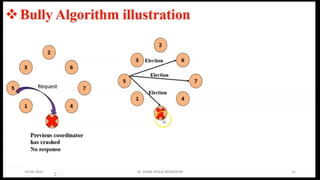
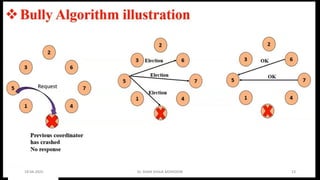
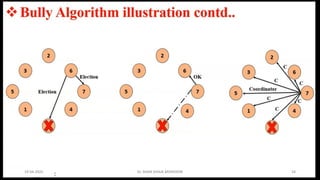
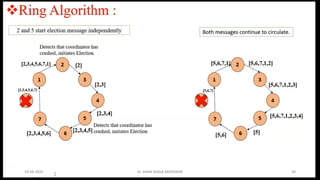
CO4: Distributed SystemAlgorithms: Coordination Algorithms,
Consistency and Replication, Global State and Snapshot Recording
Algorithms, Self-Stabilization in Distributed Systems, Fault-Tolerant
Message-Passing Systems.
19-04-2025 Dr. SHAIK KHAJA MOHIDDIN 1
. Checkpointing
•What itmeans: Saving the current state of the system at regular intervals.
•Why it's useful: If a failure occurs, the system can roll back to the last saved state instead of starting from scratch.
•Real-life example: Like saving a game — if you lose, you can restart from the last save point.
Collecting Garbage
•What it means: Identifying memory or resources (like messages or data) that are no longer needed.
•Why it's useful: Frees up memory and resources that could otherwise slow the system or cause errors.
•Analogy: Like cleaning up unused items from your desk to keep it tidy and efficient.
19-04-2025 Dr. SHAIK KHAJA MOHIDDIN 37
38.
Detecting Deadlocks
•What itmeans: Identifying situations where processes are stuck waiting on each other.
•Why it's useful: Snapshots help see the global state to determine if a cycle of waiting (deadlock) has formed.
•Example: Process A waits for B, B waits for C, and C waits for A – snapshot shows the full circle.
Other Debugging
•What it means: Finding bugs or unexpected behaviors in a running distributed system.
•Why it's useful: By capturing the system's state at a specific moment, developers can analyze what went wrong.
•Analogy: Like taking a screenshot of a strange error message to show the tech support team.
19-04-2025 Dr. SHAIK KHAJA MOHIDDIN 38
Distributed Computing: Principles,Algorithms, and Systems
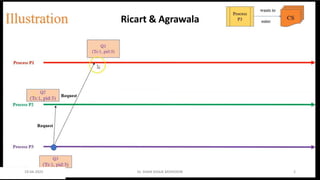
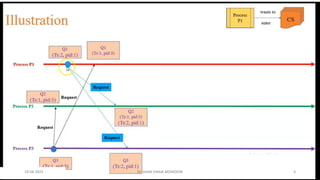
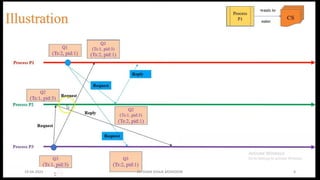
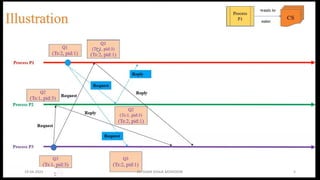
Lai-Yang algorithm
The Lai-Yang algorithm fulfills this role of a marker in a non-FIFO system by
using a coloring scheme on computation messages that works as follows:
1
2
3
4
Every process is initially white and turns red while taking a snapshot. The
equivalent of the “Marker Sending Rule” is executed when a process turns
red.
Every message sent by a white (red) process is colored white (red).
Thus, a white (red) message is a message that was sent before (after) the
sender of that message recorded its local snapshot.
Every white process takes its snapshot at its convenience, but no later than
the instant it receives a red message.
