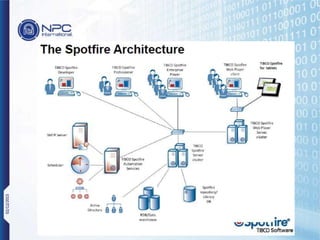











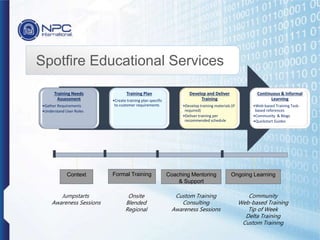







NPC International is a Bangkok-based system integrator focused on providing tailored IT solutions, emphasizing the importance of high availability and long-term partnerships. Their offerings include advanced analytics through Tibco Spotfire, enabling organizations to leverage big data for actionable insights, while ensuring comprehensive IT security measures. The document outlines their various services, including network solutions, managed file transfers, and predictive analytics, underscoring their commitment to empowering users with self-service discovery capabilities.



































































