Recommended
PDF
PDF
PPTX
PPTX
RaspberryPiを音声コントロールしてみた話
PDF
[Slide]DevLOVE iPhoneアプリ勉強会の【前説】※本編は未公開です!
PDF
PDF
V-To World - Rhythm Otonashi
PDF
PDF
PPTX
PDF
VR音ゲーを楽しんでいたら VR音ゲーを作り始めていた話
PPTX
PDF
PDF
Alive2015「 動くハイライト表現の可能性」栗坂こなべ
PDF
PDF
PPTX
PDF
2014.05.31.中国firefox os勉強会 pub
KEY
PDF
PDF
IWD - Women Techmakers Tokyo 2018 - Speechless Workshop
PDF
すしルート inヒカ☆ラボ_「すし×うごく」_20160314
PDF
V-To World - What is V-To - Koinu
PDF
PPT
PDF
PDF
PDF
PDF
PPTX
AmebaDSPの成長フェーズとアーキテクチャの話
More Related Content
PDF
PDF
PPTX
PPTX
RaspberryPiを音声コントロールしてみた話
PDF
[Slide]DevLOVE iPhoneアプリ勉強会の【前説】※本編は未公開です!
PDF
PDF
V-To World - Rhythm Otonashi
PDF
What's hot
PDF
PPTX
PDF
VR音ゲーを楽しんでいたら VR音ゲーを作り始めていた話
PPTX
PDF
PDF
Alive2015「 動くハイライト表現の可能性」栗坂こなべ
PDF
PDF
PPTX
PDF
2014.05.31.中国firefox os勉強会 pub
KEY
PDF
PDF
IWD - Women Techmakers Tokyo 2018 - Speechless Workshop
PDF
すしルート inヒカ☆ラボ_「すし×うごく」_20160314
PDF
V-To World - What is V-To - Koinu
PDF
PPT
PDF
PDF
PDF
More from Genki Ishibashi
PDF
PPTX
AmebaDSPの成長フェーズとアーキテクチャの話
PDF
PDF
PDF
Twilio flex導入までの背景と苦労した話
PDF
PDF
PDF
PPTX
PDF
PDF
PDF
Paper Collection of Real-Time Bidding論文読み会~第一回~
PDF
新卒の頃に意識したかった プロダクト開発の7つのポイント
PDF
PDF
PDF
PDF
PDF
Recently uploaded
PDF
krsk_aws_re-growth_aws_devops_agent_20251211
PDF
ソフトとハードの二刀流で実現する先進安全・自動運転のアルゴリズム開発【DENSO Tech Night 第二夜】 ー高精度な画像解析 / AI推論モデル ...
PDF
ソフトウェアエンジニアがクルマのコアを創る!? モビリティの価値を最大化するソフトウェア開発の最前線【DENSO Tech Night 第一夜】
PPTX
君をむしばむこの力で_最終発表-1-Monthon2025最終発表用資料-.pptx
PDF
音楽アーティスト探索体験に特化した音楽ディスカバリーWebサービス「DigLoop」|Created byヨハク技研
PDF
2025/12/12 AutoDevNinjaピッチ資料 - 大人な男のAuto Dev環境
CNNで作る ダメ絶対音感 1. 2. 自己紹介
● 石橋 弦樹(いし し げんき)
@b0941015
● 2015年 4月 新卒としてCAに入社
● 2017年10月 MDH DSPチームにJOIN
● 2018年 5月 チーム再編成
● 最近ポモドーロ・テクニック実践中
3. ダメ絶対音感と ...
