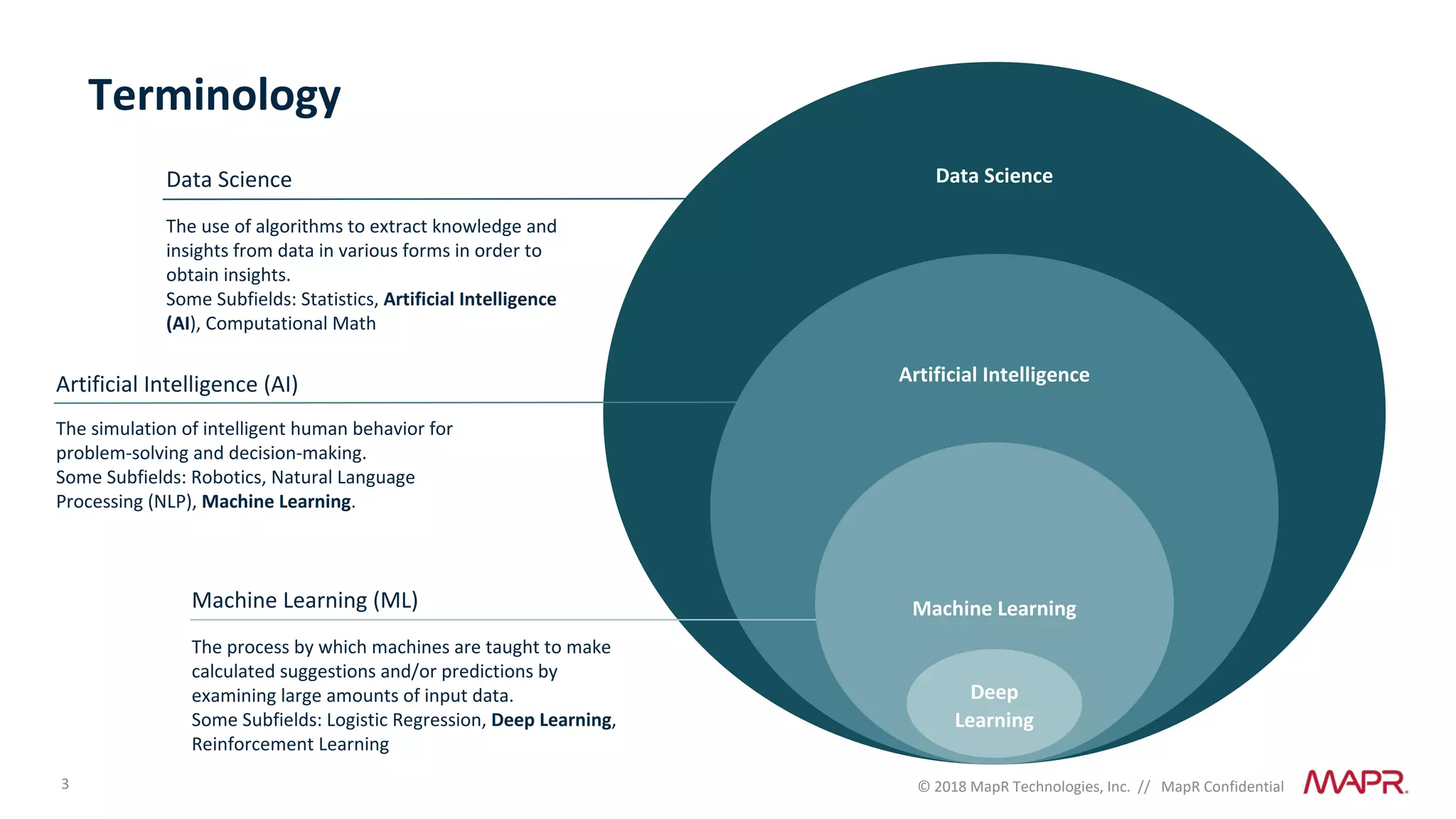
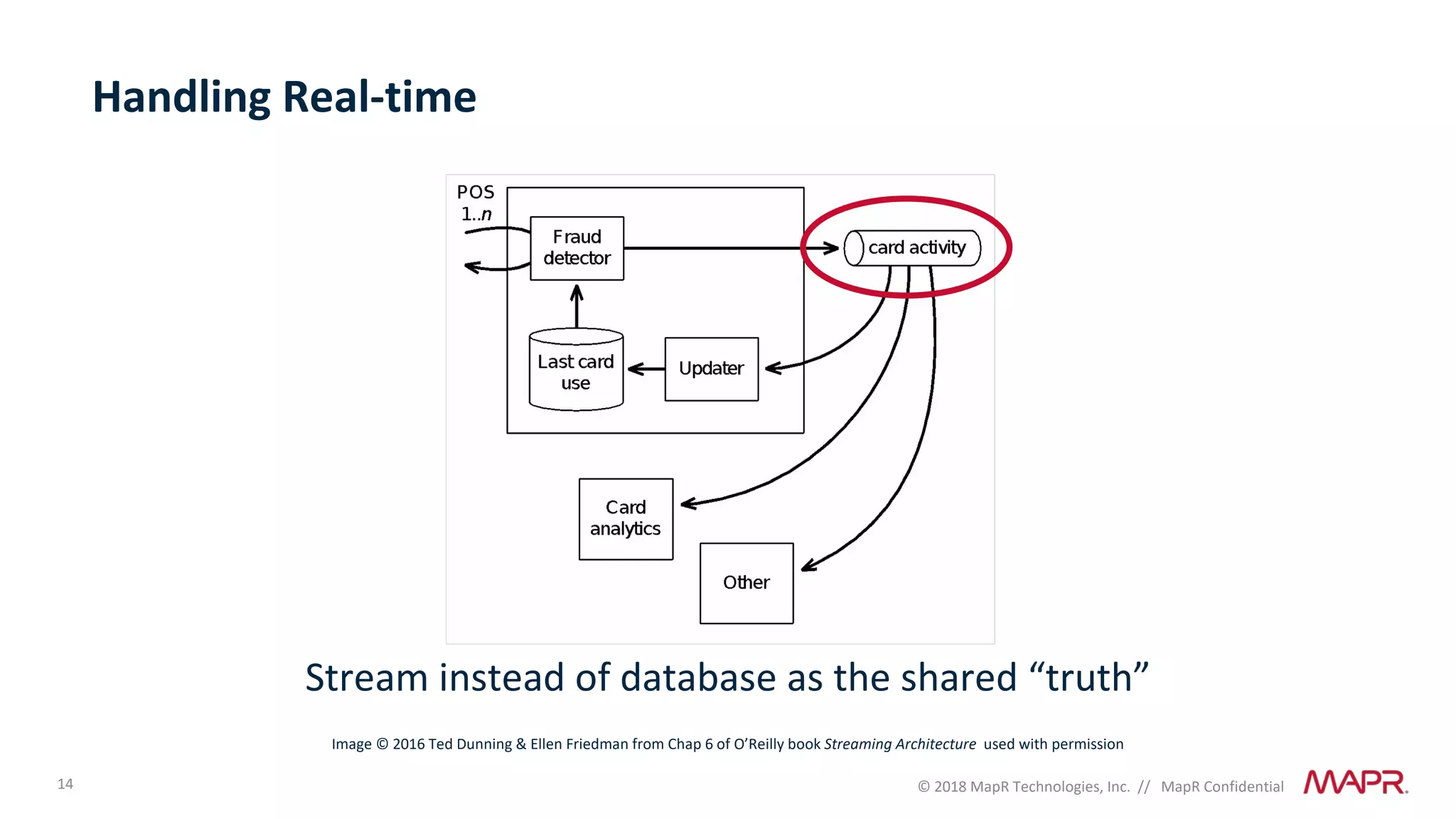
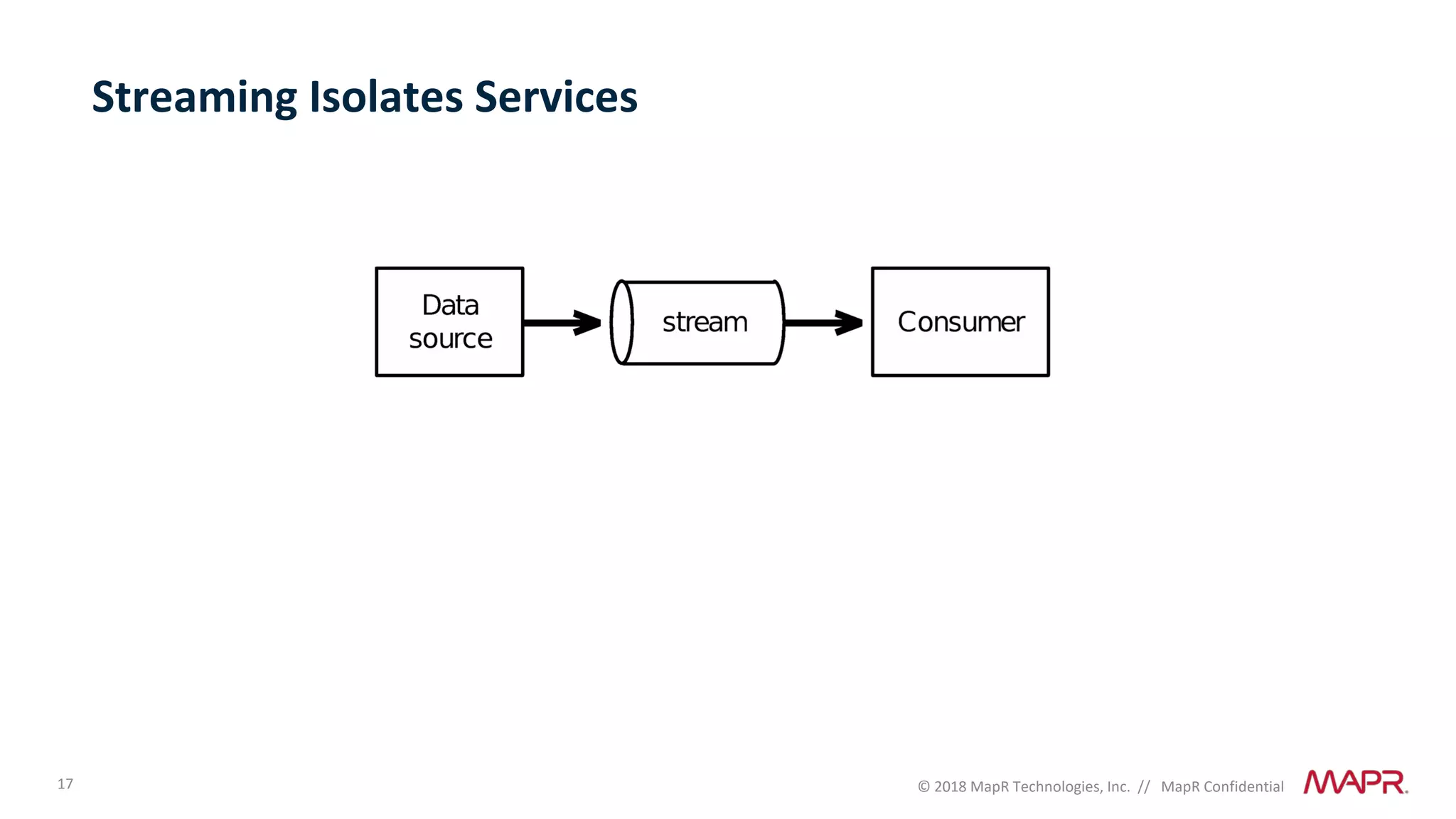
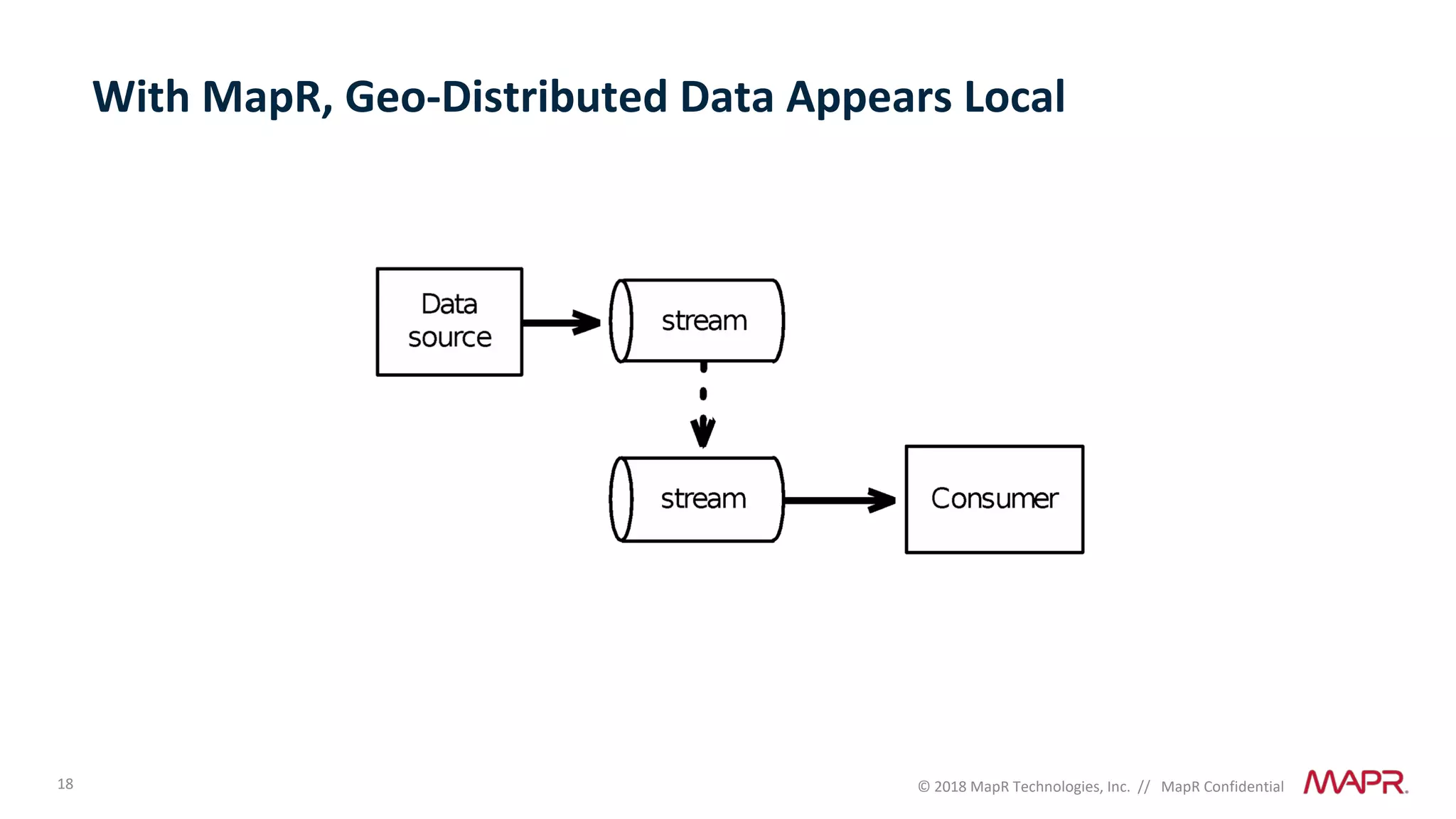
