Downloaded 85 times



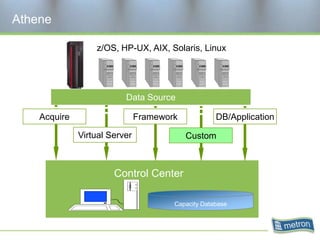


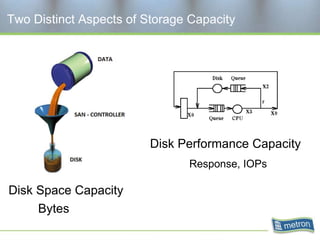
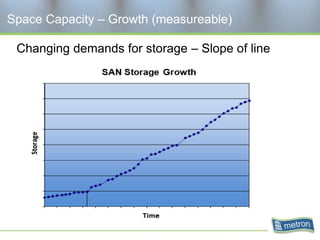
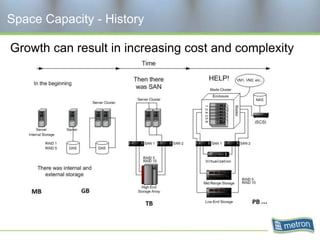

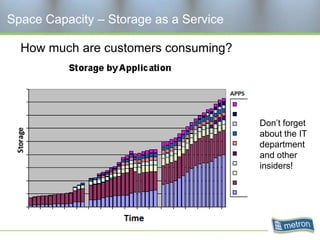
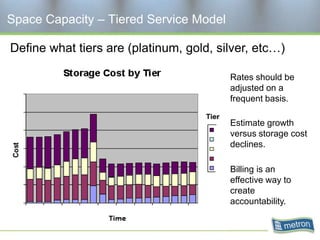




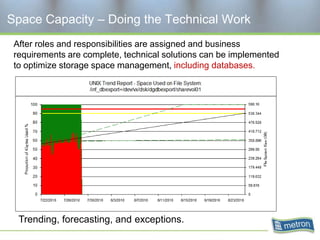
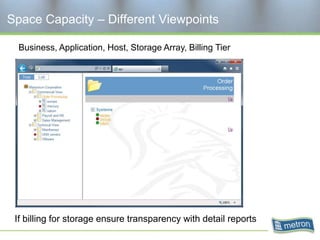
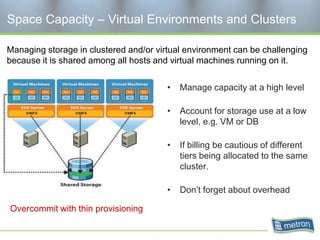
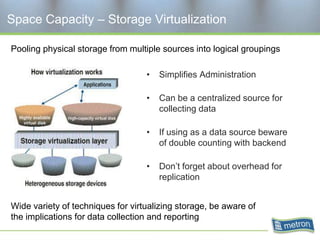

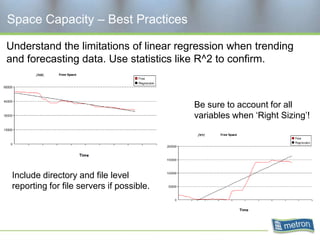
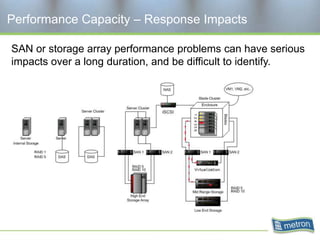

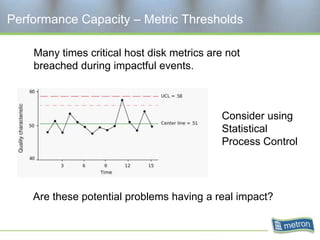
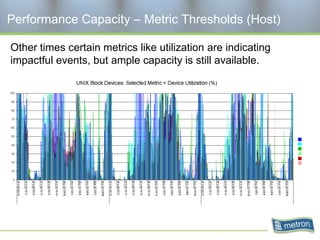
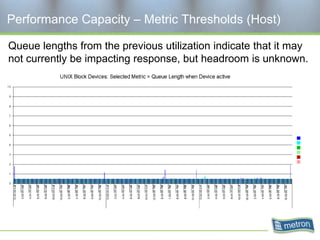
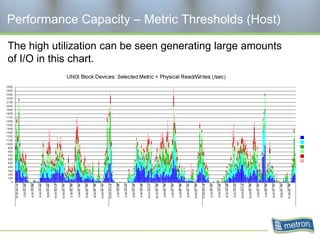
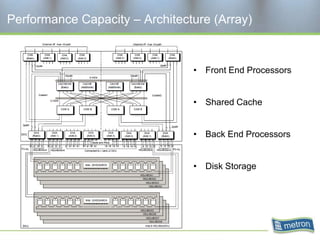
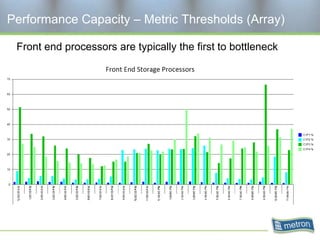
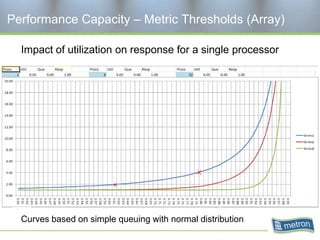
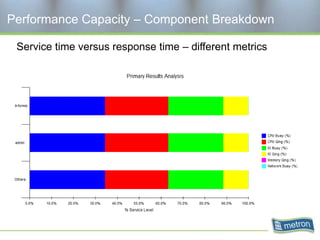
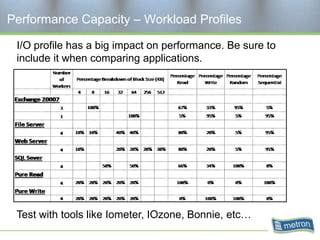

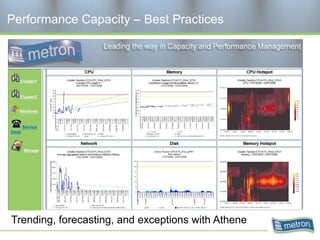




Metron provides capacity management tools and services for storage area networks (SANs). The document discusses two aspects of storage capacity - disk space and performance. It emphasizes the importance of tracking storage usage and costs, implementing tiered billing models, and using tools like Athene to forecast needs, track utilization across virtual and clustered environments, and establish performance baselines and thresholds. Effective capacity management requires collaboration between business and IT stakeholders to understand usage and ensure storage supports business goals.




















