A. Kshemkalyani and M. Singhal (Distributed Comput Global State and Snapshot Recording Algorithms CUP 2008
60 / 51
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 63
Purpose:
•The Lai-Yang algorithm addresses the limitations of snapshot recording in non-FIFO syabaems.
Core Concepts:
•Coloring scheme:
• All processes and messages start as white.
• When a process takes a snapshot, it turns red.
• After turning red, it sends only red messages.
🧠 Rules:
1.A process turns red when it takes a snapshot.
2.Messages inherit the color of the sender at the time of sending:
1. White process → sends white message.
2. Red process → sends red message.
3.A message’s color helps determine whether it was sent before or after the sender's snapshot.
4.A white process must take a snapshot before or exactly when it receives its first red message.
Distributed Computing: Principles,Algorithms, and Systems
Lai-Yang algorithm
4
5
6
• Every white process records a history of all white messages sent or received by it along each channel.
• When a process turns red, it sends these histories along with its snapshot to the initiator
• process that collects the global snapshot.
• The initiator process evaluates transit(LSi ,LSj) to compute the state of achannel Cij as given below:
• SCij = white messages sent by pi on Cij − white messages received by pj on
• Cij
• = {send(mij )|send(mij ) ∈ LSi } − {rec(mij )|rec(mij ) ∈ LSj }.
A. Kshemkalyani and M. Singhal (Distributed Comput Global State and Snapshot Recording Algorithms CUP 2008
65 / 51
66.
Distributed Computing: Principles,Algorithms, and Systems
Mattern’s algorithm
Mattern’s algorithm is based on vector clocks and assumes a single initiator
process and works as follows:
1
2
3
4
5
6
The initiator “ticks” its local clock and selects a future vector time s at
which it would like a global snapshot to be recorded. It then broadcasts this
time s and freezes all activity until it receives all acknowledgements of the
receipt of this broadcast.
When a process receives the broadcast, it remembers the value s and returns
an acknowledgement to the initiator.
After having received an acknowledgement from every process, the initiator
increases its vector clock to s and broadcasts a dummy message to all
processes.
The receipt of this dummy message forces each recipient to increase its clock
to a value ≥ s if not already ≥ s.
Each process takes a local snapshot and sends it to the initiator when (just
before) its clock increases from a value less than s to a value ≥ s.
The state of Cij is all messages sent along Cij, whose timestamp is smaller
than s and which are received by pj after recording LSj.
A. Kshemkalyani and M. Singhal (Distributed Comput Global State and Snapshot Recording Algorithms CUP 2008
66 / 51
67.
Distributed Computing: Principles,Algorithms, and Systems
Mattern’s algorithm
A termination detection scheme for non-FIFO channels is required to detect that no
white messages are in transit.
One of the following schemes can be used for termination detection:
First method:
Each process i keeps a counter cntri that indicates the difference between the number
of white messages it has sent and received before recording its snapshot.
It reports this value to the initiator process along with its snapshot and forwards
all white messages, it receives henceforth, to the initiator.
Snapshot collection terminates when the initiator has received
Σ
i cntri
number of forwarded white messages.
A. Kshemkalyani and M. Singhal (Distributed Comput Global State and Snapshot Recording Algorithms CUP 2008
67 / 51
68.
Distributed Computing: Principles,Algorithms, and Systems
Mattern’s algorithm
Second method:
Each red message sent by a process carries a piggybacked value of the number
of white messages sent on that channel before the local state recording.
Each process keeps a counter for the number of white messages received on
each channel.
A process can detect termination of recording the states of incoming channels
when it receives as many white messages on each channel as the value
piggybacked on red messages received on that channel.
A. Kshemkalyani and M. Singhal (Distributed Comput Global State and Snapshot Recording Algorithms CUP 2008
68 / 51
69.
Distributed Computing: Principles,Algorithms, and Systems
Snapshots in a causal delivery system
The causal message delivery property CO provides a built-in message
synchronization to control and computation messages.