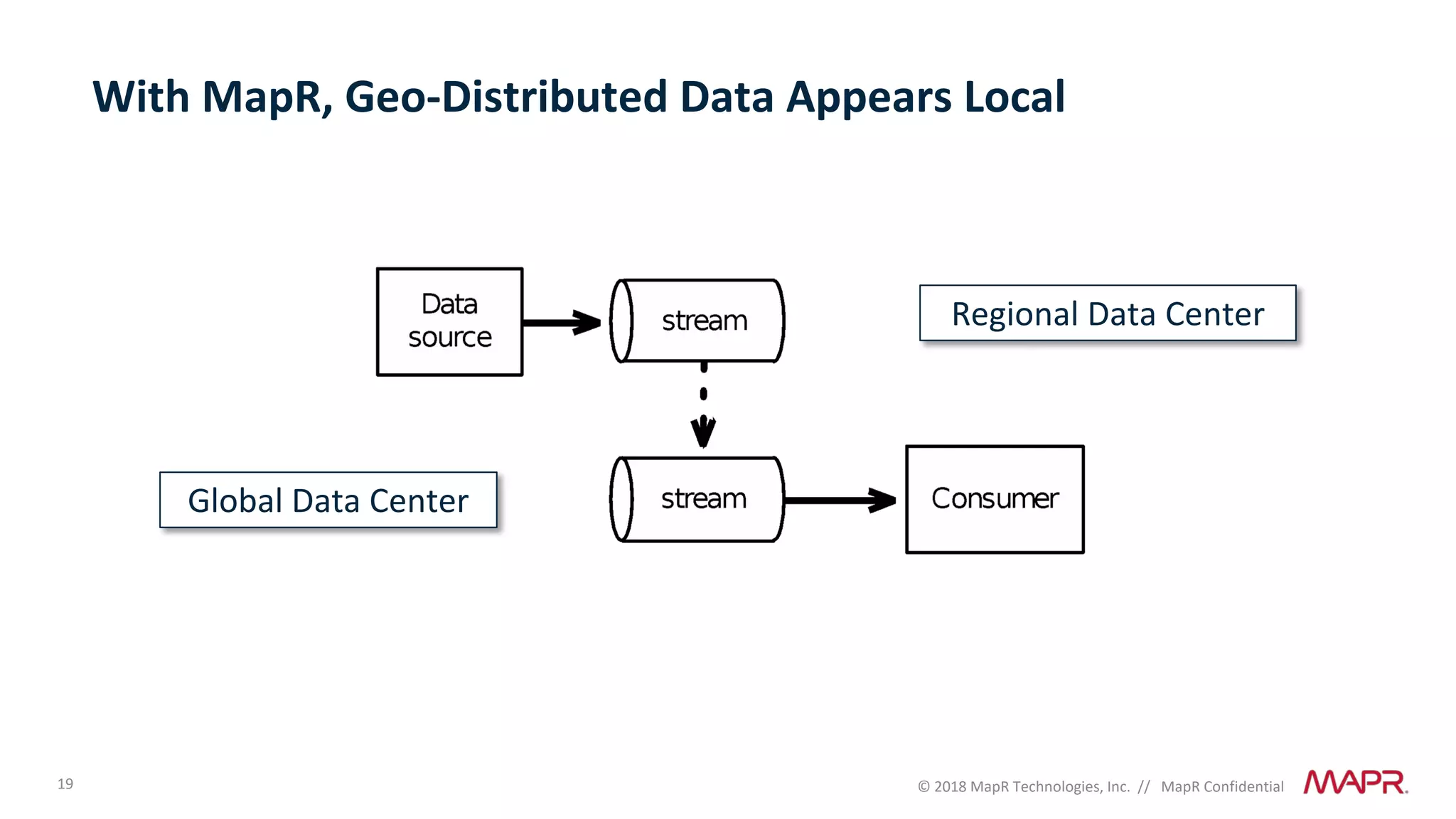
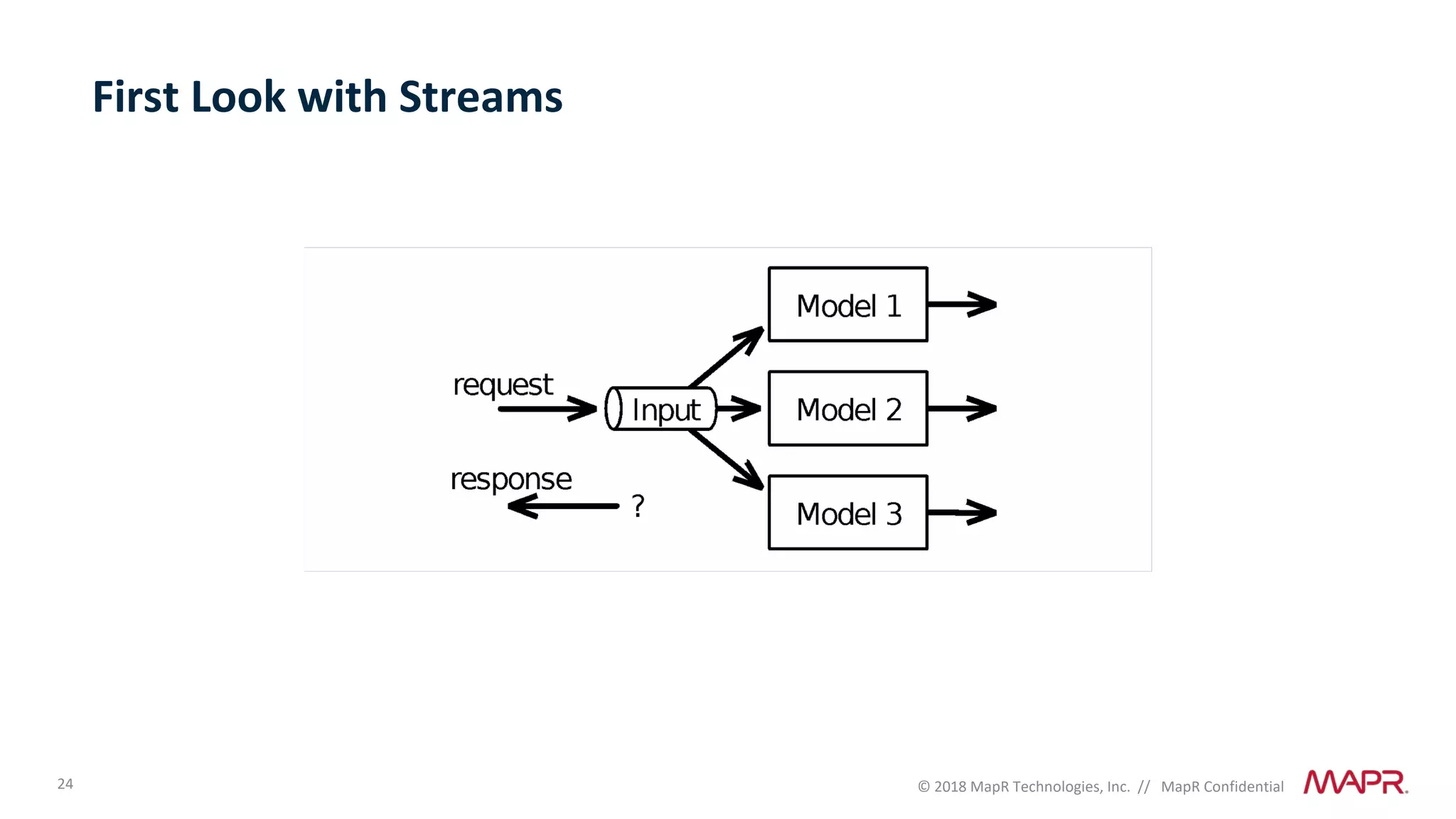
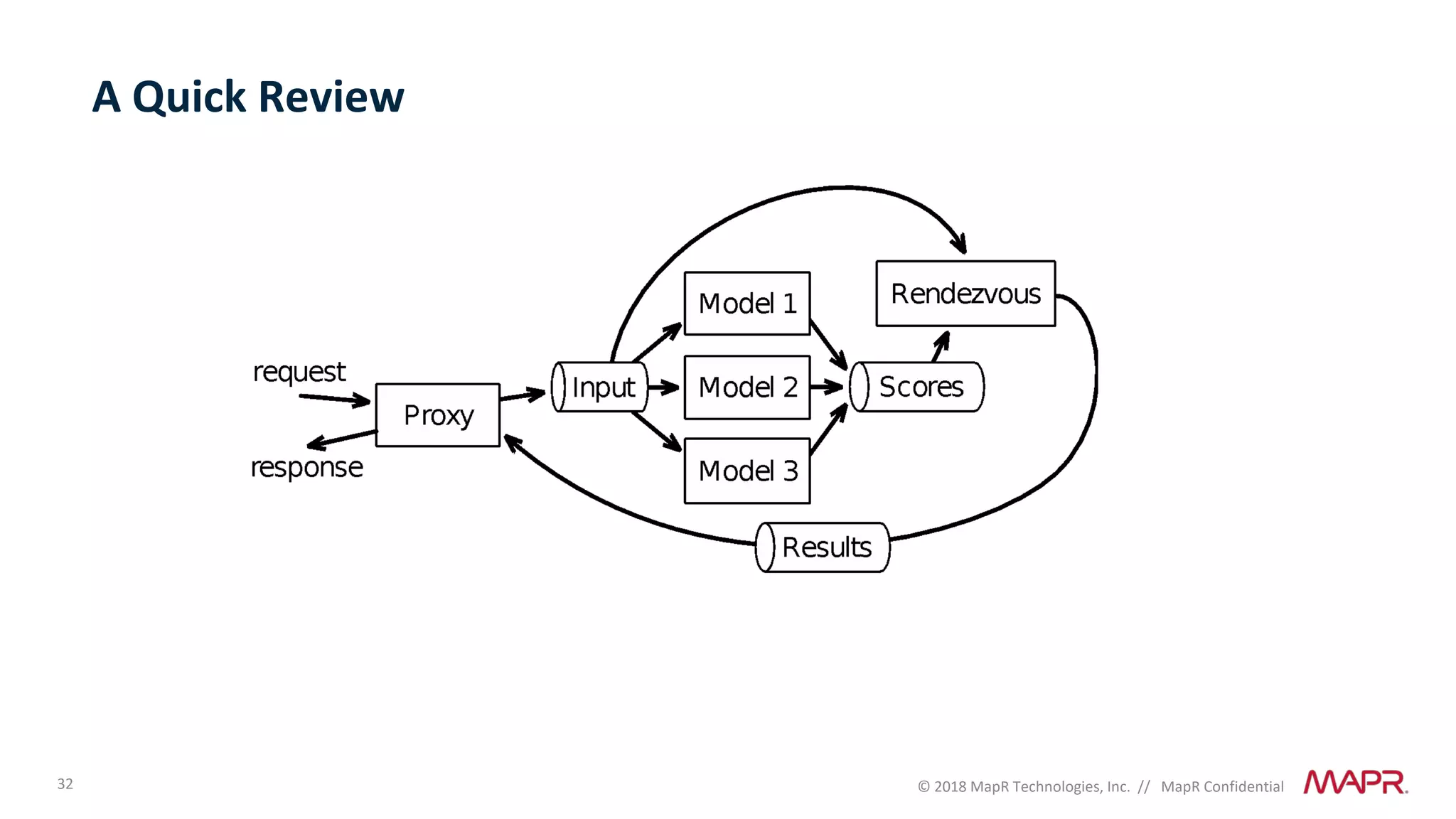
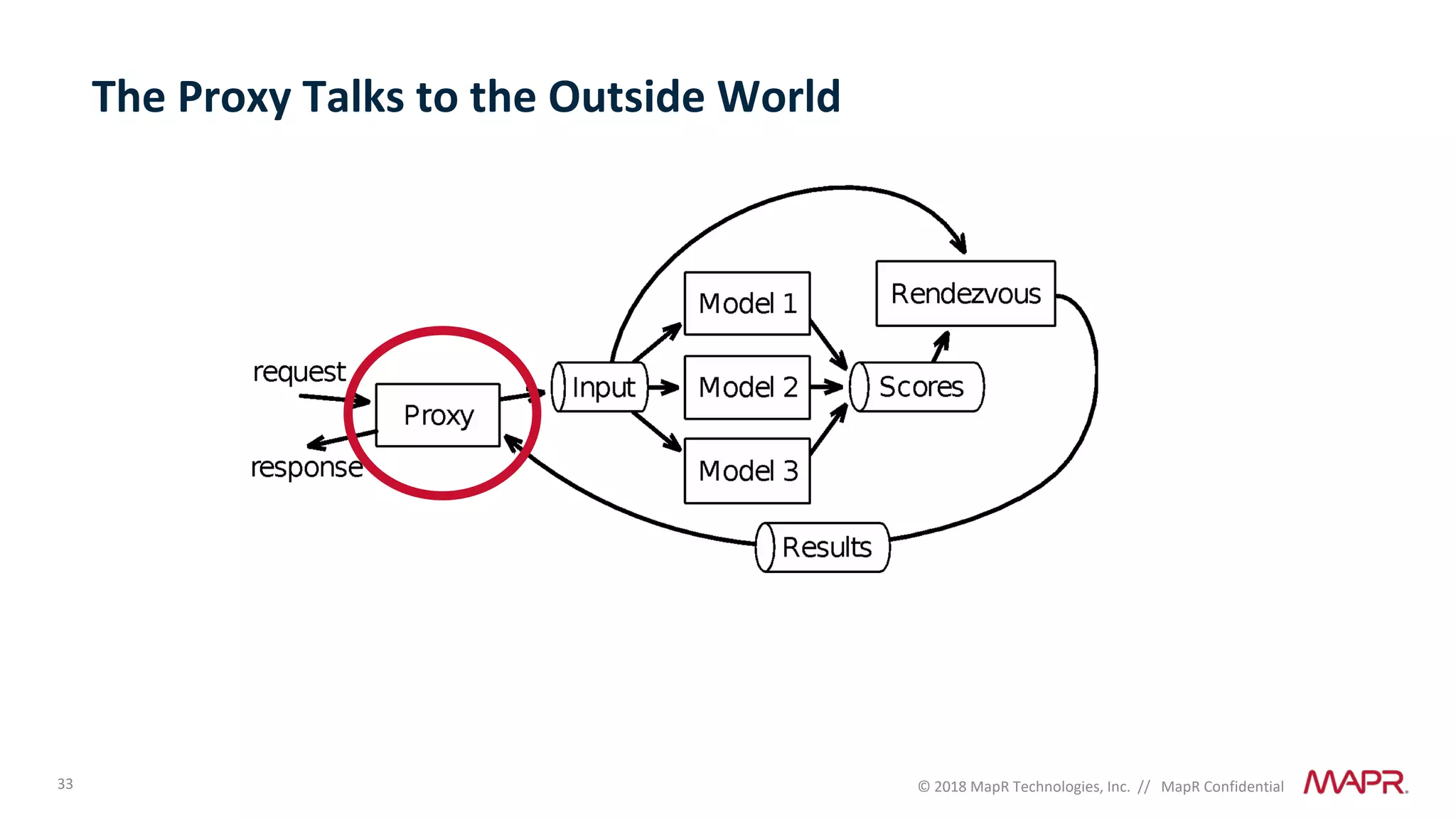
