Intro
진행하기전에.....
슬라이드의 모든 codesnippets은 아래의 링크로 다운 받
거나, 아래의 사이트에서 보시면 됩니다.
Download :
http://tagme.to/aisolab/To_quickly_implementin
g_RNN
Click : To quickly implementing RNN.ipynb
3
4.
Intro
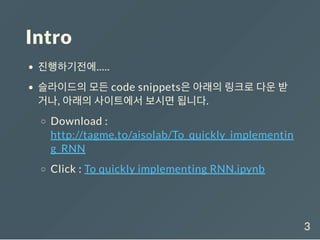
먼저 Recurrent NeuralNetworks의 이론은 알고 있다
고 가정, api를 사용하는 법만 살펴봄
모든 상황은 variable sequence length를 가정, 예를 들
면 아래와 같이..
# 문장의 단어를 RNN에 하나하나씩 넣는다고 하면?
# RNN은 아래처럼 각 문장 별로 단어의 개수만큼 sequence를 처리해야한다.
sentences = [['I', 'feel', 'hungry'],
['tensorflow', 'is', 'very', 'difficult'],
['tensorflow', 'is', 'a', 'framework',
'for','deep','learning'],
['tensorflow', 'is', 'very',
'fast', 'changing']]
4
5.
Intro : Padding
tensorow에서 variable sequence length를 다루기
위해서는 일단 적당한 길이로 padding을 해야함
왜냐하면 eager mode를 활용하지않는 이상 tensor ow
는 정적인 framework이기 때문
padding을 위한 tensor ow graph를 정의하거나,
python 함수를 정의하여 활용
padding시 적당한 최대 길이를 정해줄 것
5
6.
Intro : Padding
#word dic
word_list = []
for elm in sentences:
word_list += elm
word_list = list(set(word_list))
word_list.sort()
# '<pad>'라는 의미없는 token 추가
word_list = ['<pad>'] + word_list
word_dic = {word : idx for idx,
word in enumerate(word_list)}
6
7.
Intro : Padding
#max_len의 길이에 못미치는 문장은 <pad>로 max_len만큼 padding
def pad_seq(sequences, max_len, dic):
seq_len, seq_indices = [], []
for seq in sequences:
seq_len.append(len(seq))
seq_idx = [dic.get(char) for char in seq]
# 0 is idx of meaningless token "<pad>"
seq_idx += (max_len - len(seq_idx)) *
[dic.get('<pad>')]
seq_indices.append(seq_idx)
return seq_len, seq_indices
7
Intro : Lookup
variable sequence를 가지는 input을 RNN의 input으
로 넣을 수 있도록 잘 padding 했는 데...
padding 한 것을 그대로 RNN의 input으로 넣는 게 맞나?
idx 별 뭔가 dense vector (eg. word2vec) 등을 사용해
야함, tf.nn.embedding_lookup을 활용하자!
tf.nn.embedding_lookup(
params,
ids,
partition_strategy='mod',
name=None,
validate_indices=True,
max_norm=None)
9
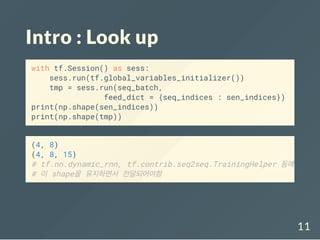
Example data
sentences의 word들의idx를 가지고 있는 dictionary
생성
# word dic
word_list = []
for elm in sentences:
word_list += elm
word_list = list(set(word_list))
word_list.sort()
# '<pad>'라는 의미없는 token 추가
word_list = ['<pad>'] + word_list
word_dic = {word : idx for idx,
word in enumerate(word_list)}
14
Simple
tf.nn.dynamic_rnn
cell을 돌릴 때활용, return 값 중 state만을 활용
sequence_length에 padding 하기전 문장의 길이를 넣어주면 알아서 원 문장
의 sequence만큼 처리
tf.losses.softmax_cross_entropy
일반적인 NN의 loss와 동일
tf.nn.dynamic_rnn(cell, inputs,
sequence_length=None, initial_state=None,
dtype=None, parallel_iterations=None,
swap_memory=False, time_major=False,
scope=None)
16
Bi-directional
tf.nn.bidirectional_dynamic_rnn
fw_cell과 bw_cell을 돌릴때 활용, return 값 중 output_states만을 활용,
output_states는 fw_cell과 bw_cell의 nal state 값을 갖고 있어서, loss
계산 시 둘을 concatenate해서 활용
tf.nn.bidirectional_dynamic_rnn(cell_fw, cell_bw,
inputs, sequence_length=None,
initial_state_fw=None, initial_state_bw=None,
dtype=None, parallel_iterations=None,
swap_memory=False, time_major=False, scope=None)
18
19.
