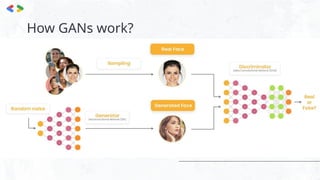
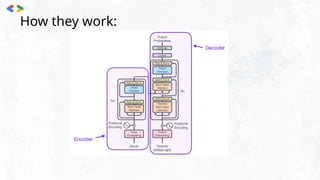
The document provides an introduction to generative AI, explaining its capabilities to create new content and its applications across various domains such as video, image, text, music, and game generation. It discusses the mechanics of Generative Adversarial Networks (GANs), detailing how a generator and discriminator work in tandem to improve the quality of generated data. The document also covers large language models (LLMs), including their types, functionalities, and distinctions between open-sourced and closed-sourced models, with practical notebooks linked for further exploration.