Taal- en Spraaktechnologie voor het ontsluiten van gesproken archieven Peter van der Maas NIOD, Amsterdam Willemijn Heeren & Arjan van Hessen Human Media Interaction Universiteit Twente
2.
Achtergrond Probleemstelling Ontsluitingvan spraakarchieven Toegang tot gesproken bronnen Mogelijke oplossingen vanuit de spraak- & taaltechnologie Ontsluiting Toegang Projecten Radio Oranje Buchenwald Levende Herinneringen Erfgoed van de Oorlog (VWS) Conclusie Inhoud Achtergrond Probleemstelling Oplossingen Voorbeelden Conclusie Inhoud
Er komen meeren meer ‘digitale’ collecties op verschillende plaatsen beschikbaar Handmatige ontsluiting blijft kostbaar en tijdrovend We willen op basis van zoektermen door een collectie kunnen zappen (verticaal), maar ook tussen verschillende collecties (horizontaal) Gebruik van de collecties is niet (meer) locatiegebonden Buchenwald Inhoud Achtergrond Probleem Ontsluiting Toegang Oplossingen Voorbeelden Conclusie Achtergrond
Ontsluiting vanaudio(visuele) archieven Archiefbeschrijvingen vaak per band, per programma of per uur Handmatig genereren van metadata is bijzonder duur tijdrovend (1 tot 10 keer de duur van de audio) mogelijke verspilling van energie (omdat vooraf niet altijd bekend is welke informatie opgevraagd zal worden) Er is geen directe link tussen gesproken en geschreven data waardoor efficiënt ontsluiten niet of nauwelijks mogelijk is. Inhoud Achtergrond Probleem Ontsluiting Toegang Oplossingen Voorbeelden Conclusie Probleemstelling
8.
Toegang totaudio(visuele) archieven Zoeken in gesproken informatie is op dit moment lastig: tijdrovend en weinig nauwkeurig Handmatig ingevoerde catalogi zijn online doorzoekbaar; resultaten hebben wel een link naar het (complete) audiomateriaal, maar niet naar een positie IN het audiomateriaal => Potentieel waardevol materiaal (voor wetenschap, onderwijs, amateurs, etc.) is hierdoor maar beperkt toegankelijk Inhoud Achtergrond Probleem Ontsluiting Toegang Oplossingen Voorbeelden Conclusie Probleemstelling
9.
Ontsluiting van grotehoeveelheden materiaal -> automatisch genereren van metadata Methode is afhankelijk van beschikbare metadata. Als de transcriptie: Afwezig is Automatische Spraakherkenning Hypothese genereren van wat waar gezegd wordt. Een Word Error Rate (WER) onder 50% voldoende voor het gebruik van spraakherkenningsresultaten als zoekindex. Aanwezig is Oplijning van spraak en transcript. Het is niet noodzakelijk dat het om een letterlijke transcriptie gaat, zolang de volgorden maar overeenkomen. Automatisch bepalen wat waar gezegd wordt. Inhoud Achtergrond Probleem Oplossingen Ontsluiting Toegang Voorbeelden Conclusie Oplossingen vanuit taal- & spraaktechnologie
10.
Ontsluiting: automatisch genererenvan (tijdgebonden) metadata Herken de gesproken tekst “zo goed mogelijk” Bepaal op welke manier dan ook segmentgrenzen (story boundaries, sprekerwisselingen, etc.) Benoem (classificeer) de segmenten Herhaal desnoods de herkenning maar nu met een speciaal contextmodel (bv concentratiekampen of Nederlandsch-Indiën) Cluster de segmenten door: alle niet-relevante woorden uit de herkenning te filteren en de relevante woorden te bewaren segmenten te koppelen aan andere segmenten met min-of-meer dezelfde steekwoorden (Clustering) Inhoud Achtergrond Probleem Oplossingen Ontsluiting Toegang Voorbeelden Conclusie Oplossingen vanuit taal- & spraaktechnologie
11.
Maak het materiaalonline doorzoekbaar en gebruik slimme zoektechnologie Gebruik semantische informatie (vb. thesauri) fiets, rijwiel, mountainbike -> “fiets” Probeer de zoekvraag te interpreteren “ mooie meisje” -> “mooie meisje”, meisje xxx yyy is mooi, knappe vrouw, leuke jongedame Niet: “op een mooie dag loopt het meisje”, of “mooi zei het meisje” Inhoud Achtergrond Probleem Oplossingen - Ontsluiting - Toegang Voorbeelden Conclusie Oplossingen vanuit taal- & spraaktechnologie
12.