Stacked Bi-directional
tf.contrib.rnn.stack_bidirectional_dynamic_rnn
각각의 fw_cells,bw_cells (list 형태)를 돌릴 때 활용
return 값 중 output_state_fw, output_state_bw를 concatenate해서 활
용
tf.contrib.rnn.stack_bidirectional_dynamic_rnn(
cells_fw, cells_bw,
inputs, initial_states_fw=None,
initial_states_bw=None, dtype=None,
sequence_length=None,
parallel_iterations=None,
time_major=False,
scope=None)
19
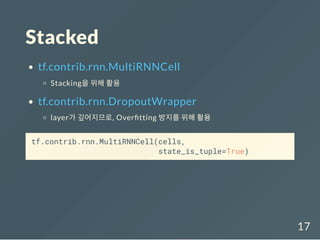
Example data
sentences의word들의idx를가지고있는dictionary
생성
pos의 token들의idx를 가지고 있는 dictionary 생성
# word dic
word_list = []
for elm in sentences:
word_list += elm
word_list = list(set(word_list))
word_list.sort()
word_list = ['<pad>'] + word_list
word_dic = {word : idx for idx, word
in enumerate(word_list)}
22
23.
Example data
sentences의 word들의idx를 가지고 있는 dictionary
생성
pos의token들의idx를가지고있는dictionary 생성
# pos dic
pos_list = []
for elm in pos:
pos_list += elm
pos_list = list(set(pos_list))
pos_list.sort()
pos_list = ['<pad>'] + pos_list
pos_dic = {pos : idx for idx, pos in enumerate(pos_list)}
23
Simple
Cell을 사용하는 방식은Many to One 위 Case와 동일
단 tf.nn.dynamic_rnn의 return 값중 outputs을 활용
tf.contrib.rnn.OutputProjectionWrapper
step마다 classify를 하기위해 활용
tf.sequence_mask
원래 sequence에 대해서만 loss를 계산하기위해 활용
tf.contrib.seq2seq.sequence_loss
tf.sequence_mask의 output을 weights arg에 전달 받음
targets arg에 [None, sequence_length]의 label 전달
27
28.
Stacked
Cell을 사용하는 방식은Many to One 위 Case와 동일
단 tf.nn.dynamic_rnn의 return 값중 outputs을 활용
tf.contrib.rnn.OutputProjectionWrapper
step마다 classify를 하기위해 활용
tf.sequence_mask
원래 sequence에 대해서만 loss를 계산하기위해 활용
tf.contrib.seq2seq.sequence_loss
tf.sequence_mask의 output을 weights arg에 전달 받음
targets arg에 [None, sequence_length]의 label 전달
28
29.
Bi-directional
Cell을 사용하는 방식은Many to One 위 Case와 동일
단 tf.nn.bidirectional_dynamic_rnn의 return 값중 outputs을 활용
tf.map_fn
step마다 classify를 하기위해 활용
tf.sequence_mask
원래 sequence에 대해서만 loss를 계산하기위해 활용
tf.contrib.seq2seq.sequence_loss
tf.sequence_mask의 output을 weights arg에 전달 받음
targets arg에 [None, sequence_length]의 label 전달
29
30.
