A dataset of schema transitions from the evolution history of the database of an AI assistant over 10 years. It contains 100 transitions.
Wikipedia: A dataset of schema transitions from the evolution history of the database behind the Wikipedia website over 15 years. It contains 250 transitions.
Hospital: A dataset of schema transitions from the evolution history of the database of a hospital information system over 7 years. It contains 50 transitions.
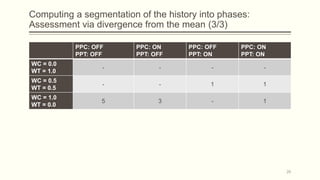
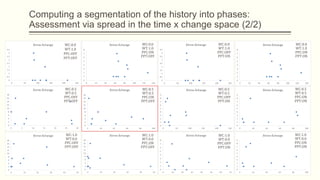
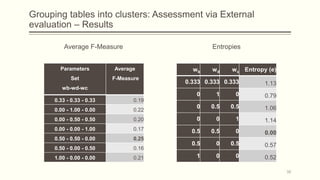
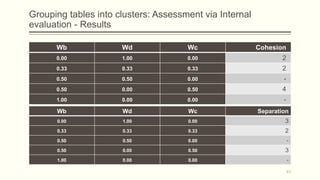
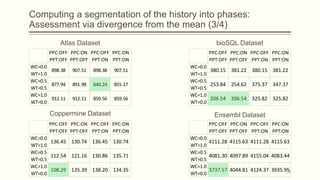
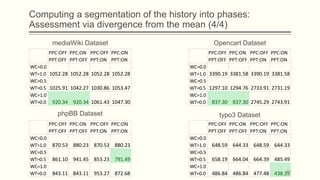
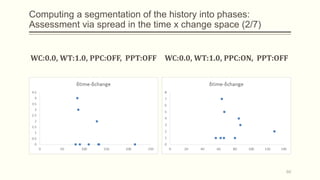
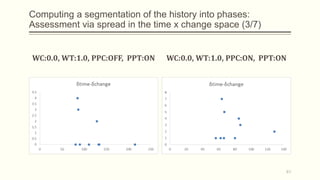
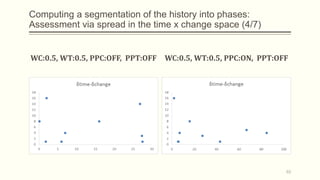
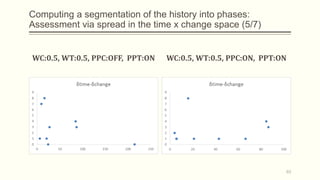
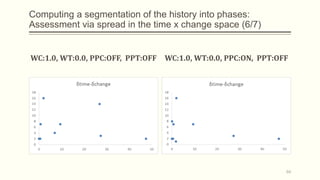
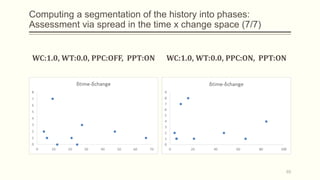
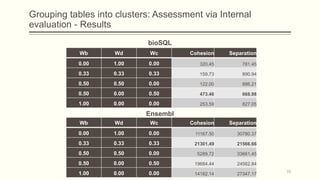
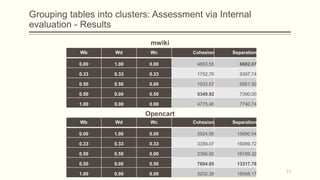
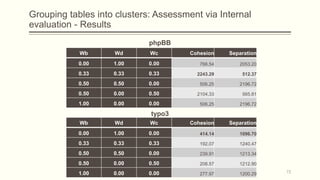
For each dataset, we run Phasic Extractor for different values of k and we compute the divergence from the mean for each extracted phase. Lower values indicate better quality phases.
We can observe that for k close to the “ground truth” number of phases:
- Assistant: 3 phases










