Download to read offline




























![AGGREGATION - MEMORY CONSTRAINTS
➤ Results are subject to 16 MB
➤ Use $limit and $project
➤ 100MB limit per stage
➤ Use indexes
➤ db.orders.aggregate([], {allowDiskUse: true})](https://image.slidesharecdn.com/boosting-mongodb-performance-180522182906/85/Boosting-MongoDB-performance-33-320.jpg)


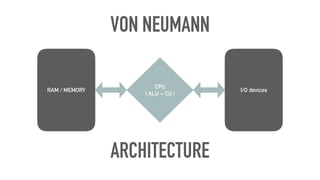
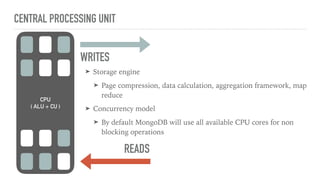
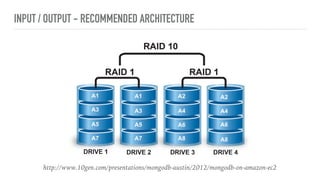
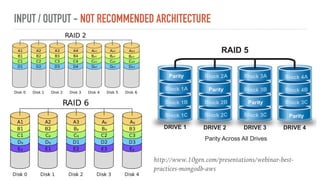
This document discusses various aspects of optimizing MongoDB performance, including hardware considerations, indexing strategies, and I/O operations. It highlights the importance of utilizing CPU resources efficiently, creating different types of indexes, and managing memory constraints during aggregation operations. Techniques for enhancing write performance and understanding query execution are also addressed.





















