Stacked Bi-directional
Cell을 사용하는방식은 Many to One 위 Case와 동일
단 tf.contrib.rnn.stack_bidirectional_dynamic_rnn의 return 값중
outputs을 활용
tf.map_fn
step마다 classify를 하기위해 활용
tf.sequence_mask
원래 sequence에 대해서만 loss를 계산하기위해 활용
tf.contrib.seq2seq.sequence_loss
tf.sequence_mask의 output을 weights arg에 전달 받음
targets arg에 [None, sequence_length]의 label 전달
30
Example data
sources의word들의idx를가지고있는dictionary 생
성
targets의word들의 idx를 가지고 있는 dictionary 생성
# word dic for sentences
source_words = []
for elm in sources:
source_words += elm
source_words = list(set(source_words))
source_words.sort()
source_words = ['<pad>'] + source_words
source_dic = {word : idx for idx, word
in enumerate(source_words)}
33
34.
Example data
sources의 word들의idx를 가지고 있는 dictionary 생성
targets의word들의idx를가지고있는dictionary 생
성
# word dic for translations
target_words = []
for elm in targets:
target_words += elm
target_words = list(set(target_words))
target_words.sort()
# 번역문의 시작과 끝을 알리는 'start', 'end' token 추가
target_words = ['<pad>']+ ['<start>'] + ['<end>'] +
target_words
target_dic = {word : idx for idx, word
in enumerate(target_words)} 34



![Intro
먼저 Recurrent Neural Networks의 이론은 알고 있다
고 가정, api를 사용하는 법만 살펴봄
모든 상황은 variable sequence length를 가정, 예를 들
면 아래와 같이..
# 문장의 단어를 RNN에 하나하나씩 넣는다고 하면?
# RNN은 아래처럼 각 문장 별로 단어의 개수만큼 sequence를 처리해야한다.
sentences = [['I', 'feel', 'hungry'],
['tensorflow', 'is', 'very', 'difficult'],
['tensorflow', 'is', 'a', 'framework',
'for','deep','learning'],
['tensorflow', 'is', 'very',
'fast', 'changing']]
4](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-4-320.jpg)

![Intro : Padding
# word dic
word_list = []
for elm in sentences:
word_list += elm
word_list = list(set(word_list))
word_list.sort()
# '<pad>'라는 의미없는 token 추가
word_list = ['<pad>'] + word_list
word_dic = {word : idx for idx,
word in enumerate(word_list)}
6](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-6-320.jpg)
![Intro : Padding
# max_len의 길이에 못미치는 문장은 <pad>로 max_len만큼 padding
def pad_seq(sequences, max_len, dic):
seq_len, seq_indices = [], []
for seq in sequences:
seq_len.append(len(seq))
seq_idx = [dic.get(char) for char in seq]
# 0 is idx of meaningless token "<pad>"
seq_idx += (max_len - len(seq_idx)) *
[dic.get('<pad>')]
seq_indices.append(seq_idx)
return seq_len, seq_indices
7](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-7-320.jpg)
![Intro : Padding
max_length = 8
sen_len, sen_indices = pad_seq(sequences = sentences,
max_len = max_length,
dic = word_dic)
[3, 4, 7, 5]
[[1, 7, 10, 0, 0, 0, 0, 0],
[13, 11, 14, 5, 0, 0, 0, 0],
[13, 11, 2, 9, 8, 4, 12, 0],
[13, 11, 14, 6, 3, 0, 0, 0]]
8](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-8-320.jpg)

![Intro : Look up
# tf.nn.embedding_lookup의 params, ids arg에 전달하기위한
# placeholder 선언
seq_len = tf.placeholder(dtype = tf.int32, shape = [None])
seq_indices = tf.placeholder(dtype = tf.int32,
shape = [None, max_length])
one_hot = np.eye(len(word_dic)) # 단어 별 one-hot encoding
# embedding vector는 training 안할 것이므로
one_hot = tf.get_variable(name='one_hot',
initializer = one_hot,
trainable = False)
seq_batch = tf.nn.embedding_lookup(params = one_hot,
ids = seq_indices)
10](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-10-320.jpg)

![Example data
sentences = [['I', 'feel', 'hungry'],
['tensorflow', 'is', 'very', 'difficult'],
['tensorflow', 'is', 'a', 'framework', 'for',
'deep', 'learning'],
['tensorflow', 'is', 'very', 'fast',
'changing']]
label = [[0.,1.], [0.,1.], [1.,0.], [1.,0.]]