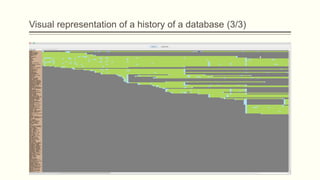
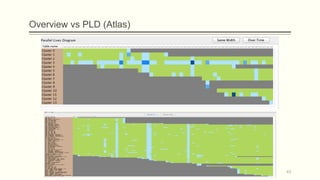
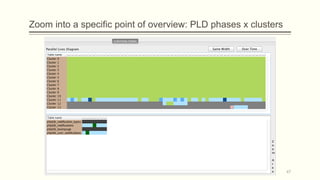
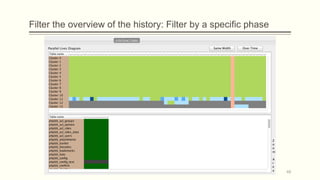
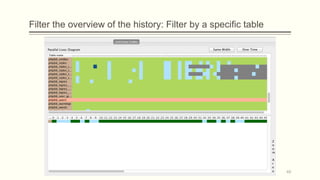
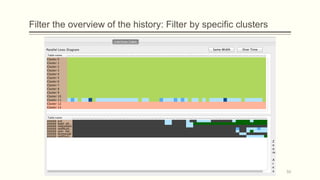
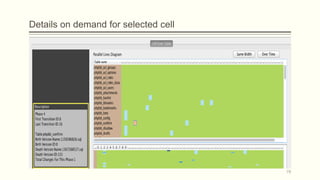
![Visual representation of a history of a database (1/3)
Parallel (Table) Lives Diagram of a database schema: a two dimensional rectilinear
grid having all the revisions of the schema’s history as columns and all the relations of
the diachronic schema as its rows
Each cell PLD[i,j] represents the changes undergone and the status of the relation at row
i during the revision j.
11](https://image.slidesharecdn.com/3e314155-2544-4d1d-b0b3-e1fb58dee237-160105192727/85/Biography-synopses-Thesis-Presentation-Final-11-320.jpg)


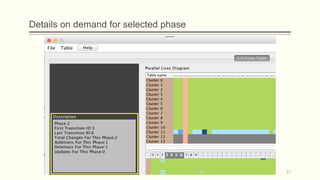
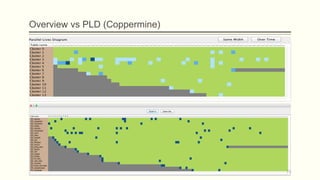
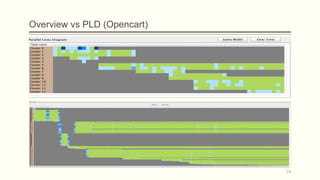
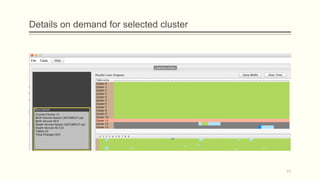
![Intuition on the problem
The idea came from the mantra that Shneiderman underlines in his article at 1996
[Shne96], which is
Overview first, zoom and filter, details on demand.
15
Construct an
overview
instead of a
non-fitting
diagram](https://image.slidesharecdn.com/3e314155-2544-4d1d-b0b3-e1fb58dee237-160105192727/85/Biography-synopses-Thesis-Presentation-Final-15-320.jpg)

































![References
[ECLI15] Eclipse IDE. Available at https://eclipse.org/downloads/. Last accessed 2015-09-30.
[HECA15] Hecate. Available at https://github.com/daintiness-group/hecate . Last accessed 2015-09-30.
[PPL15] Plutarch’s Parallel Lives at https://github.com/daintiness-group/plutarch_parallel_lives. Last
accessed 2015-09-30
[Shne96] Shneiderman, Ben. "The eyes have it: A task by data type taxonomy for information
visualizations." Visual Languages, 1996. Proceedings., IEEE Symposium on. IEEE, 1996.
[SkVZ14] Skoulis, Ioannis, Panos Vassiliadis, and Apostolos Zarras. "Open-Source Databases: Within,
Outside, or Beyond Lehman’s Laws of Software Evolution?."Advanced Information Systems
Engineering. Springer International Publishing, 2014.
[TaSK05] Pang-Ning Tan, Michael Steinbach and Vipin Kumar. Introduction to Data Mining. 1st ed.
Pearson, 2005.
[TaTT06] Mielikäinen, Taneli, Evimaria Terzi, and Panayiotis Tsaparas. "Aggregating time
partitions." Proceedings of the 12th ACM SIGKDD international conference on Knowledge
discovery and data mining. ACM, 2006.
[TeTs06] Terzi, Evimaria, and Panayiotis Tsaparas. "Efficient Algorithms for Sequence
Segmentation." SDM. 2006.
[ZhSt05] Xing, Zhenchang, and Eleni Stroulia. "Analyzing the evolutionary history of the logical design
of object-oriented software." Software Engineering, IEEE Transactions on 31.10 (2005): 850-
868.
79](https://image.slidesharecdn.com/3e314155-2544-4d1d-b0b3-e1fb58dee237-160105192727/85/Biography-synopses-Thesis-Presentation-Final-79-320.jpg)



