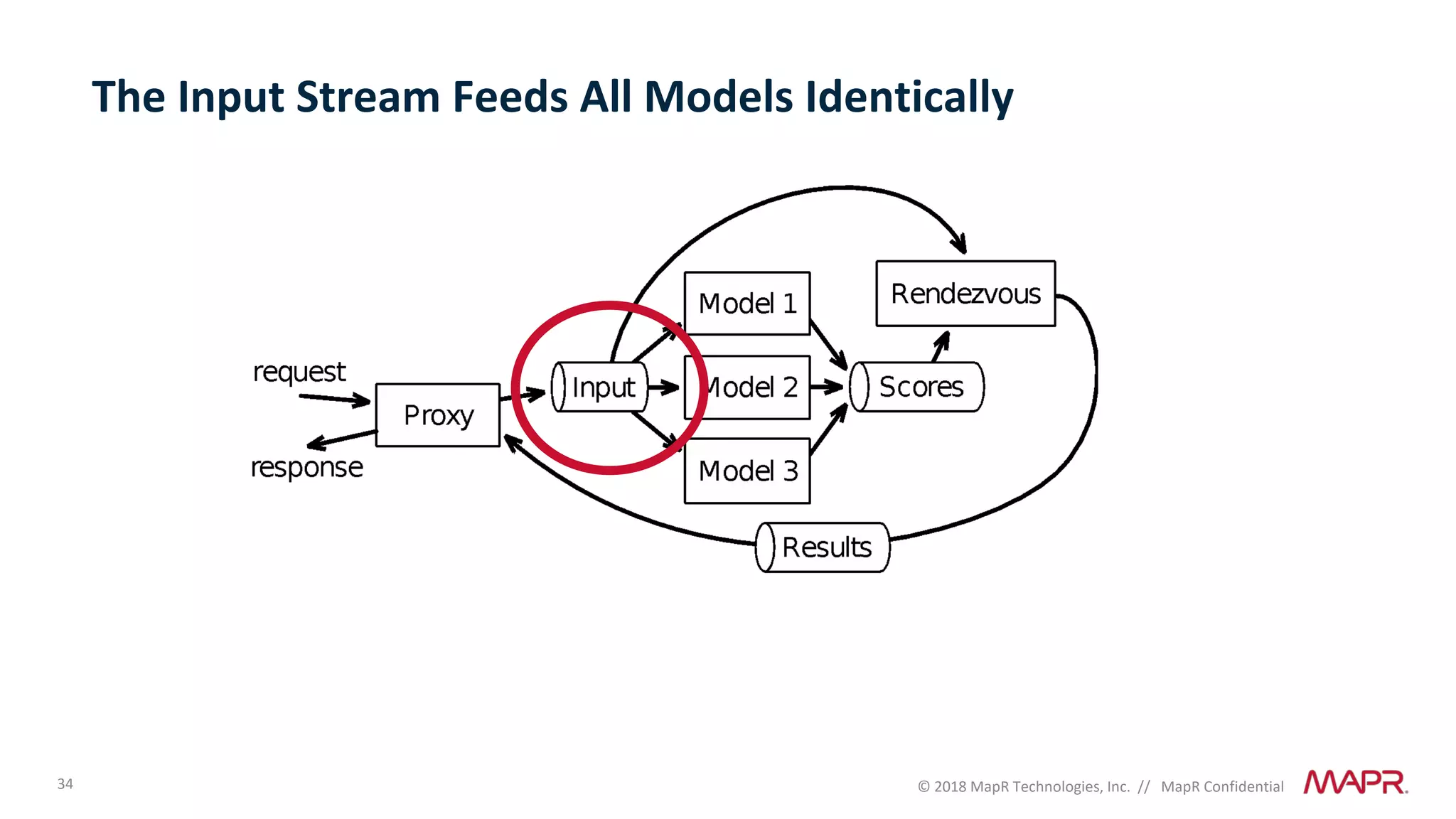
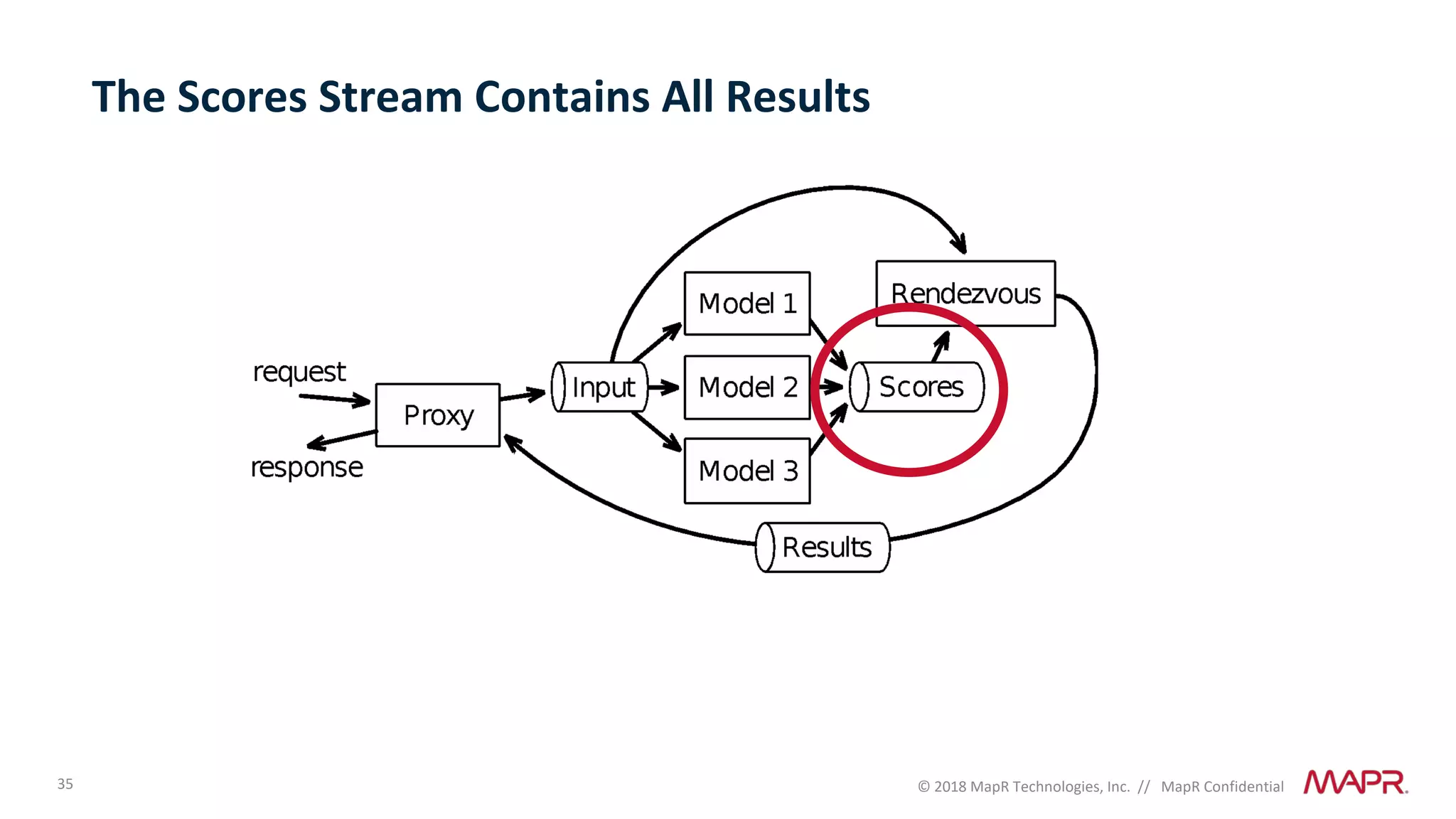
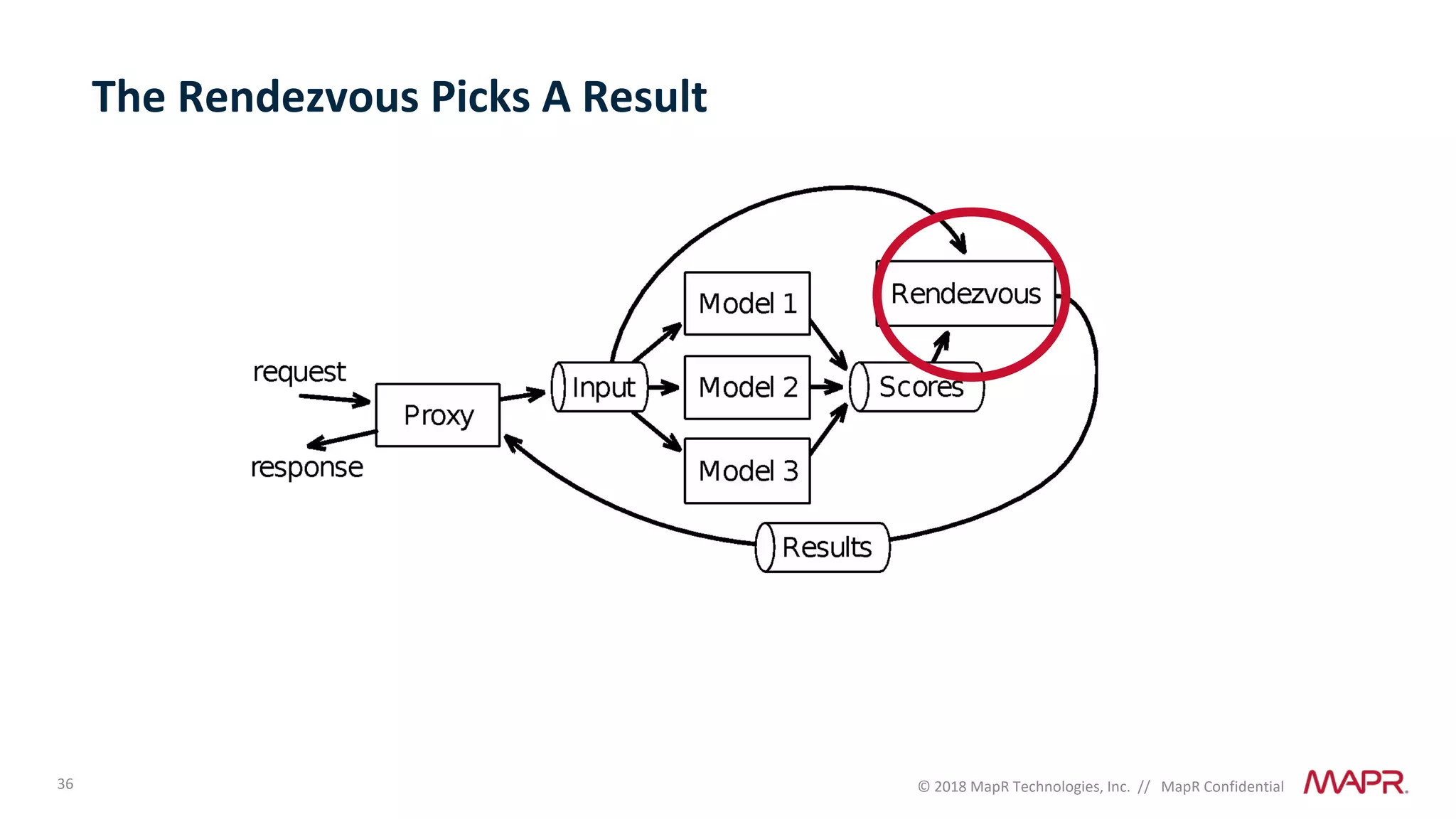