13](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-13-320.jpg)
![Example data
sentences의 word들의 idx를 가지고 있는 dictionary
생성
# word dic
word_list = []
for elm in sentences:
word_list += elm
word_list = list(set(word_list))
word_list.sort()
# '<pad>'라는 의미없는 token 추가
word_list = ['<pad>'] + word_list
word_dic = {word : idx for idx,
word in enumerate(word_list)}
14](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-14-320.jpg)
![Example data
dictionary를 이용하여 다음과 같이 전처리
[3, 4, 7, 5]
[[1, 7, 10, 0, 0, 0, 0, 0],
[13, 11, 14, 5, 0, 0, 0, 0],
[13, 11, 2, 9, 8, 4, 12, 0],
[13, 11, 14, 6, 3, 0, 0, 0]]
max_length = 8
sen_len, sen_indices = pad_seq(sequences = sentences, max_len =
dic = word_dic)
pprint(sen_len)
pprint(sen_indices)
15](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-15-320.jpg)




![Example data
sentences = [['I', 'feel', 'hungry'],
['tensorflow', 'is', 'very', 'difficult'],
['tensorflow', 'is', 'a', 'framework', 'for',
'deep', 'learning'],
['tensorflow', 'is', 'very', 'fast',
'changing']]
pos = [['pronoun', 'verb', 'adjective'],
['noun', 'verb', 'adverb', 'adjective'],
['noun', 'verb', 'determiner', 'noun',
'preposition', 'adjective', 'noun'],
['noun', 'verb', 'adverb', 'adjective', 'verb']]
21](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-21-320.jpg)
![Example data
sentences의word들의idx를가지고있는dictionary
생성
pos의 token들의 idx를 가지고 있는 dictionary 생성
# word dic
word_list = []
for elm in sentences:
word_list += elm
word_list = list(set(word_list))
word_list.sort()
word_list = ['<pad>'] + word_list
word_dic = {word : idx for idx, word
in enumerate(word_list)}
22](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-22-320.jpg)
![Example data
sentences의 word들의 idx를 가지고 있는 dictionary
생성
pos의token들의idx를가지고있는dictionary 생성
# pos dic
pos_list = []
for elm in pos:
pos_list += elm
pos_list = list(set(pos_list))
pos_list.sort()
pos_list = ['<pad>'] + pos_list
pos_dic = {pos : idx for idx, pos in enumerate(pos_list)}
23](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-23-320.jpg)

![Example data
dictionary를 이용하여 다음과 같이 전처리
pprint(sen_len)
pprint(sen_indices)
[3, 4, 7, 5]
[[1, 7, 10, 0, 0, 0, 0, 0],
[13, 11, 14, 5, 0, 0, 0, 0],
[13, 11, 2, 9, 8, 4, 12, 0],
[13, 11, 14, 6, 3, 0, 0, 0]]
25](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-25-320.jpg)
![Example data
dictionary를 이용하여 다음과 같이 전처리
pprint(pos_indices)
[[6, 7, 1, 0, 0, 0, 0, 0],
[4, 7, 2, 1, 0, 0, 0, 0],
[4, 7, 3, 4, 5, 1, 4, 0],
[4, 7, 2, 1, 7, 0, 0, 0]]
26](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-26-320.jpg)
![Simple
Cell을 사용하는 방식은 Many to One 위 Case와 동일
단 tf.nn.dynamic_rnn의 return 값중 outputs을 활용
tf.contrib.rnn.OutputProjectionWrapper
step마다 classify를 하기위해 활용
tf.sequence_mask
원래 sequence에 대해서만 loss를 계산하기위해 활용
tf.contrib.seq2seq.sequence_loss
tf.sequence_mask의 output을 weights arg에 전달 받음
targets arg에 [None, sequence_length]의 label 전달