Two global snapshot recording algorithms, namely, Acharya-Badrinath and
Alagar-Venkatesan exist that assume that the underlying system supports
causal message delivery.
In both these algorithms recording of process state is identical and proceed as
follows :
An initiator process broadcasts a token, denoted as token, to every process
including itself.
Let the copy of the token received by process pi be denoted tokeni.
A process pi records its local snapshot LSi when it receives tokeni and sends
the recorded snapshot to the initiator.
The algorithm terminates when the initiator receives the snapshot recorded
by each process.
A. Kshemkalyani and M. Singhal (Distributed Comput Global State and Snapshot Recording Algorithms CUP 2008
69 / 51
70.
Distributed Computing: Principles,Algorithms, and Systems
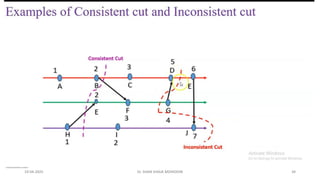
Snapshots in a causal delivery system
Correctness
For any two processes pi and pj , the following property is satisfied:
send(mij ) /
∈LSi ⇒ rec(mij ) /
∈LSj.
This is due to the causal ordering property of the underlying system as
explained next.
◮ Let a message mij be such that rec(tokeni) −→ send(mij).
◮ Then send(tokenj) −→ send(mij ) and the underlying causal ordering property
ensures that rec(tokenj), at which instant process pj records LSj, happens
before rec(mij ).
◮ Thus, mij whose send is not recorded in LSi, is not recorded as received in LSj.
Channel state recording is different in these two algorithms and is discussed
next.
A. Kshemkalyani and M. Singhal (Distributed Comput Global State and Snapshot Recording Algorithms CUP 2008
70 / 51
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 76
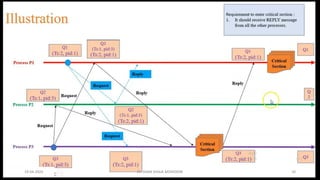
Global State: It is a set of local states of all individual processes
Need for global state:
• Distributed deadlock detection
• Termination detection
• Check point
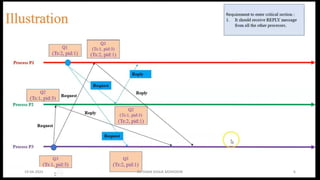
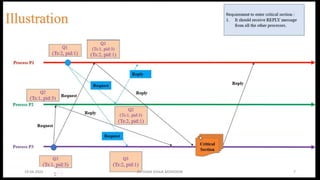
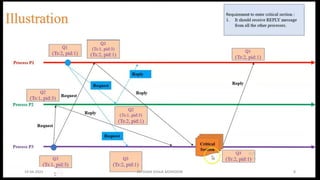
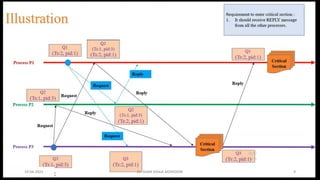
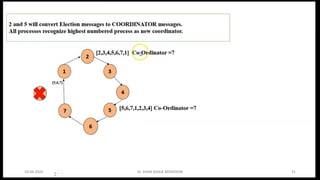
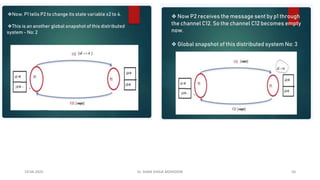
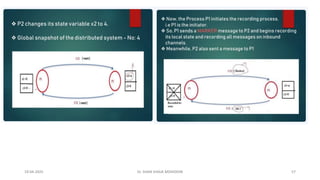
Chandy Lamport’s global state recording algorithm:
• Marker sending rule for process p
• p records its state
• P sends a marker algong c before p sends further message
• Marker receiving rule for a process Q
• If Q not recorded its state
• Record empty channel
• Record the state of C as sequences of messages
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 80
What is Self-ailization?