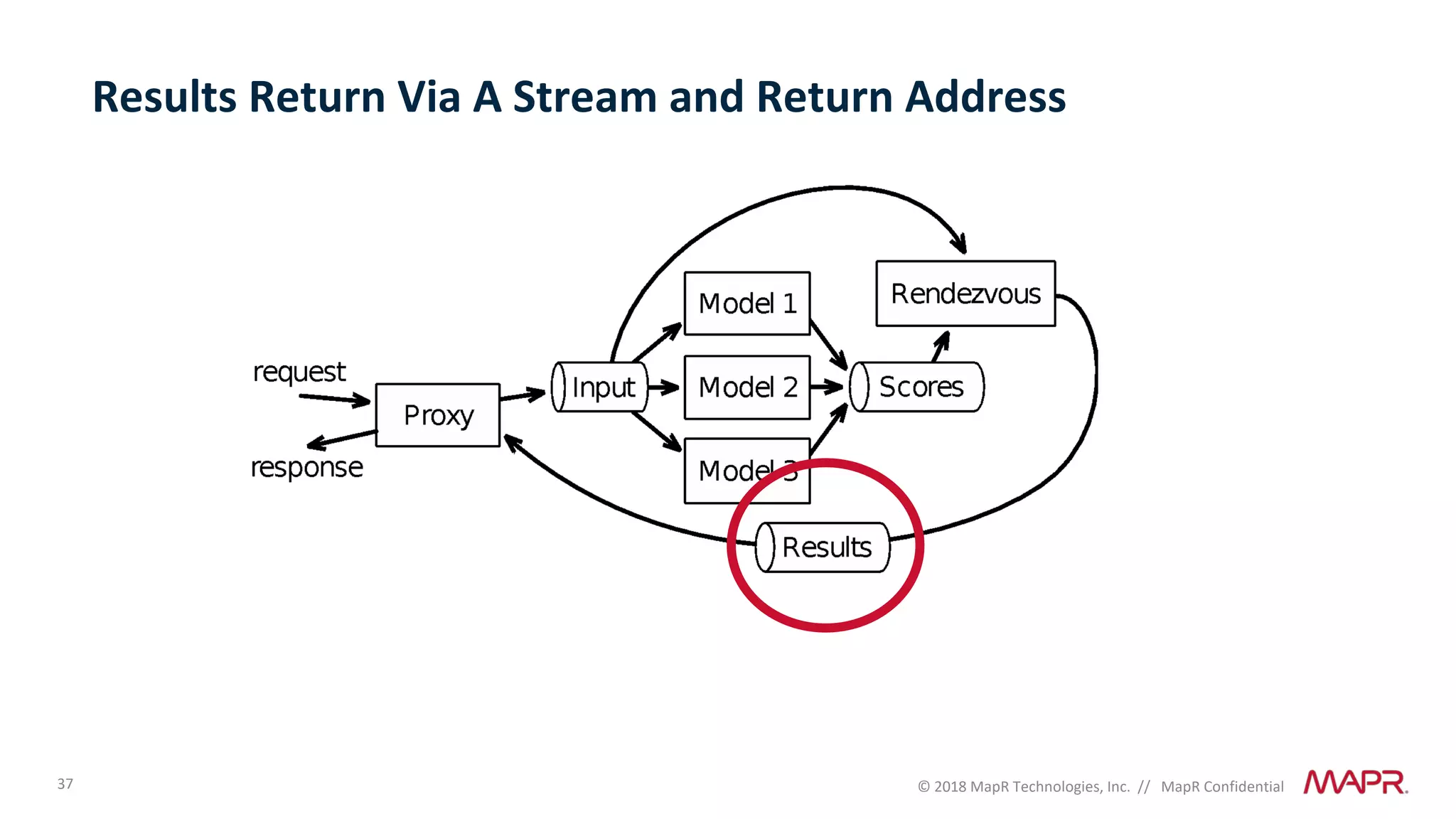
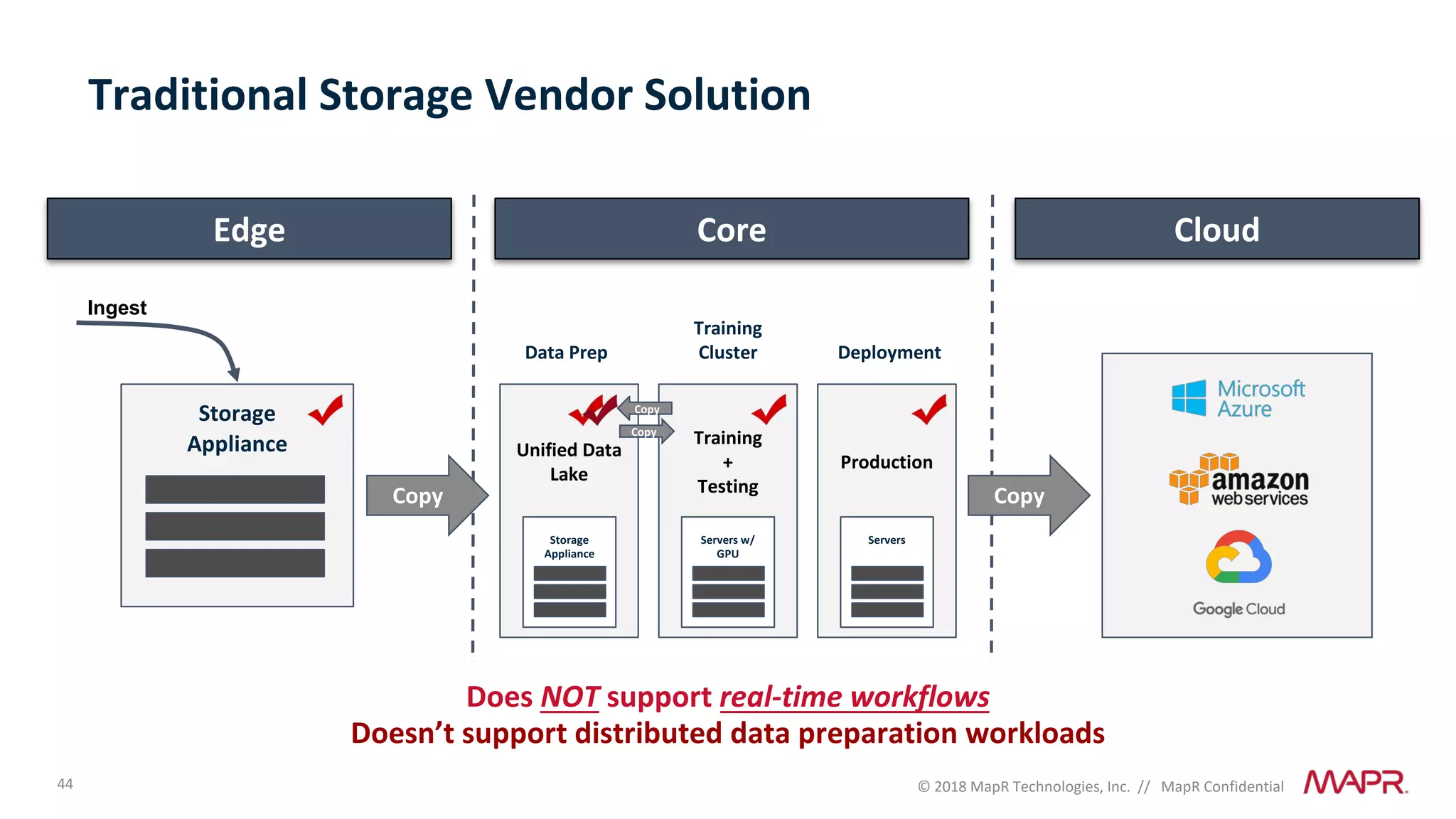
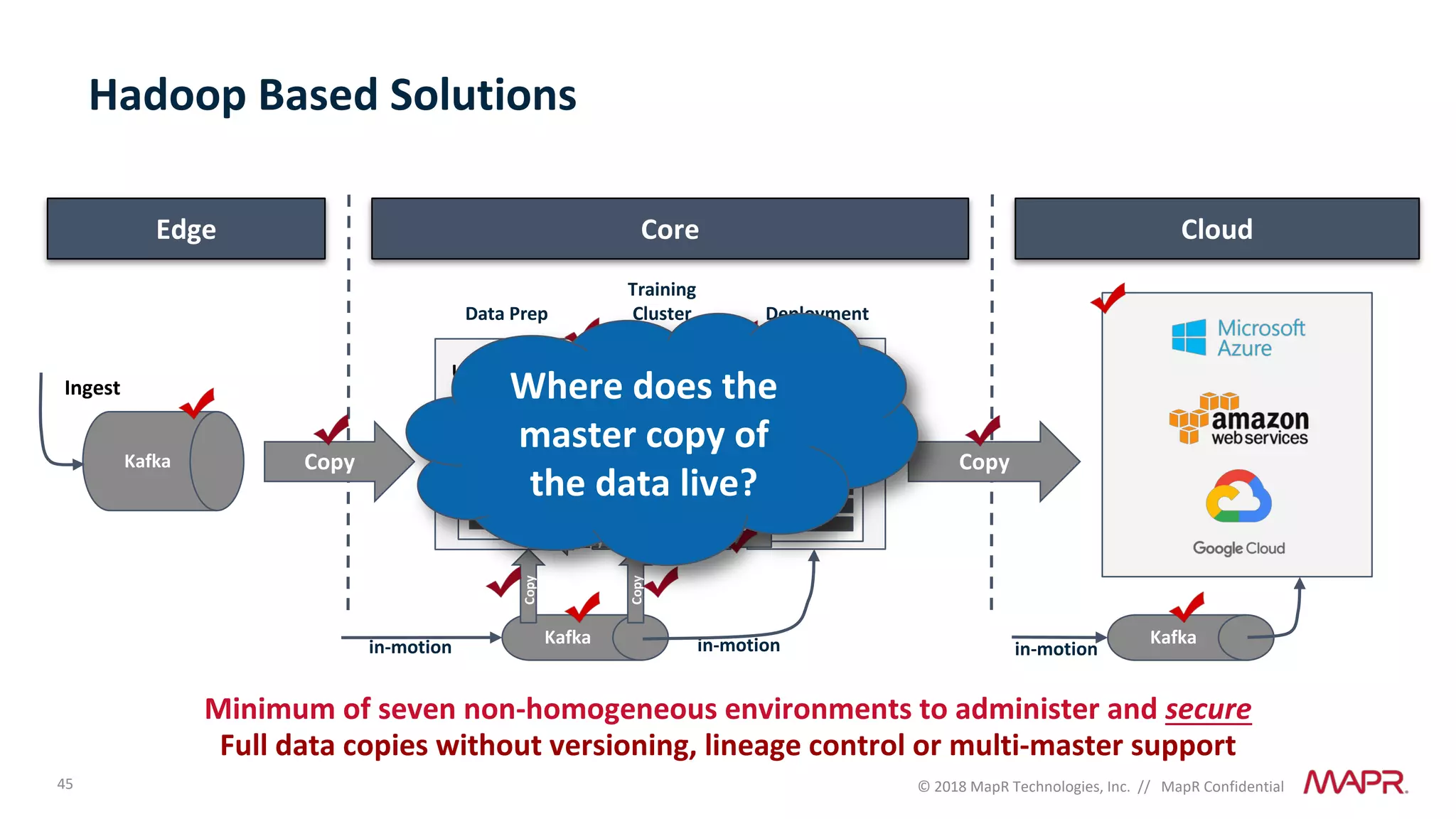
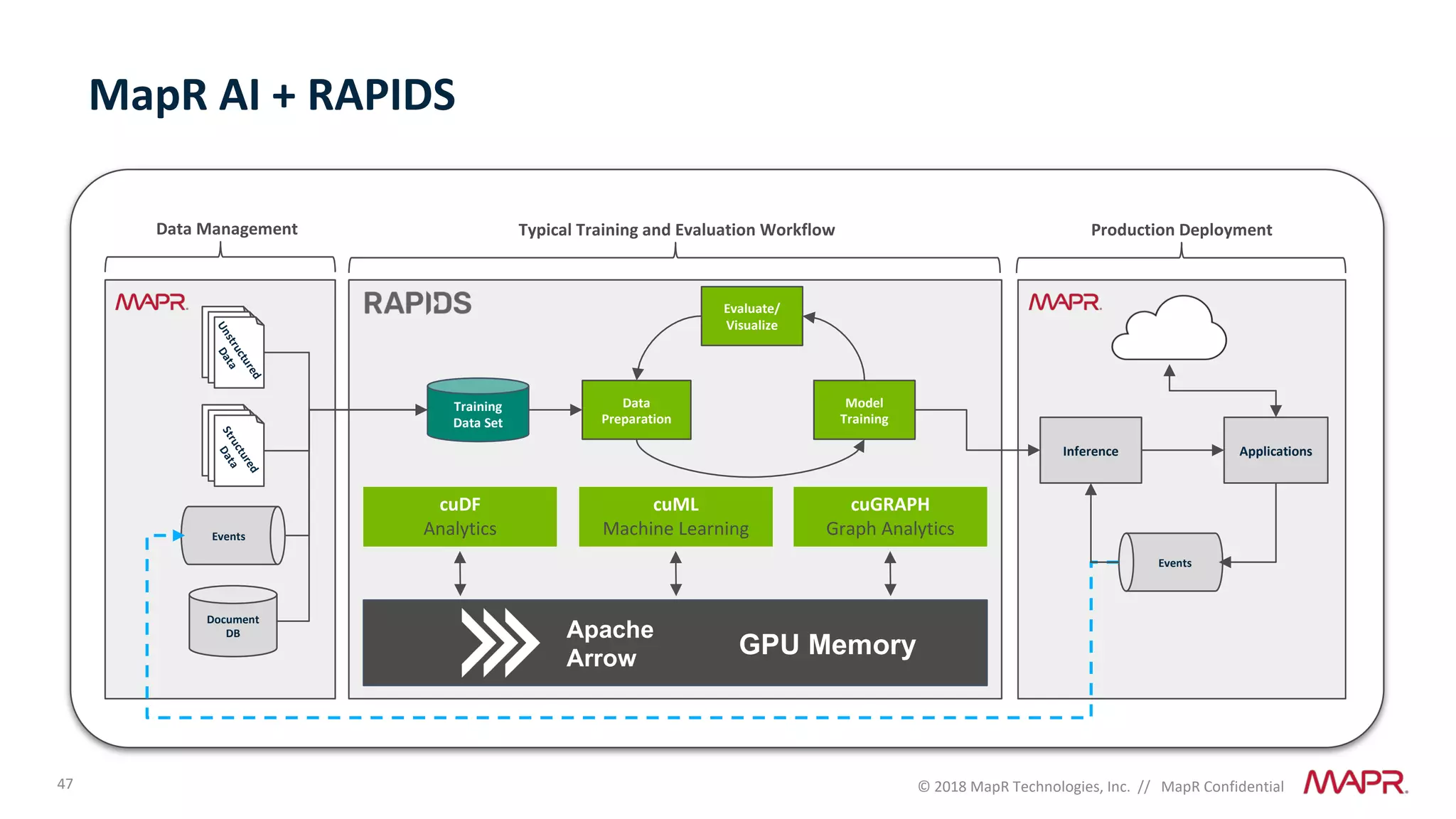
