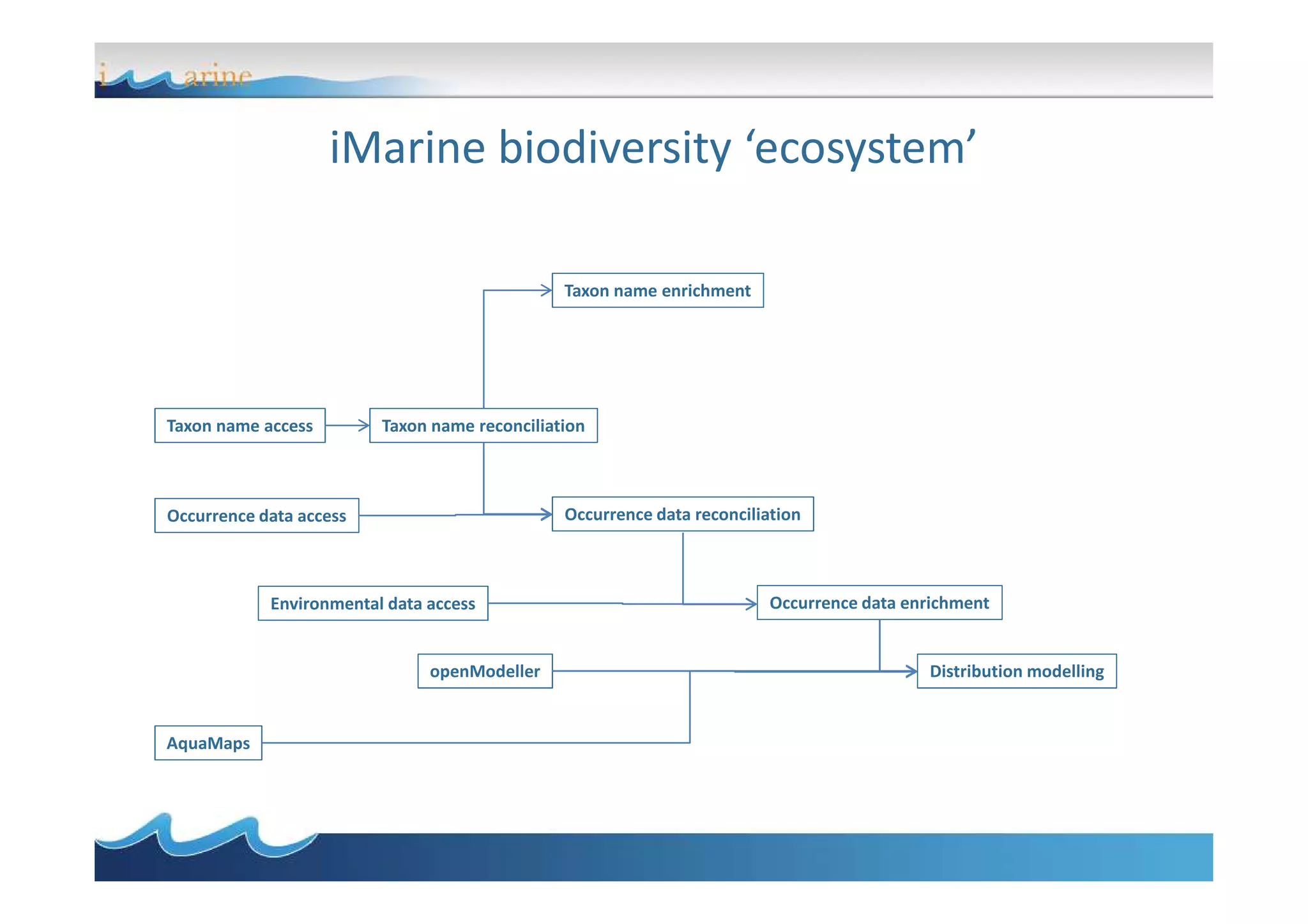