In a distributed system, multiple computers (nodes) work together and communicate. Sometimes due to faults (e.g., lost
messages), the system can enter a bad or illegal state.
Self-stabilization means:
"No matter how bad the system’s current state is, it will automatically recover and return to a correct state — without human
help — in a finite time.“
System Model (How It Works)
•Each node is modeled as a state machine.
•Nodes are connected in a network and talk to each other using message queues.
•All node connections form a graph, and it must stay connected (every node can reach every other).
81.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 81
Legitimate vs Illegitimate States
•Legitimate state = Everything working as expected (system satisfies a certain condition P).
•Illegitimate state = Something has gone wrong.
The goal of self-stabilization:
•From any illegitimate state, reach a legitimate one.
•Once in a legitimate state, stay there unless another fault occurs.
82.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 82
Self-Stabilization in Distributed Systems
• The idea of self-stabilization in distributed computing was first proposed by Dijkstra in 1974.
• Imagine your system (like a group of computers) gets confused or messed up. No matter how bad the confusion is, the
system should be able to fix itself on its own, without any help. That’s what self-stabilization means — the system will
eventually come back to a correct and working state.
System Model?
A System Model in distributed computing is a simplified way to understand how a group of computers (called processors or
machines) work together by communicating over a network.
Imagine you have many computers connected together. Each computer:
•Runs its own program
•Can talk to only its neighboring computers (not all at once)
•Communicates by sending and receiving messages
83.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 83
Key Concepts in the Model:
•Each computer is treated as a state machine, meaning it changes its internal state based on rules and messages.
•These computers (or processors) form a ring or network where each can communicate directly only with a few others
(neighbors).
• Messages are exchanged using a FIFO (First-In-First-Out) queue – think of it as a line where the first message goes out or gets
received first.
State of the System:
•The entire system’s condition at a moment is described by the state of each computer and the messages in transit.
•This full snapshot is called the system configuration.
Why Use This Model?
•It ignores unnecessary details (like hardware) and focuses on how systems behave.
•It helps in analyzing how computers interact, how problems like synchronization or deadlock are handled, and whether the
system can stabilize after faults.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 85
Self-stabilization means that:
•Even if a system starts in a wrong or messed-up state,
•It will automatically fix itself and come back to a correct state
•Without any help from outside.
•Self-stabilization means that no matter what state a system is in, it can automatically recover and return to a correct or safe
state without any external help.
•We check this using a condition (called a predicate P) over the system's global state (i.e., the combined state of all
parts/machines in the system).
86.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 86
Two Key Properties for Self-Stabilization
Closure
Once the system enters a legitimate state (satisfying P), it stays there.
In simple terms: If the system is in a good state, it won’t suddenly break again.
Convergence
Even if the system starts in a bad or random state, it will eventually reach a legitimate (correct) state after some steps.
It’s like: No matter how messy it gets, it will always clean itself up in time.
87.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 87
🧠 Legitimate vs Illegitimate State
•Legitimate state = system is working correctly.
•Illegitimate state = system is in an error condition (like having no token or multiple tokens in a ring network).
Simple Example
Imagine a group of children forming a circle. If something goes wrong and the circle breaks:
•The children reorganize themselves and make the circle again Without any adult’s help
That's self-stabilization in real life!
Why It’s Hard?
•Each computer (or node) in the system doesn’t have full knowledge of everything.
•It makes decisions using only its local information.
•But still, together, they reach the correct state — like a team with no leader!
88.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 88
Issues in the design of self-stabilization algorithms
A distributed system comprises of many individual units and many issuesarise in the design of self-stabilization algorithms in
distributed system. Some of the main issues are as follows:
• Number of states in each of the individual units in a distributed system.
• Uniform and non-uniform algorithms in distributed systems.
• Central and distributed demon.
• Reducing the number of states in a token ring.