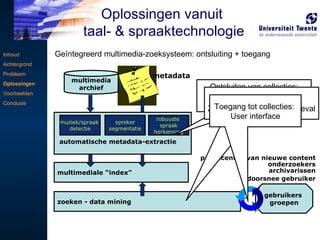
Ontsluiten van collecties:genereren van metadata/index Toegang tot collecties: Zoeken - Information Retrieval Toegang tot collecties: User interface Inhoud Achtergrond Probleem Oplossingen Voorbeelden Conclusie Geïntegreerd multimedia-zoeksysteem: ontsluiting + toegang Oplossingen vanuit taal- & spraaktechnologie onderzoekers archivarissen doorsnee gebruiker producenten van nieuwe content multimediale “index” zoeken - data mining automatische metadata-extractie robuuste spraak herkenning muziek/spraak detectie spreker segmentatie multimedia archief metadata gebruikers groepen
13.
Access to OralHistory (2006-2010) Doel: Onderzoeken en ontwikkelen van (spraak)technologie voor de ontsluiting van en toegang tot historische audiocollecties. Samenwerking tussen Human Media Interaction, Universiteit Twente, Gemeentearchief Rotterdam, RTV Rijnmond, Erasmus Universiteit Rotterdam. Onderdeel van het NWO CATCH programma (www.nwo.nl/catch). Voorbeeldproject Inhoud Achtergrond Probleem Oplossingen Voorbeelden - Radio Oranje Buchenwald Conclusie CHoral
14.
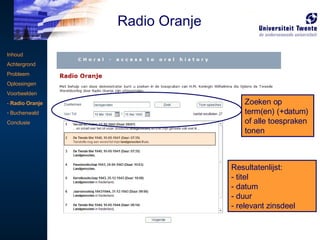
Online toegankelijk endoorzoekbaar maken van toespraken van H.M. Koningin Wilhelmina, gericht aan het Nederlandse volk tijdens de Tweede Wereldoorlog en uitgezonden vanuit Londen, Engeland. Zowel de audio als de teksten zijn bewaard gebleven, én gedigitaliseerd (door het Nederlands Instituut voor Oorlogsdocumentatie in samenwerking met het Nederlands Instituut voor Beeld en Geluid). Inhoud Achtergrond Probleem Oplossingen Voorbeelden - Radio Oranje Buchenwald Conclusie Radio Oranje
15.
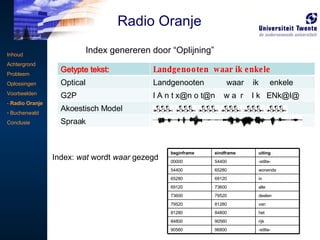
Index genereren door“Oplijning” Index: wat wordt waar gezegd Inhoud Achtergrond Probleem Oplossingen Voorbeelden - Radio Oranje Buchenwald Conclusie Radio Oranje beginframe eindframe uiting 00000 54400 -stilte- 54400 65280 wonende 65280 69120 in 69120 73600 alle 73600 79520 deelen 79520 81280 van 81280 84800 het 84800 90560 rijk 90560 96800 -stilte- Getypte tekst: Landgenooten waar ik enkele Optical Landgenooten waar ik enkele G2P l A n t x@n o t @ n w a r I k ENk@l@ Akoestisch Model Spraak
16.
User Interface: zoeken Resultatenlijst: titel datum duur relevant zinsdeel Inhoud Achtergrond Probleem Oplossingen Voorbeelden - Radio Oranje Buchenwald Conclusie Zoeken op term(en) (+datum) of alle toespraken tonen Radio Oranje
17.
Multimediapresentatie - fotopresentatie - ondertiteling visuele weergave v/d content besturingsknoppen Semi-automatisch geselecteerd uit NIOD fotodatabase (> 120.000 foto’s) Inhoud Achtergrond Probleem Oplossingen Voorbeelden - Radio Oranje Buchenwald Conclusie Radio Oranje
18.