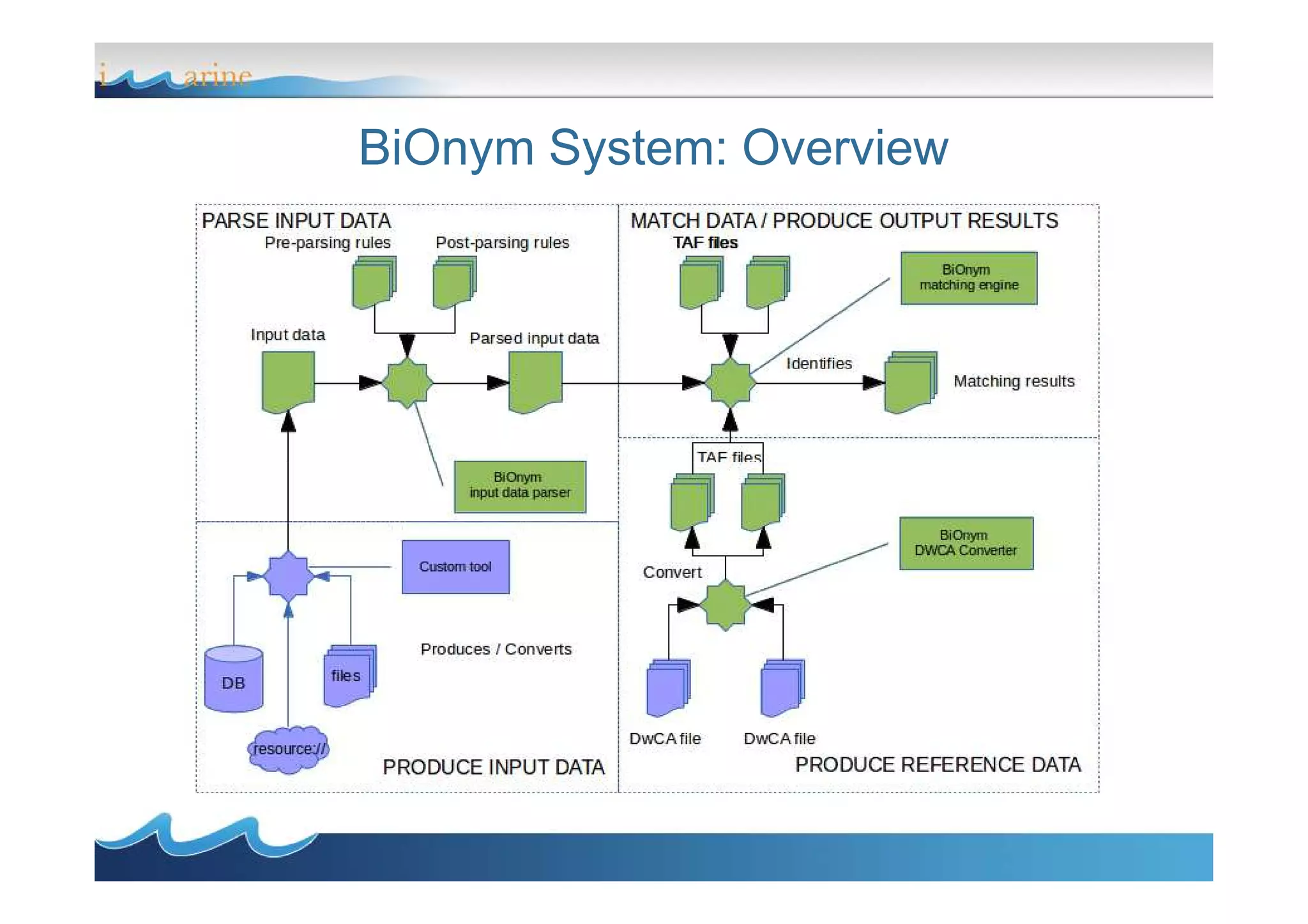
