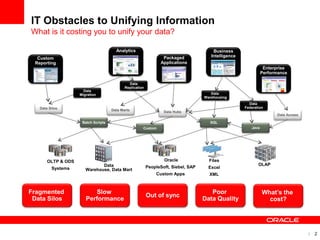
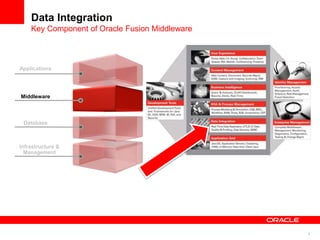
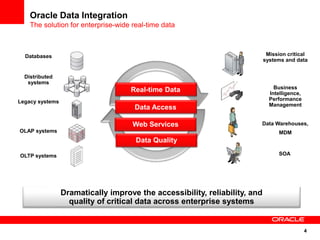
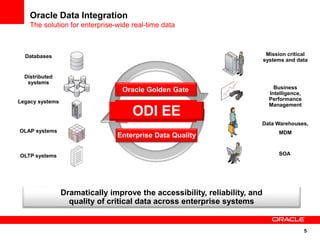
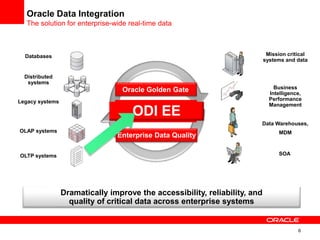
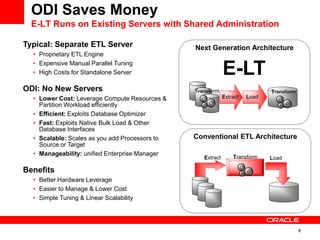
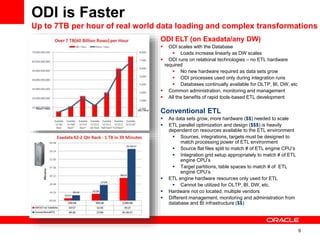
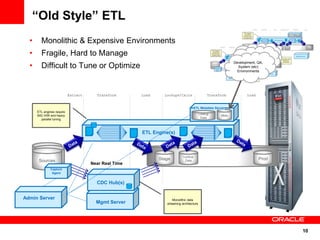
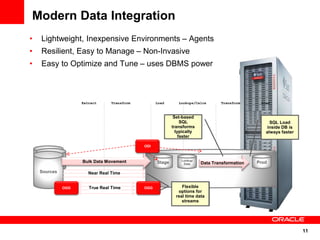
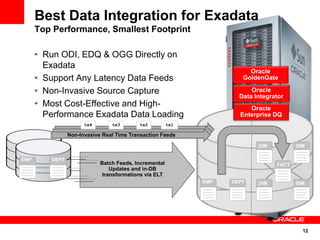
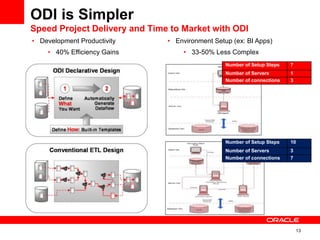
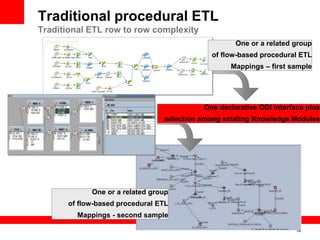
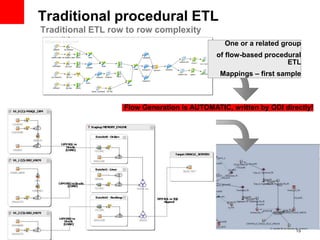
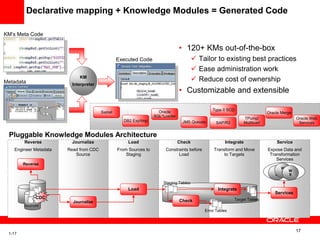
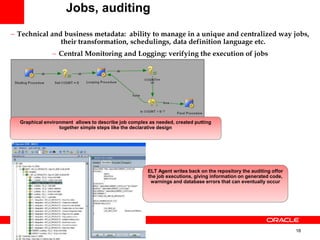
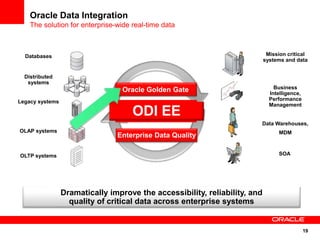
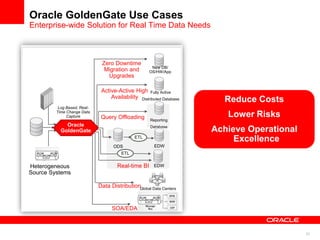
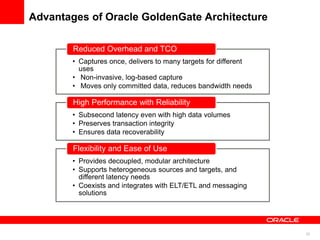
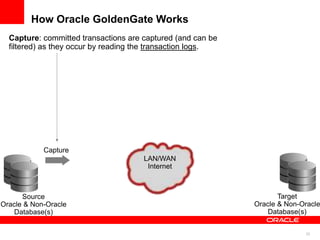
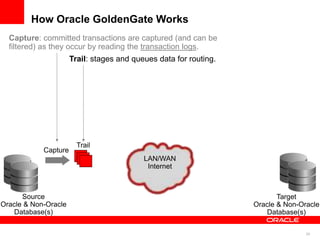
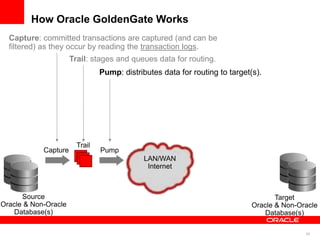
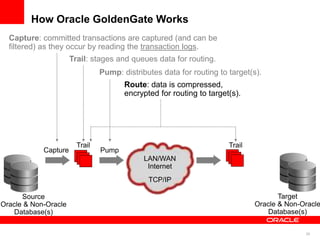