● 絶対音感
○ ある音を単独に聞いた時に、そ 音 高さを記憶に基づいて絶対的に認識する能力である。
(@wikipedia)
● ダメ絶対音感
○ アニメやCM・洋画 吹き替えなど 声から瞬時に誰 声かを判断することができるという、生きてい
く上で特に必要 ない能力 ことをいう。 (@アニオタ
Wiki(仮))
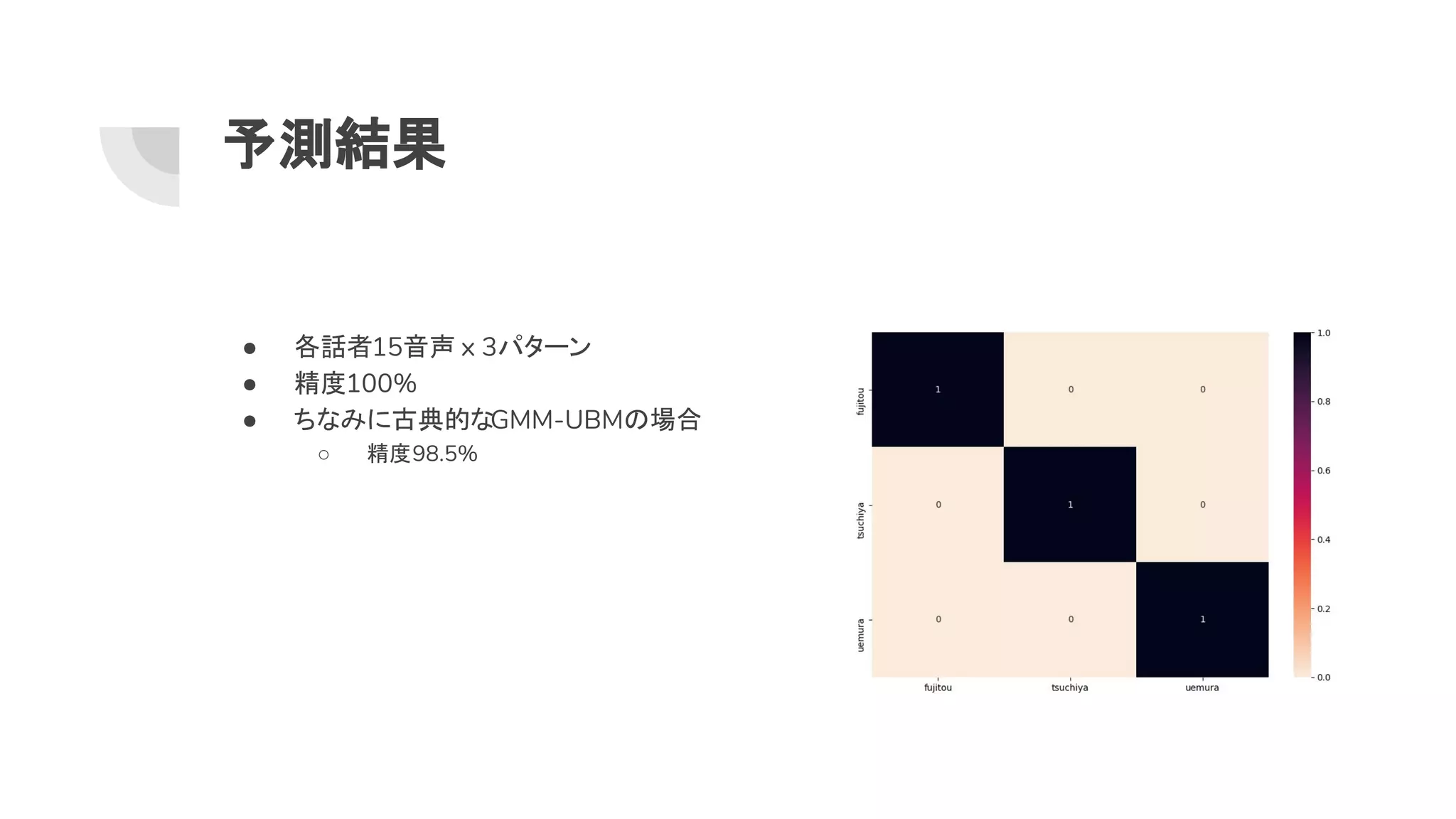
4. 5. 6. 7. 8. 1. データ集め
● 日本声優統計学会 コーパスを利用
○ プロ 女性声優3人
○ 音素バランス文を3パターンで読み上げたコーパス
○ https://github.com/voice-statistics
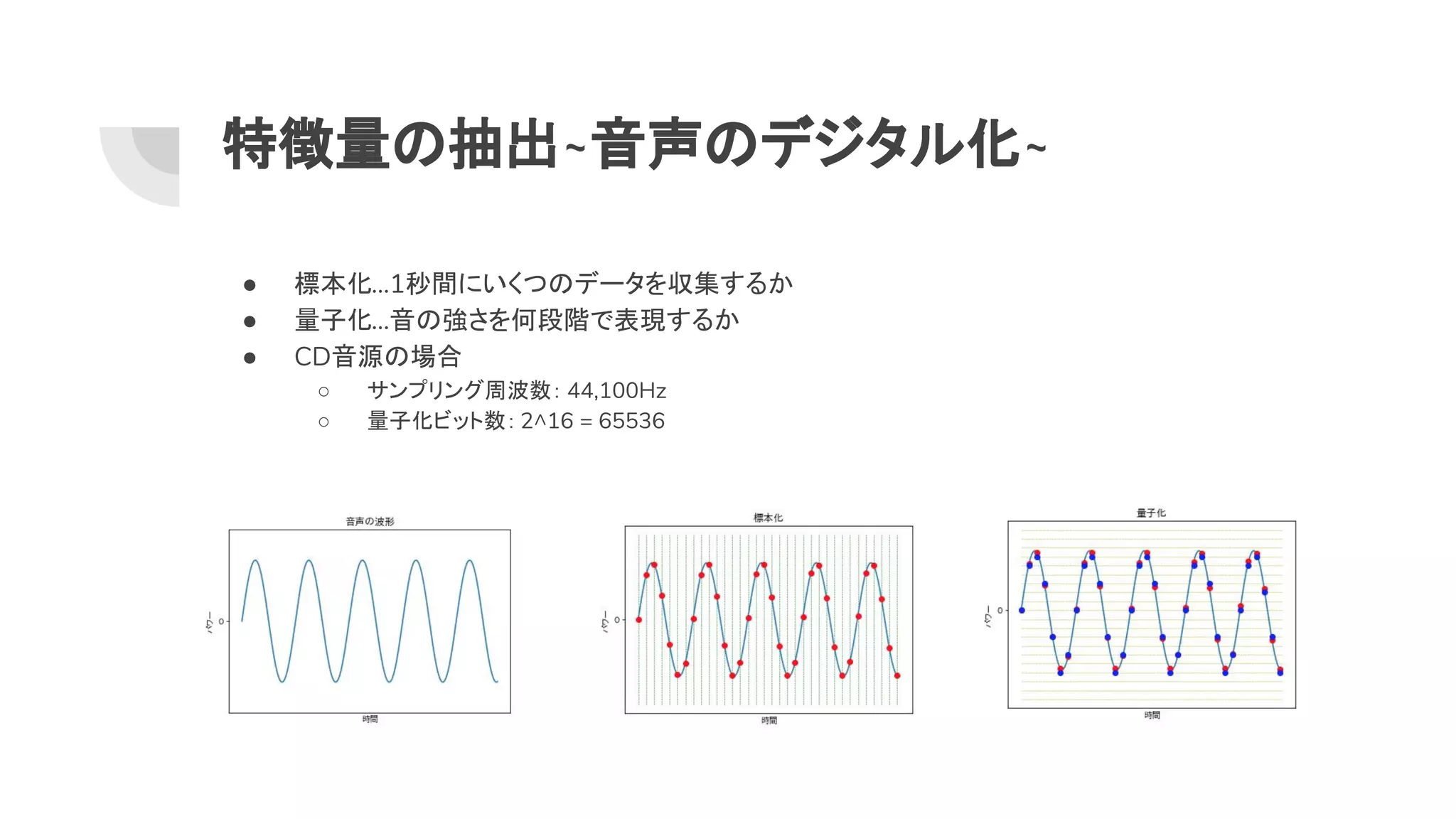
9. 10. 特徴量 抽出~音声 デジタル化~