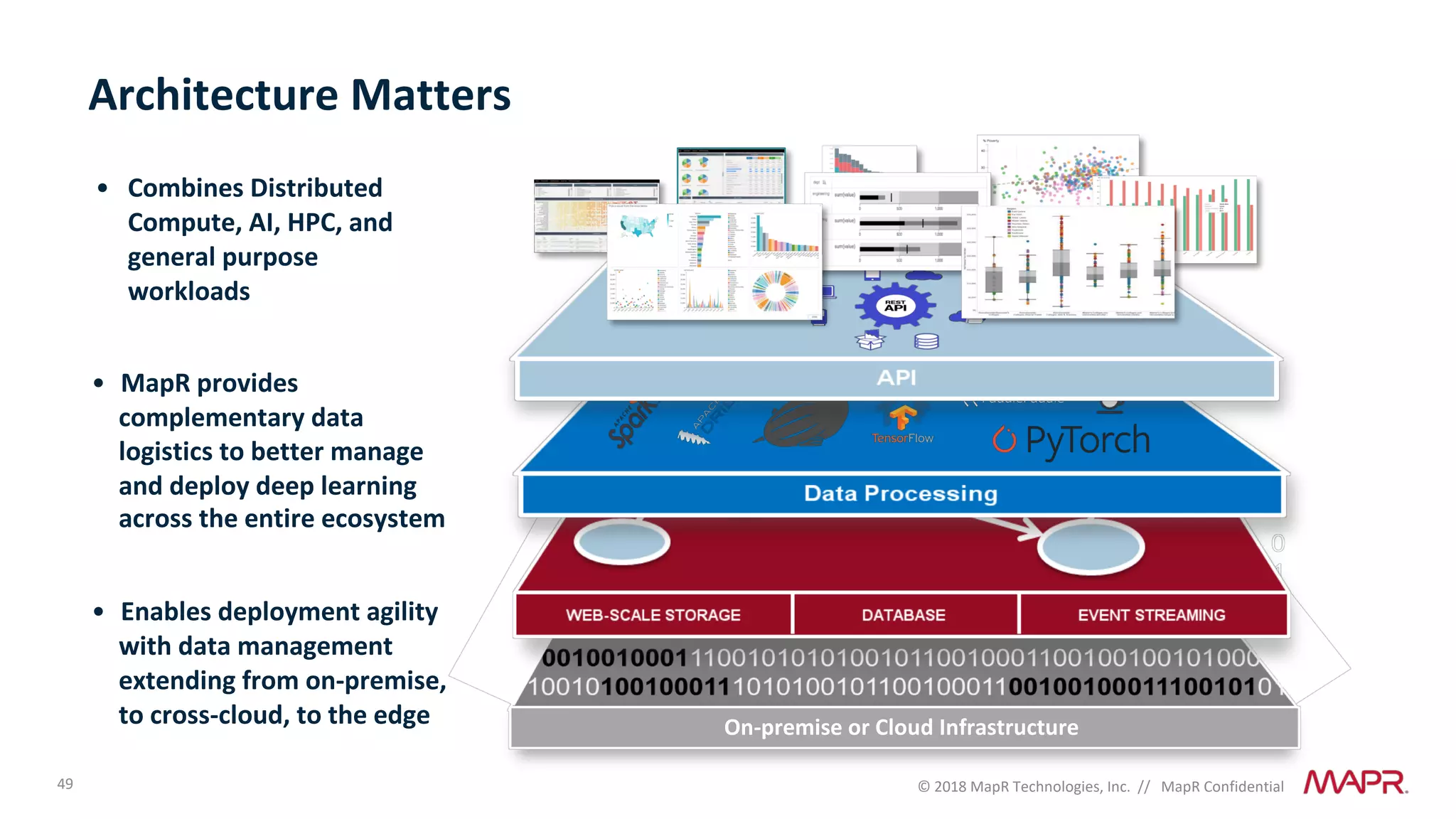
The document discusses several problems that are created by deep learning related to data operations and logistics, including a lack of support for the AI software development lifecycle, handling different workloads beyond just deep learning models, difficulties in putting machine learning models into production, running models in multiple locations, data dependencies being more costly than code dependencies, and changes in conditions over time. It provides recommendations on how to address these problems through approaches like stream-based architectures and containerization.