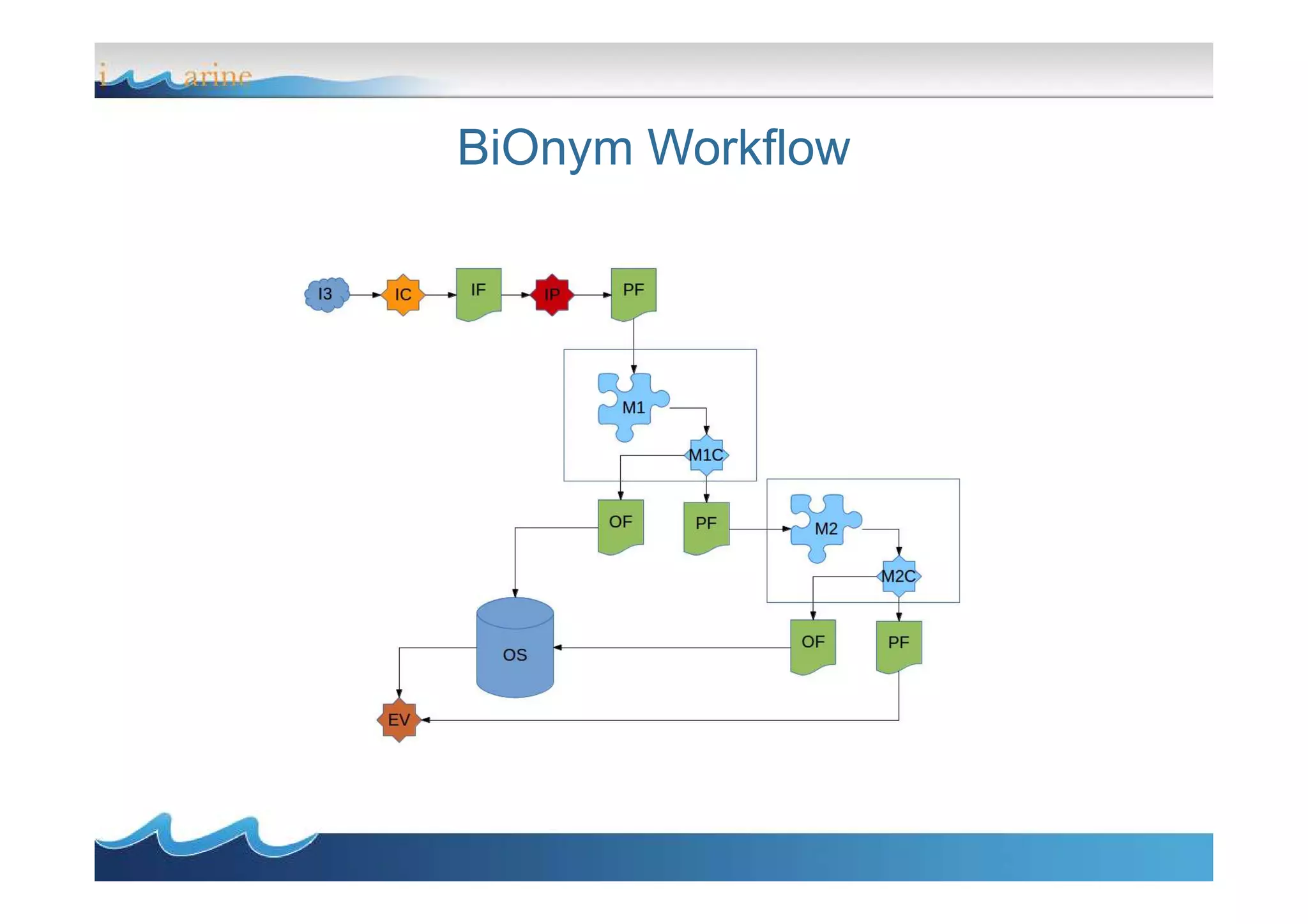