• Shared memory models.
• Mutual exclusion.
• Costs of self-stabilization.
89.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 89
Dijkstra’s self-stabilizing token ring system
Dijkstra designed a simple model to explain how distributed systems can automatically recover (or self-stabilize) from any error
or unexpected state — without human intervention.
In this system:
•There are n machines (or processes) arranged in a ring.
•Each machine can be in one of a few states (like 0, 1, or 2).
•Only one machine at a time is allowed to perform an action — this is called having the privilege.
Key Concept: Privilege and Move
•A machine has a privilege when it’s allowed to change its state based on its own state and its neighbors' states.
•When a machine uses its privilege to change its state, it's called a move.
•Sometimes, multiple machines may be eligible to move. In that case, a central controller (called a "daemon") decides who goes
next.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 92
Another version of the algorithm (when K = 3)
93.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 93
What Makes a State Legitimate?
For the system to be in a legitimate state, the following must be true:
1.At least one machine has a privilege — the system is not stuck (no deadlock).
2.Every move keeps the system in a legal state — the system never becomes invalid (closure).
3.Every machine will eventually get a chance to move — no machine is left out forever (no starvation).
4.From any valid state, you can reach any other valid state — the system is flexible (reachability).
94.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 94
Factors affecting self-stabilization
The factors preventing self-stabilization include the following:
• Symmetry
• Termination
• Isolation
• Look-alike configuration
Symmetry
•Think of symmetry as "everyone looks and behaves the same."
•If all processes (machines or nodes) in the system are identical in state, rules, position, etc., they won’t be able to
decide who should act or change.
•Example: If five people are standing in a circle wearing blindfolds, they can’t tell who’s who — no one knows who
should start moving.
•So, symmetry makes it impossible to break ties and choose a unique leader or action, preventing recovery.
95.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 95
• Termination
•Termination means a process finishes and stops acting.
•Self-stabilization needs the system to keep checking and correcting errors.
•If some part of the system stops (terminates), it can no longer help fix the system.
•Imagine a cleaning robot that shuts down permanently in a messy room — it can't clean or help stabilize the environment.
• Isolation
• Processes can’t see or communicate with others properly.
•This isolation means they can't detect problems or coordinate fixes.
•Example: A machine in a ring network that doesn’t know what its neighbors are doing — it won’t help fix the overall system
because it has no clue what's happening around it.
96.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 96
• Look-alike configuration
• There’s no fixed “correct” state that the system can settle into.
• Even if processes keep changing, the system might keep going in loops without ever becoming stable.
• Example: A traffic light that keeps switching without ever reaching a proper red/green/yellow cycle
97.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 97
limitations of self-stabilization
1. Slow Convergence
Self-stabilizing systems may take a long time to reach a correct state, especially if they start in an unknown or faulty state. This
delay can affect system performance.
2. Need for an Exceptional Machine
Some algorithms assume there is at least one special machine (like a leader or coordinator). In real distributed systems, this
might not always be possible or practical.
3. Convergence–Response Tradeoff
If we try to make the system converge faster, it might tolerate fewer errors, and vice versa. There's always a tradeoff between
how fast the system recovers and how many faults it can handle.
4. Pseudo-Stabilization
Sometimes, a system might not reach a fully correct state but instead enter a state that "looks correct" and doesn't cause
problems. This is called pseudo-stabilization, which is easier to implement but not always ideal.
5. Verification Difficulty
Checking whether a self-stabilizing algorithm works correctly can be tough. Step-by-step verification methods exist, but verifying
the entire system is still complex and challenging.
98.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 98
The Lamport-Shostak-Pease (LSP) Algorithm in a simple way with an easy-to-follow example. This algorithm is used in
fault-tolerant distributed systems to achieve Byzantine Agreement—i.e., making sure all non-faulty (honest) nodes agree
on the same value, even when some nodes are faulty or malicious (called Byzantine nodes).
