















































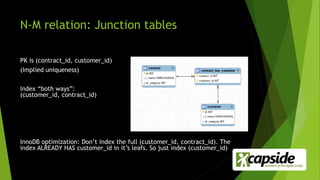











The document discusses best practices for database optimization, emphasizing that proper schema design and careful selection of data types are crucial for performance and scalability. It advises against premature optimization, highlights the importance of indexing, and addresses the pitfalls of using certain data types and structures. Ultimately, it promotes a thoughtful approach to database design to avoid common pitfalls that hinder scalability.






















