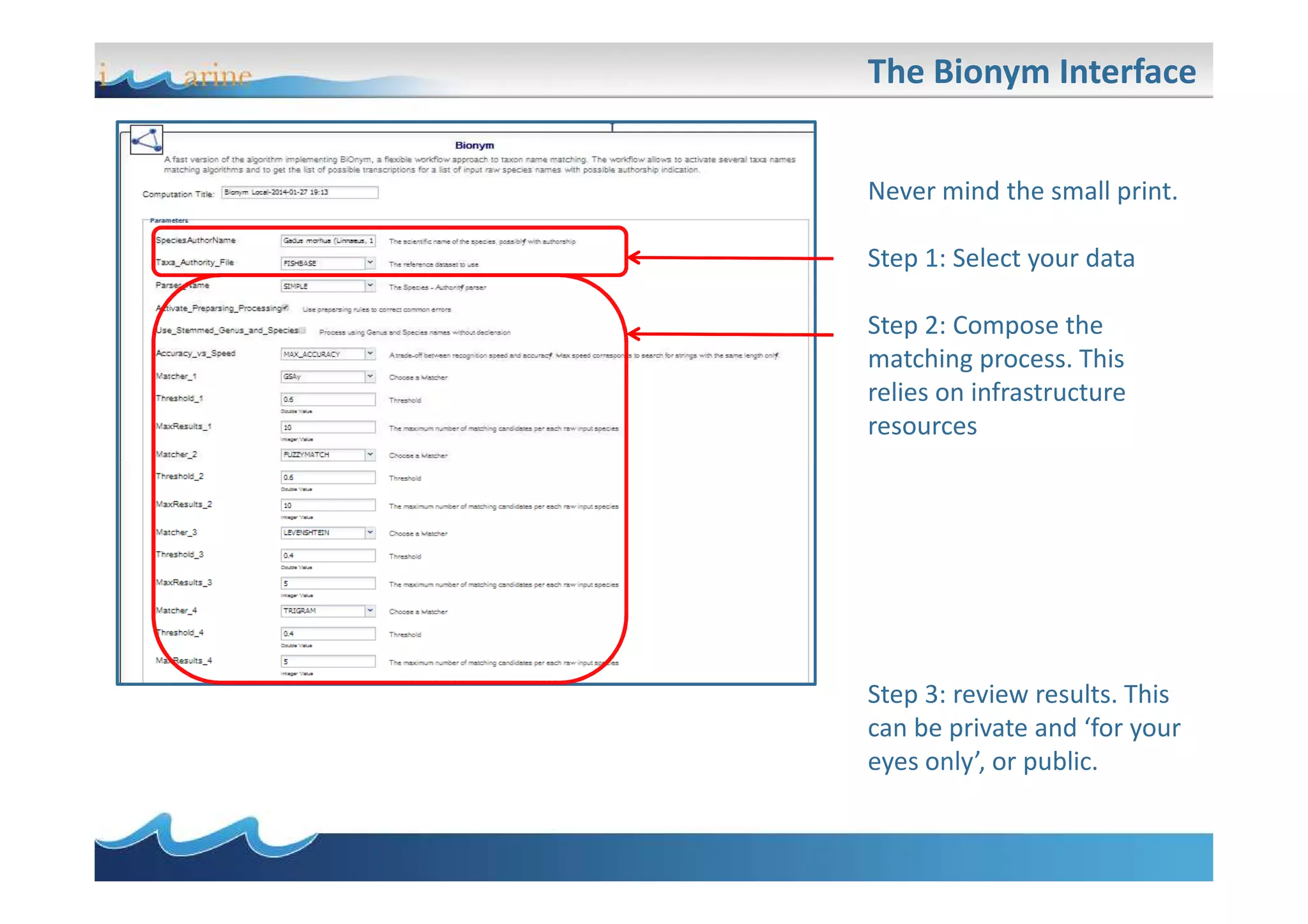
