Download as PDF, PPTX

























![Bytecode interpretation
z = 2 x * y *
[ ]](https://image.slidesharecdn.com/rustdsl-181207130559/85/Building-fast-interpreters-in-Rust-28-320.jpg)
![Bytecode interpretation
z = 2 x * y *
[ ]](https://image.slidesharecdn.com/rustdsl-181207130559/85/Building-fast-interpreters-in-Rust-29-320.jpg)
![Bytecode interpretation
z = 2 x * y *
[ 2 ]](https://image.slidesharecdn.com/rustdsl-181207130559/85/Building-fast-interpreters-in-Rust-30-320.jpg)
![Bytecode interpretation
z = 2 x * y *
[ 2, x ]](https://image.slidesharecdn.com/rustdsl-181207130559/85/Building-fast-interpreters-in-Rust-31-320.jpg)
![Bytecode interpretation
z = 2 x * y *
[ 2 * x ]](https://image.slidesharecdn.com/rustdsl-181207130559/85/Building-fast-interpreters-in-Rust-32-320.jpg)
![Bytecode interpretation
z = 2 x * y *
[ 2 * x, y ]](https://image.slidesharecdn.com/rustdsl-181207130559/85/Building-fast-interpreters-in-Rust-33-320.jpg)
![Bytecode interpretation
z = 2 x * y *
[ (2 * x) * y ]](https://image.slidesharecdn.com/rustdsl-181207130559/85/Building-fast-interpreters-in-Rust-34-320.jpg)















![LLVM from Rust
let module = context.create_module("module");
let func = module.add_function(
"jit_compiled",
f64type.fn_type(&[
f64type.into(),
f64type.into()
], false),
None,
);](https://image.slidesharecdn.com/rustdsl-181207130559/85/Building-fast-interpreters-in-Rust-52-320.jpg)

















![Cranelift
let entry_ebb = builder.create_ebb();
builder.append_ebb_params_for_function_params(entry_ebb);
builder.switch_to_block(entry_ebb);
builder.seal_block(entry_ebb);
let result = ...;
builder.ins().return_(&[result]);
builder.finalize();](https://image.slidesharecdn.com/rustdsl-181207130559/85/Building-fast-interpreters-in-Rust-72-320.jpg)
![Cranelift
Expr ::Literal(lit) => {
let ins = builder.ins();
ins.f64const(Ieee64 ::with_float(*lit))
}
Expr ::Variable(var) => builder.ebb_params(ebb)[ ...],
Expr ::Binary { lhs, op, rhs } => {
let lhs = lhs.compile( ...);
let rhs = rhs.compile( ...);
let ins = builder.ins();
match op {
BinOp ::Add => ins.fadd(lhs, rhs),
...
}
}](https://image.slidesharecdn.com/rustdsl-181207130559/85/Building-fast-interpreters-in-Rust-73-320.jpg)




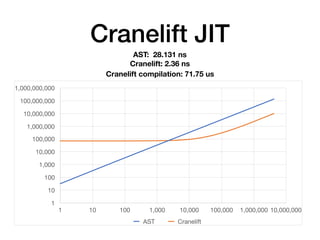
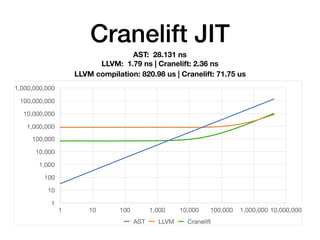
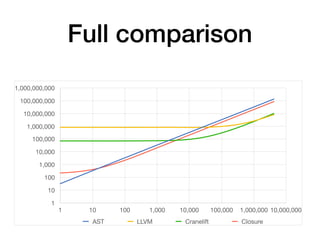

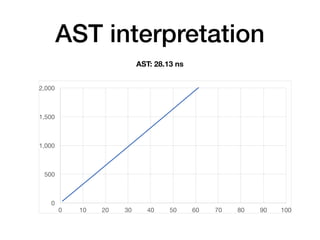
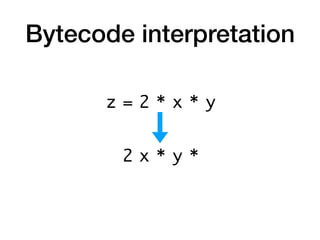
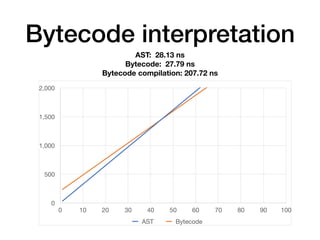
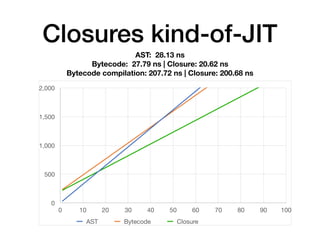
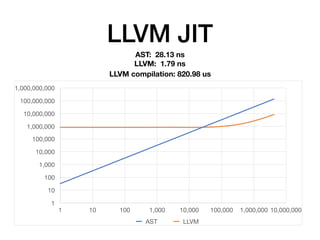
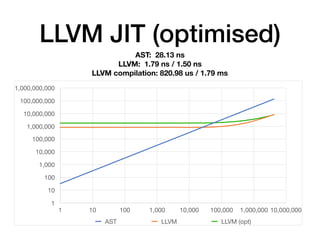
The document discusses the creation of a custom domain-specific language (DSL) in Rust, detailing its abstract syntax tree (AST) representation and parsing techniques using libraries like Nom and Combine. It also explores various methods of interpreting, compiling, and running the DSL, including bytecode interpretation and just-in-time (JIT) compilation using LLVM and Cranelift. Additionally, it provides code examples and performance metrics for the different compilation techniques used.













































































