Download as PDF, PPTX











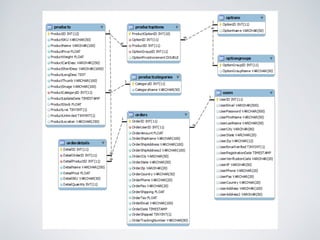




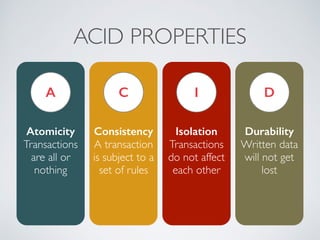




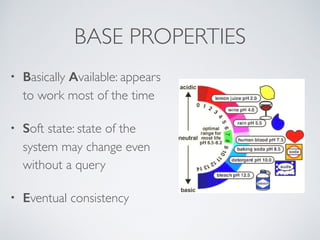


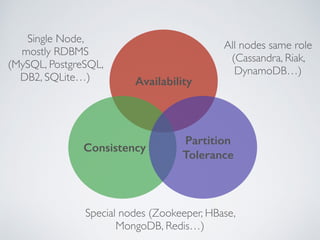
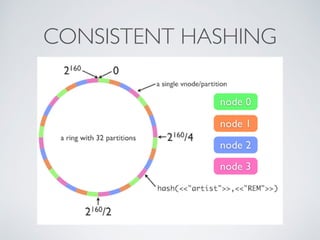

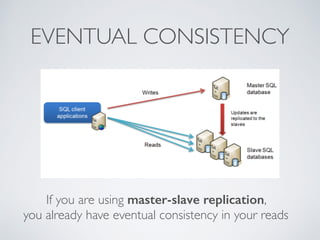




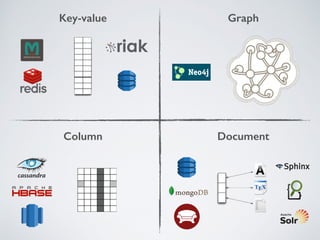







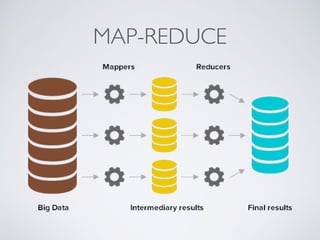







The presentation by Ricard Clau discusses the challenges and solutions related to big data storage and querying, comparing SQL and NoSQL approaches. It highlights the historical context of databases, the limitations of relational databases, and the rise of NoSQL systems due to scalability needs. Clau also addresses how PHP and Symfony can be utilized with various database technologies while emphasizing the importance of understanding trade-offs in data management.




![[Rakuten TechConf2014] [C-2] Big Data for eBooks and eReaders](https://cdn.slidesharecdn.com/ss_thumbnails/c2koborit20141025-141105040826-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)









































































