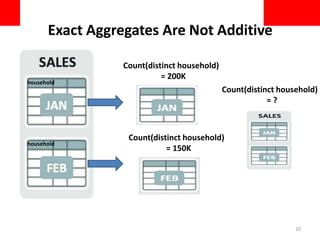
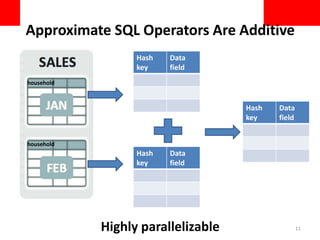
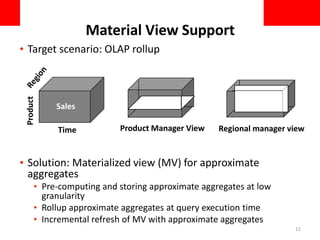
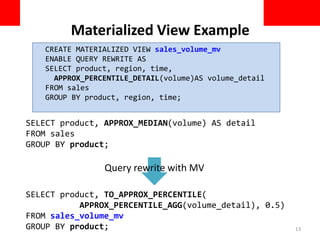
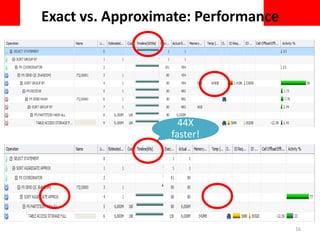
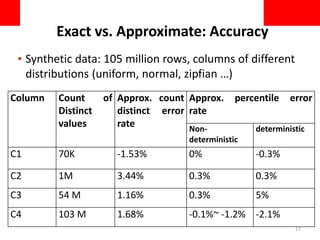
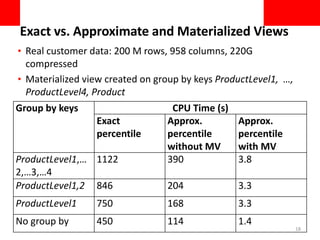
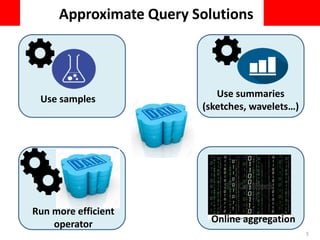
This document discusses using approximate query processing techniques in Oracle 12C to handle big data analytics challenges. It introduces approximate aggregates that use bounded memory and are highly parallelizable. Approximate aggregates can be rolled up and support materialized view rewrite, offering significant performance gains over exact aggregates while maintaining high accuracy within a few percentage points. Experimental results on real customer data show approximate queries running over 40 times faster than exact queries.




![Approximate Count Distinct
• Based on Hyperloglog probabilistic counting
algorithm [FFG+07]
• Uses bounded memory (~4K bytes) per group by key
• Optimized to use smaller memory when group is small
• Significantly reduces chance to spill to disk
8
[FFG+07] Hyperloglog: the analysis of a near-optimal cardinality estimation
algorithm. Flajolet, Fusy, Gandouet and Meunier. Proceedings of the 2007
international conference on the analysis of algorithms.
SELECT APPROX_COUNT_DISTINCT(household),
APPROX_COUNT_DISTINCT(creditcard)
FROM sales
Group by region;](https://image.slidesharecdn.com/565e1830-7afd-446f-b023-a4702aabe9d2-161108212022/85/cikm_2016_1027-8-320.jpg)
![Approximate Percentile
• Offers both deterministic and non-deterministic alternatives
• Deterministic: Count-min sketch [C09]
• Results immune to data arrival order
• Non-deterministic: RANDOM [WLY+ 13]
• generally faster (default)
• Bounded memory (~8K bytes) per group by key – 2% error rate
with 95% confidence
9
[WLYC13] Quantiles over data streams: an experimental study, SIGMOD 2013
[C09] Count-min sketch. Cormode. Encyclopedia of database systems 2009
SELECT APPROX_MEDIAN(volume [DETERMINISTIC])
FROM sales
GROUP BY region;](https://image.slidesharecdn.com/565e1830-7afd-446f-b023-a4702aabe9d2-161108212022/85/cikm_2016_1027-9-320.jpg)