Download to read offline


















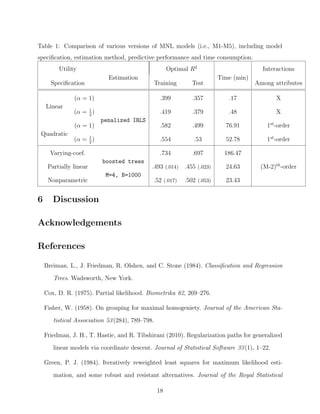


This document proposes applying boosting techniques to attraction-based demand models that are popular in pricing optimization. It formulates a multinomial likelihood for a semiparametric demand choice model (DCM) where product utility is specified without a fixed functional form. Gradient boosting is used to maximize the likelihood and estimate the nonparametric utility functions. The boosted tree-based approach flexibly models utility as a sum of trees, addressing limitations of existing DCMs like non-stationary demand and nonlinear attribute effects.












































