● 標本化...1秒間にいくつ データを収集するか
● 量子化...音 強さを何段階で表現するか
● CD音源 場合
○ サンプリング周波数: 44,100Hz
○ 量子化ビット数: 2^16 = 65536
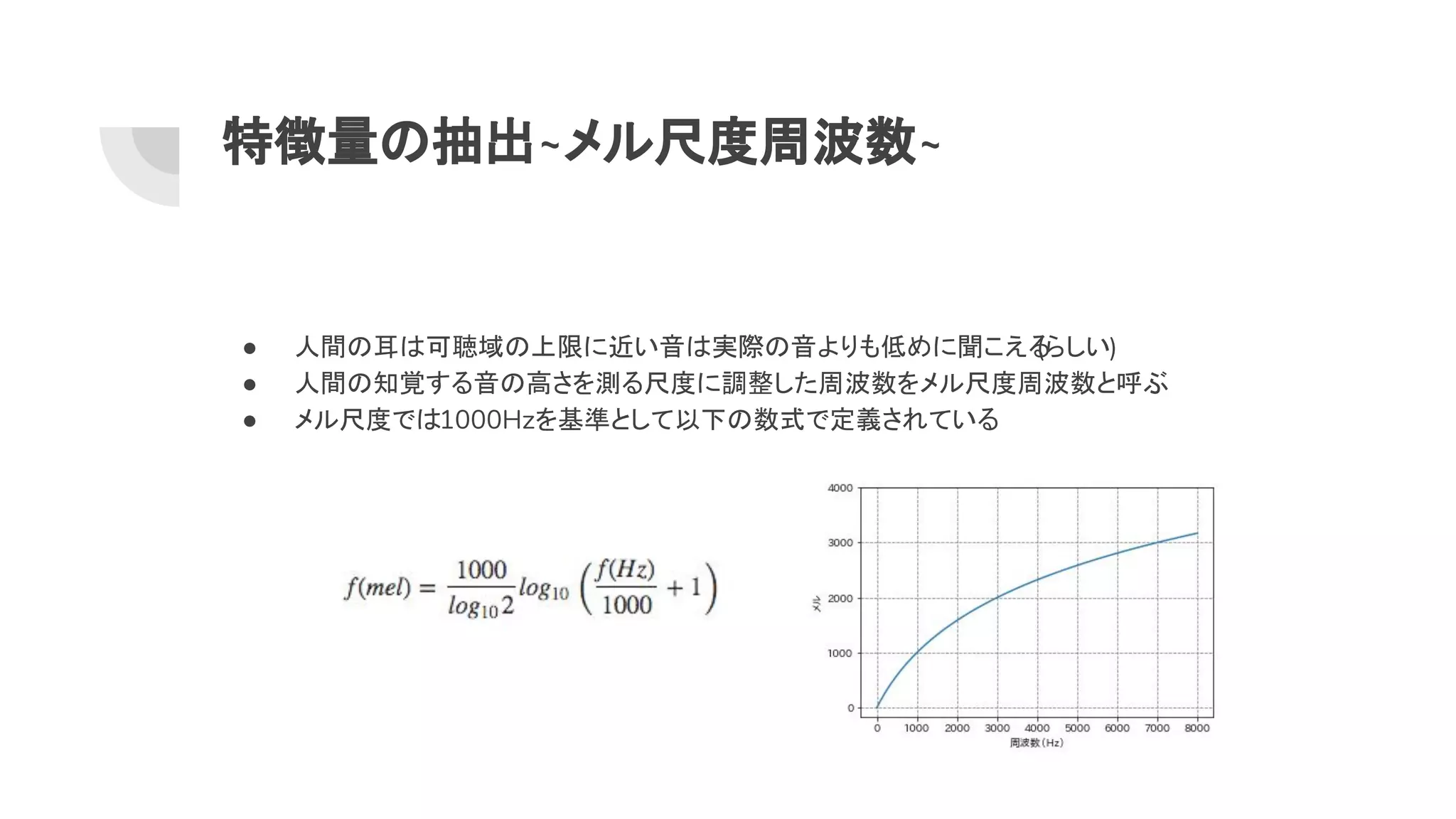
11. 12. 特徴量 抽出~メル尺度周波数~
● 人間 耳 可聴域 上限に近い音 実際 音よりも低めに聞こえる(らしい)
● 人間 知覚する音 高さを測る尺度に調整した周波数をメル尺度周波数と呼ぶ
● メル尺度で 1000Hzを基準として以下 数式で定義されている
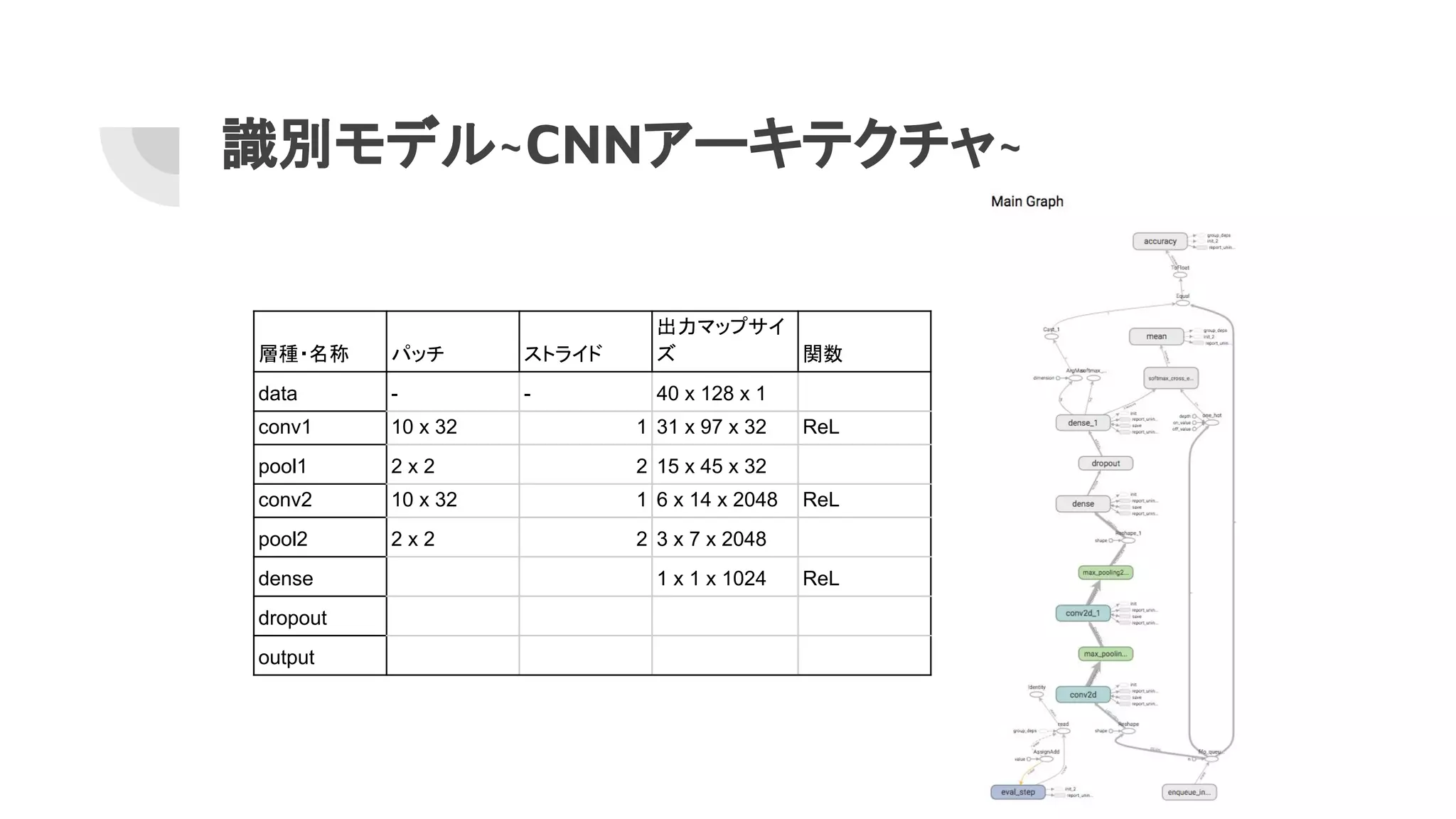
13. 14. 15. 16. 17. 識別モデル~CNNアーキテクチャ~
層種・名称 パッチ ストライド
出力マップサイ
ズ 関数
data - - 40 x 128 x 1
conv1 10 x 32 1 31 x 97 x 32 ReL
pool1 2 x 2 2 15 x 45 x 32
conv2 10 x 32 1 6 x 14 x 2048 ReL
pool2 2 x 2 2 3 x 7 x 2048
dense 1 x 1 x 1024 ReL
dropout
output
18. 19. 20. 21. 22. 23. 24. 参考文献
● 深層学習を使って楽曲 アーティスト分類をやってみた
○ http://blog.brainpad.co.jp/entry/2018/04/17/143000
● GMM-UBMライブラリ
○ https://github.com/liuxp0827/govpr
● Text-Independent Speaker Verification Using 3D Convolutional Neural Networks
○ Torfi A, Dawson J, Nasrabadi N, ArXiv ID 1705.09422, 2017























![[Slide]DevLOVE iPhoneアプリ勉強会の【前説】※本編は未公開です!](https://cdn.slidesharecdn.com/ss_thumbnails/slideiphone-100903062019-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)














