Goal:
To allow a group of nodes (processes or generals) to agree on a value, even if some nodes lie or behave erratically (Byzantine
faults).
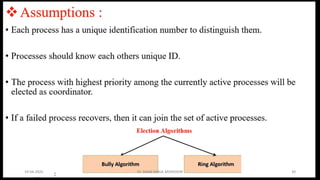
Assumptions:
There are n processes.
Up to f processes can be faulty.
Requires at least n ≥ 3f + 1 processes to tolerate f faults.
The algorithm works in rounds of communication (usually f + 1 rounds).
99.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 99
The Generals Problem"
Imagine 4 generals trying to agree on whether to attack or retreat. But one of them might be a traitor giving wrong advice.
How do the honest generals agree, even if the traitor says different things to different people?
LSP Algorithm (Simplified)
Each process (general):
1.Sends its value (e.g., 0 = Retreat, 1 = Attack) to all others.
2.Receives values from all others.
3.Builds a decision tree based on what it received (including what others claim they received).
4.Uses majority voting at each level to eliminate faulty messages.
5.Finally, decides the value based on majority results from trustworthy sources.
100.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 100
Example: 1 Faulty Node (f = 1)
Let's take:
n = 4 generals (P0, P1, P2, P3)
Up to f = 1 faulty general (say P3 is faulty)
Commander: P0 (starts with value = 1 → Attack)
Round 1:
P0 sends "Attack (1)" to all.
P1, P2, P3 receive this value.
But P3 is faulty and tells:
P1: “Retreat (0)”
P2: “Attack (1)”
Each lieutenant (P1, P2) now has:
From P0: 1 (Attack)
From P3 (faulty):
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 102
MPI-based program for the Stable Marriage Problem
MPI-Based Stable Marriage Problem – Key Points
Structure:
Each man is represented as a separate MPI process (rank 1 to N).
A master process (rank 0) manages all women.
Preferences:
Each man and woman has a preference list (ranking the opposite gender).
Proposal Process:
Men send proposals asynchronously using MPI_Isend to the master.
Each man proposes to women one by one based on his preference list.
103.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 103
Master Logic (Women Handler):
Receives all proposals.
Checks if the woman is free or already engaged.
If the woman is free → she accepts.
If already engaged → she compares the new proposer with her current partner using her preference list.
Decision Making:
If she prefers the new proposer, she switches and rejects the old partner.
Otherwise, she rejects the new proposer.
Communication:
Accept/reject messages are sent back to the men using MPI_Send.
Engagement Tracking:
Each woman keeps track of who she is currently engaged to.
104.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 104
Termination:
Once all men are engaged (i.e., they stop proposing), the program ends.
Logging:
All events (proposals, acceptances, rejections, switches) are logged in a file named Log.txt by the master process.
Result:
At the end, the program ensures a stable matching, meaning no pair would prefer someone else over their current
match.
105.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 105
Consistency and replication : To avoid bottlenecks, to provide fast access to data, and to
provide scalability, replication of data objects is highly desirable. This leads to issues of
managing the replicas, and dealing with consistency among the replicas/caches in a distributed
setting. A simple example issue is deciding the level of granularity (i.e., size) of data access.
• Fault tolerance : Fault tolerance requires maintaining correct and efficient operation in spite
of any failures of links, nodes, and processes. Process resilience, reliable communication,
distributed commit, checkpointing and recovery, agreement and consensus, failure detection,
and self-stabilization are some of the mechanisms to provide fault-tolerance.
106.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 106
Consistency and Replication
Reasons for replication
Two main reasons
• First, data are replicated to increase the reliability of a system. If a file system has been replicated, it may be possible to
continue working after one replica crashes by simply switching to one of the other replicas. Also, by maintaining multiple
copies, it becomes possible to provide better protection against corrupted data.
• Replication for performance is important when a distributed system needs to scale in terms of size or in terms of the
geographical area it covers. Scaling regarding size occurs, for example, when an increasing number of processes needs to
access data that are managed by a single server.
