



















































































![78
Cells.FormatConditions.Delete
End Sub
#3 Close the open sheets
Sub CloseBooks()
Windows("case1_withschedule data.xlsx").Activate
Application.DisplayAlerts = False
ActiveWorkbook.Close
Windows("case2_withschedule data.xlsx").Activate
Application.DisplayAlerts = False
ActiveWorkbook.Close
Windows("case3_withschedule data.xlsx").Activate
Application.DisplayAlerts = False
ActiveWorkbook.Close
Windows("case4_withschedule data.xlsx").Activate
Application.DisplayAlerts = False
ActiveWorkbook.Close
End Sub
#4 Calculate duration and delay
Sub check_delay()
If Range("d6").Value = "" Then
MsgBox ("please copy the data")
Else
'To Claculate Which ever is greater days
Range("A1").Select
Selection.End(xlDown).Select
Selection.End(xlDown).Select
Selection.End(xlToRight).Select
ActiveCell.Offset(0, 1).Range("A1").Select
Selection.End(xlUp).Select
ActiveCell.Offset(1, 0).Range("A1").Select
ActiveCell.FormulaR1C1 = "=IF((RC[-6]-RC[-5])>(RC[-4]-RC[-
3]),(RC[-6]-RC[-5]),(RC[-4]-RC[-3]))"
Range("A1").Select
Selection.End(xlDown).Select
Selection.End(xlDown).Select
Selection.End(xlToRight).Select
ActiveCell.Offset(0, 1).Range("A1").Select
Range(Selection, Selection.End(xlUp)).Select
ActiveCell.FormulaR1C1 = ""
Selection.FormulaR1C1 = "=IF((RC[-6]-RC[-5])>(RC[-4]-RC[-
3]),(RC[-6]-RC[-5]),(RC[-4]-RC[-3]))"
'To Calculate Duration](https://image.slidesharecdn.com/finalreport-171112222604/85/BIM-Integrated-predictive-model-for-schedule-delays-in-Construction-88-320.jpg)
![79
Range("A1").Select
Selection.End(xlDown).Select
Selection.End(xlDown).Select
Selection.End(xlToRight).Select
ActiveCell.Offset(0, 1).Range("A1").Select
Selection.End(xlUp).Select
ActiveCell.Offset(1, 0).Range("A1").Select
ActiveCell.FormulaR1C1 = "(RC[-7]-RC[-5])"
Range("A1").Select
Selection.End(xlDown).Select
Selection.End(xlDown).Select
Selection.End(xlToRight).Select
ActiveCell.Offset(0, 1).Range("A1").Select
Range(Selection, Selection.End(xlUp)).Select
ActiveCell.FormulaR1C1 = ""
Selection.FormulaR1C1 = "=(RC[-7]-RC[-5])"
End If
End Sub](https://image.slidesharecdn.com/finalreport-171112222604/85/BIM-Integrated-predictive-model-for-schedule-delays-in-Construction-89-320.jpg)









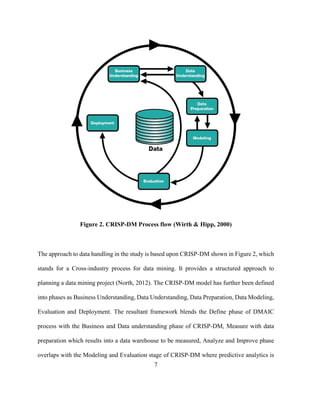
The document presents a BIM-integrated framework aimed at predicting schedule delays in modular construction, highlighting the critical issues of project delays and the potential of technology in mitigating these risks. It provides a structured methodological approach using data analytics within a framework aligned with the lean six sigma process, facilitating data-driven decision-making in construction management. The research addresses gaps in quantitative risk management techniques and emphasizes the importance of leveraging operational data for improved scheduling outcomes.




























![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Gordana Milutinovic Dumbelovic - From Insight to Oversight: A...](https://cdn.slidesharecdn.com/ss_thumbnails/t7dkjsfxqwwzceropjv4-gordana-milutinovicdumbelovic-from-insight-to-oversight-ai-driven-power-bi-moni-260119121559-9e0bf11b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)