Inhoud Achtergrond ProbleemOplossingen Voorbeelden - Radio Oranje Buchenwald Conclusie Materiaal: 37 gefilmde interviews (60 uur) van mannen die in Buchenwald gezeten hebben. Korte samenvattingen per interview zijn beschikbaar Ieder interview duurt minimaal één uur: veel te lang dus! Combineren van onderdelen van de interviews die min of meer over dezelfde informatie gaan (zelfde clusters) maakt het thematisch “aanbieden van” en “zoeken naar” eenvoudig mogelijk. Buchenwald
19.
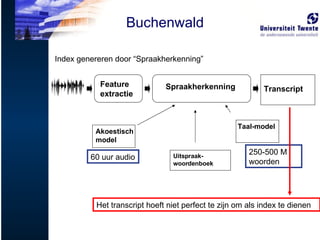
Akoestisch model Taal-modelTranscript Uitspraak-woordenboek Index genereren door “Spraakherkenning” Feature extractie Spraakherkenning 60 uur audio 250-500 M woorden Buchenwald Het transcript hoeft niet perfect te zijn om als index te dienen
20.
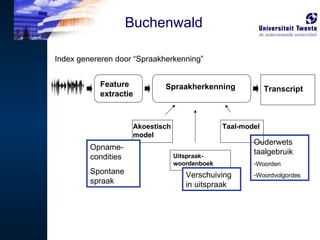
Index genereren door“Spraakherkenning” Akoestisch model Taal-model Uitspraak-woordenboek Transcript Opname-condities Spontane spraak Ouderwets taalgebruik Woorden Woordvolgordes Verschuiving in uitspraak Buchenwald Feature extractie Spraakherkenning
21.
Inhoud Achtergrond ProbleemOplossingen Voorbeelden - Radio Oranje Buchenwald Conclusie Levende Herinneringen heeft als doel het behoud en de overdracht van de Indische cultuur. Middels video diepte-interviews worden actief getuigenissen verzameld over diverse belevingen van Indische identiteit. Ruim 900 oudere personen met een “Indisch verleden” zullen worden geïnterviewd. Hiermee zullen hun waardevolle herinneringen niet verloren gaan voor toekomstige generaties. Jongere mensen kunnen zelfstandig hun eigen getuigenissen aan het archief toevoegen. Het archief dat hiermee tot stand komt, is voor iedereen ten allen tijden openbaar toegankelijk via Internet.
22.
Inhoud Achtergrond ProbleemOplossingen Voorbeelden - Radio Oranje Buchenwald Conclusie Erfgoed van de Oorlog In Nederland is veel erfgoedmateriaal aanwezig uit de Tweede Wereldoorlog en materiaal dat betrekking heeft op deze periode. Dit erfgoed bestaat bijvoorbeeld uit archieven, foto’s, film en geluidsopnamen, voorwerpen en sporen in het landschap. Het programma Erfgoed van de Oorlog is erop gericht dit erfgoedmateriaal te traceren en te inventariseren. VWS zorgt ervoor dat eigenaars en beheerders van erfgoed deze materialen goed kunnen bewaren en zo veel mogelijk toegankelijk kunnen maken. De Tweede Wereldoorlog is een belangrijke periode in de Nederlandse geschiedenis. Nederland bevindt zich in een nieuwe fase in de naoorlogse geschiedenis. Er zijn steeds minder mensen die de oorlog zelf hebben meegemaakt. Het levend houden van de herinnering aan de oorlog en de betekenis ervan voor onze samenleving is een belangrijk onderdeel van het programma Erfgoed van de Oorlog. Het is de ambitie van VWS deze periode meer te laten zijn dan een passage in een geschiedenisboek. Het is daarom belangrijk dat de jaren '40-45' en de nasleep ervan goed wordt gedocumenteerd. Het actief gebruiken van erfgoedmateriaal draagt hieraan bij.
23.
Om gesproken materiaalsuccesvol te ontsluiten is het noodzakelijk dat Het materiaal gedigitaliseerd is De spraak getranscribeerd en opgelijnd wordt Het materiaal geclassificeerd wordt Er metadata aan toegevoegd wordt (foto’s, links, andere teksten, etc.) Er een (slimme) online zoekengine is Het materiaal multi-modaal gepresenteerd wordt (momomodaal is saai ) Inhoud Achtergrond Probleem Oplossingen Voorbeelden Conclusie Conclusie