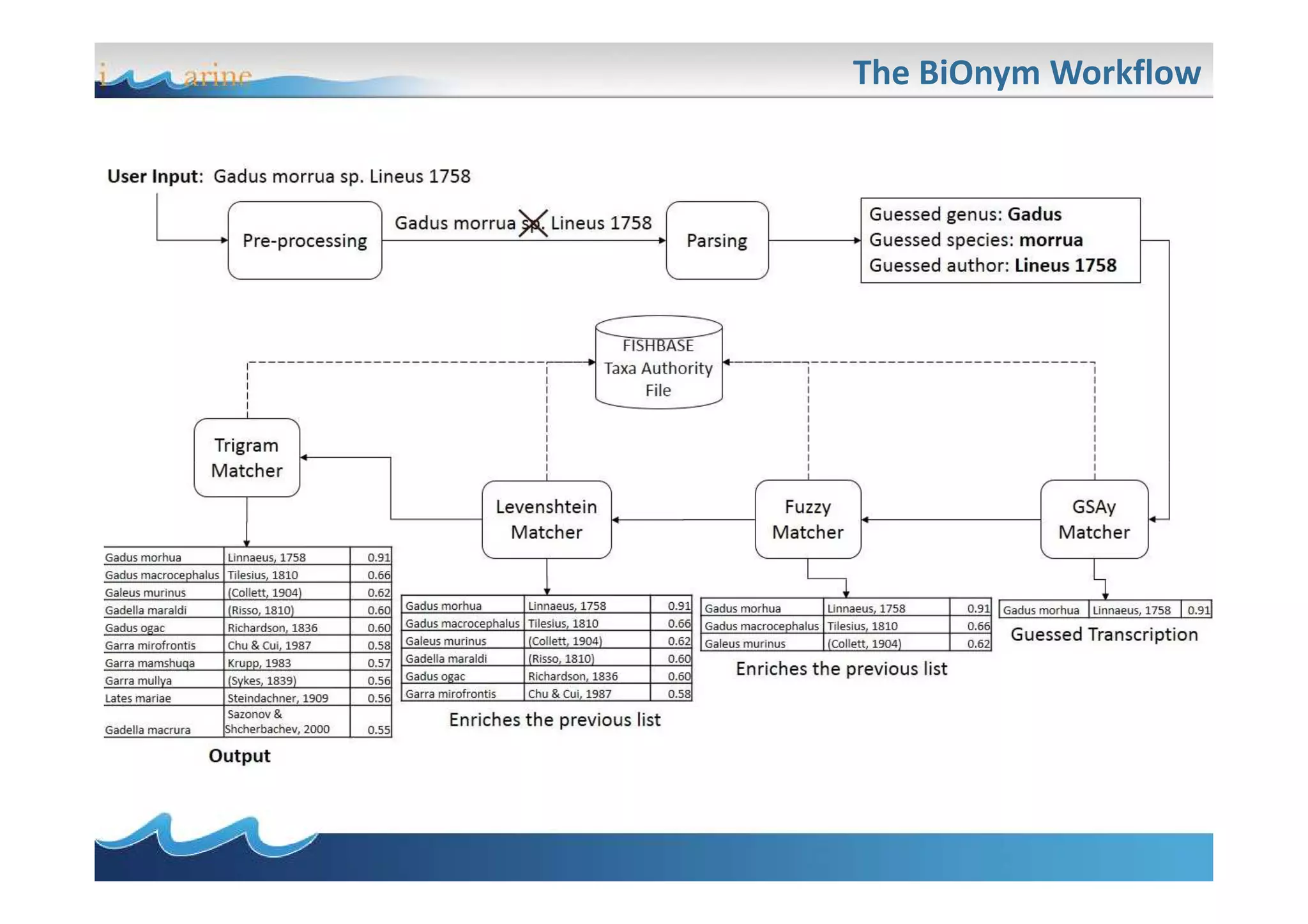