107.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 107
Client-Centric Consistency Models
In large-scale distributed systems with replication, strict data consistency across all replicas can be difficult to maintain. Instead
of enforcing strong global consistency, many systems (e.g., cloud storage, social media) adopt eventual consistency — where
updates eventually reach all replicas, but not immediately.
This can cause inconsistencies in what a user sees across sessions or devices.
To address this, client-centric consistency models aim to provide predictable and intuitive behavior from the user's perspective,
even in weakly consistent systems.
108.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 108
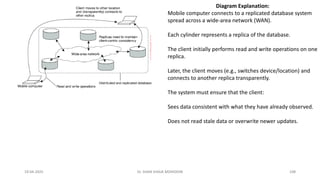
Diagram Explanation:
Mobile computer connects to a replicated database system
spread across a wide-area network (WAN).
Each cylinder represents a replica of the database.
The client initially performs read and write operations on one
replica.
Later, the client moves (e.g., switches device/location) and
connects to another replica transparently.
The system must ensure that the client:
Sees data consistent with what they have already observed.
Does not read stale data or overwrite newer updates.
109.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 109
Consistency Protocols
•Discusses implementation strategies to enforce different consistency models.
•Primary-based protocols (like primary-backup) delegate writes to a single authoritative replica.
•Replicated-write protocols use quorum-based approaches (e.g., ROWA) to manage consistency among multiple replicas.
•Cache-coherence protocols handle consistency in client-managed caches, focusing on detecting and resolving stale data.
•Client-centric consistency implementation involves maintaining read sets and write sets to ensure monotonic behaviors using
techniques like:
• Version tracking
• Unique write identifiers
• Server-side logging and updates
•Trade-offs involve balancing latency, complexity, and consistency guarantees
110.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 110
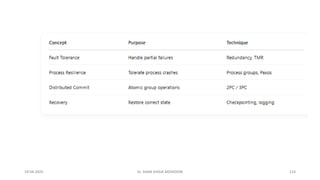
Introduction to Fault Tolerance
Definition: The system's ability to continue functioning correctly even when components fail.
Key Concepts:
Availability: System is ready for use.
Reliability: System runs continuously without failures.
Safety: Failures don’t cause harm.
Maintainability: Easy to repair and recover.
Fault Tolerance Technique:
Redundancy – use of extra components to mask failures.
Example: Triple Modular Redundancy (TMR) – three identical components with voting logic ensure correct output even if
one fails
.
111.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 111
Process Resilience
•Resilience via Process Groups:
• Multiple processes operate as a group to tolerate crashes.
• Group acts as a single logical entity for communication.
•Group Structures:
• Flat groups: All processes are equal (peer-to-peer).
• Hierarchical groups: One coordinator, others are workers.
•Consensus:
• Vital for consistency.
• Example: Paxos algorithm helps groups agree even with faulty nodes.
112.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 112
Distributed Commit
Goal: Ensure that an operation is either completed by all participants or none.
Common Protocols:
Two-Phase Commit (2PC):
Vote Request → participants respond with commit/abort.
Global Decision → if all commit, then send global commit, else abort.
Drawback: Blocking if coordinator crashes.
Three-Phase Commit (3PC):
Adds a prepare-to-commit phase.
Reduces blocking by allowing safe decisions even if coordinator fails.
Used in: Distributed transactions, database updates
113.
19-04-2025 Dr. SHAIKKHAJA MOHIDDIN 113
Recovery
Types of Recovery:
Backward Recovery: Roll back to a previous consistent state (checkpointing).
Forward Recovery: Move to a new, correct state (e.g., error correction).
Checkpointing Techniques:
Coordinated: All processes synchronize and take a snapshot together.
Independent: Each process takes checkpoints individually — risk of domino effect.
Message Logging: Used alongside checkpointing for state reconstruction after failures