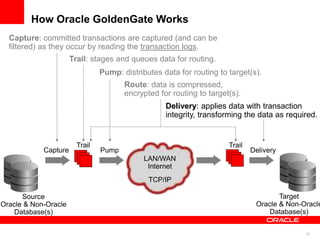
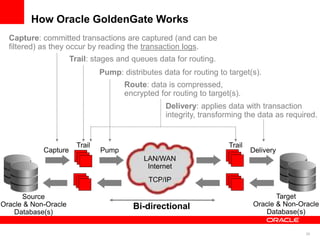
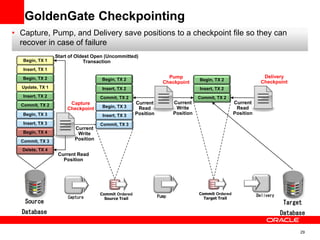
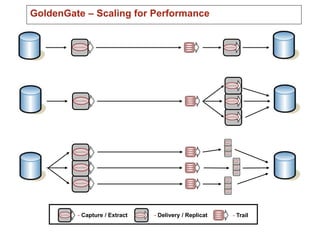
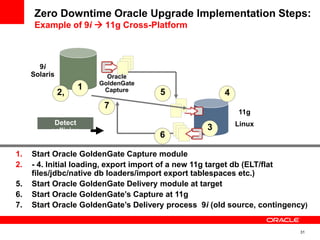
The document introduces Oracle Data Integrator and Oracle GoldenGate as solutions for enterprise data integration. It discusses challenges with fragmented data silos and the need to improve data accessibility, reliability, and quality across systems. Oracle Data Integrator is presented as a solution for real-time enterprise data integration using an ELT approach. It can integrate data across various systems faster and with lower total cost of ownership compared to traditional ETL. Oracle GoldenGate enables real-time data replication and change data capture. Together, Oracle Data Integrator and Oracle GoldenGate provide a full suite for batch, incremental, and real-time data integration.