27](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-27-320.jpg)
![Stacked
Cell을 사용하는 방식은 Many to One 위 Case와 동일
단 tf.nn.dynamic_rnn의 return 값중 outputs을 활용
tf.contrib.rnn.OutputProjectionWrapper
step마다 classify를 하기위해 활용
tf.sequence_mask
원래 sequence에 대해서만 loss를 계산하기위해 활용
tf.contrib.seq2seq.sequence_loss
tf.sequence_mask의 output을 weights arg에 전달 받음
targets arg에 [None, sequence_length]의 label 전달
28](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-28-320.jpg)
![Bi-directional
Cell을 사용하는 방식은 Many to One 위 Case와 동일
단 tf.nn.bidirectional_dynamic_rnn의 return 값중 outputs을 활용
tf.map_fn
step마다 classify를 하기위해 활용
tf.sequence_mask
원래 sequence에 대해서만 loss를 계산하기위해 활용
tf.contrib.seq2seq.sequence_loss
tf.sequence_mask의 output을 weights arg에 전달 받음
targets arg에 [None, sequence_length]의 label 전달
29](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-29-320.jpg)
![Stacked Bi-directional
Cell을 사용하는 방식은 Many to One 위 Case와 동일
단 tf.contrib.rnn.stack_bidirectional_dynamic_rnn의 return 값중
outputs을 활용
tf.map_fn
step마다 classify를 하기위해 활용
tf.sequence_mask
원래 sequence에 대해서만 loss를 계산하기위해 활용
tf.contrib.seq2seq.sequence_loss
tf.sequence_mask의 output을 weights arg에 전달 받음
targets arg에 [None, sequence_length]의 label 전달
30](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-30-320.jpg)

![Example data
targets = [['나는', '배가', '고프다'],
['텐서플로우는', '매우', '어렵다'],
['텐서플로우는', '딥러닝을', '위한', '프레임워크이다'],
['텐서플로우는', '매우', '빠르게', '변화한다']]
sources = [['I', 'feel', 'hungry'],
['tensorflow', 'is', 'very', 'difficult'],
['tensorflow', 'is', 'a', 'framework', 'for', 'deep',
['tensorflow', 'is', 'very', 'fast', 'changing']]
32](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-32-320.jpg)
![Example data
sources의word들의idx를가지고있는dictionary 생
성
targets의 word들의 idx를 가지고 있는 dictionary 생성
# word dic for sentences
source_words = []
for elm in sources:
source_words += elm
source_words = list(set(source_words))
source_words.sort()
source_words = ['<pad>'] + source_words
source_dic = {word : idx for idx, word
in enumerate(source_words)}
33](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-33-320.jpg)
![Example data
sources의 word들의 idx를 가지고 있는 dictionary 생성
targets의word들의idx를가지고있는dictionary 생
성
# word dic for translations
target_words = []
for elm in targets:
target_words += elm
target_words = list(set(target_words))
target_words.sort()
# 번역문의 시작과 끝을 알리는 'start', 'end' token 추가
target_words = ['<pad>']+ ['<start>'] + ['<end>'] +
target_words
target_dic = {word : idx for idx, word
in enumerate(target_words)} 34](https://image.slidesharecdn.com/toquicklyimplementingrnn-180624094946/85/To-quickly-implementing-RNN-34-320.jpg)




![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180724063825-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[기초개념] Recurrent Neural Network (RNN) 소개](https://cdn.slidesharecdn.com/ss_thumbnails/agistpurnndkim190430-190430140949-thumbnail.jpg?width=640&height=640&fit=bounds)