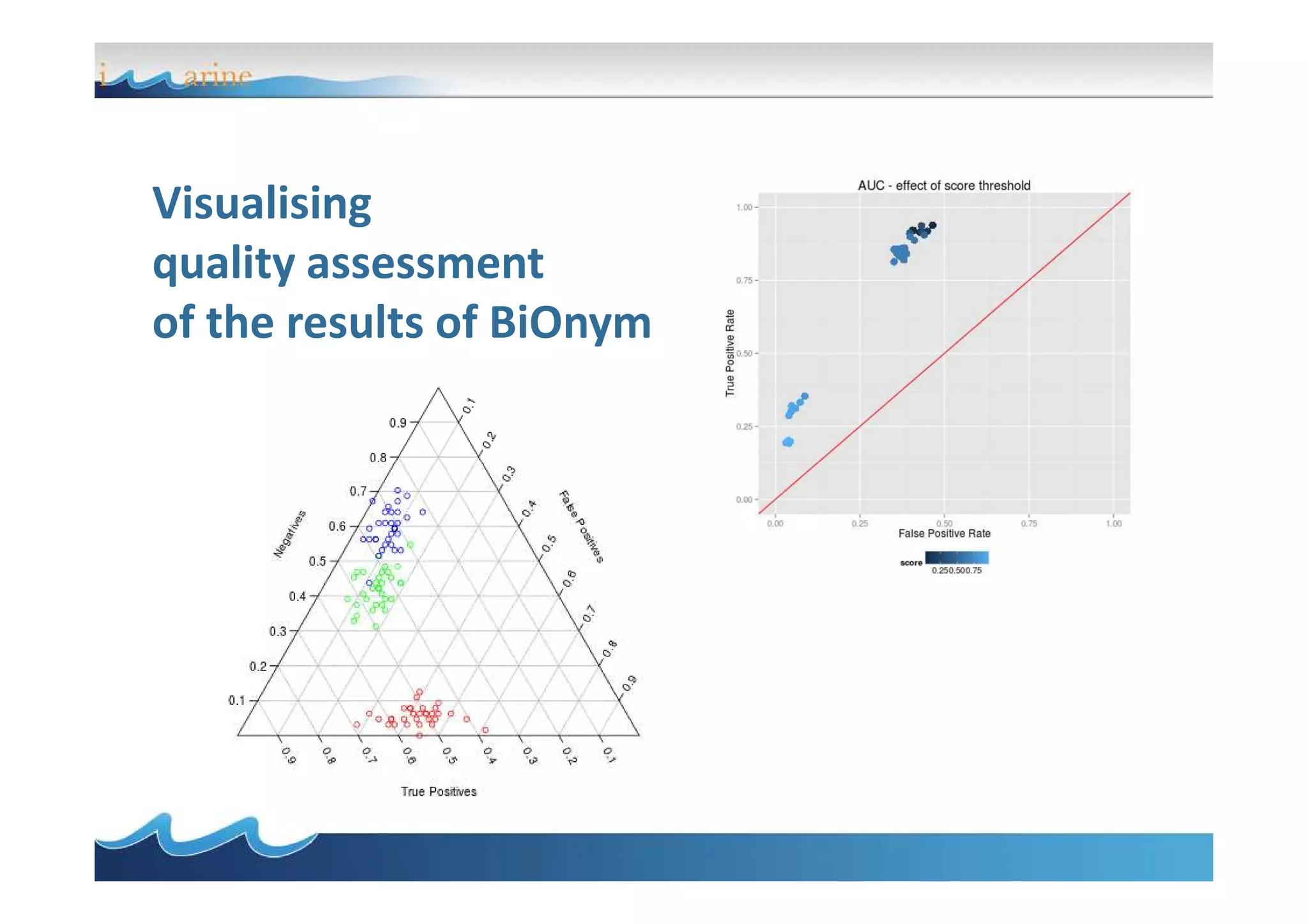
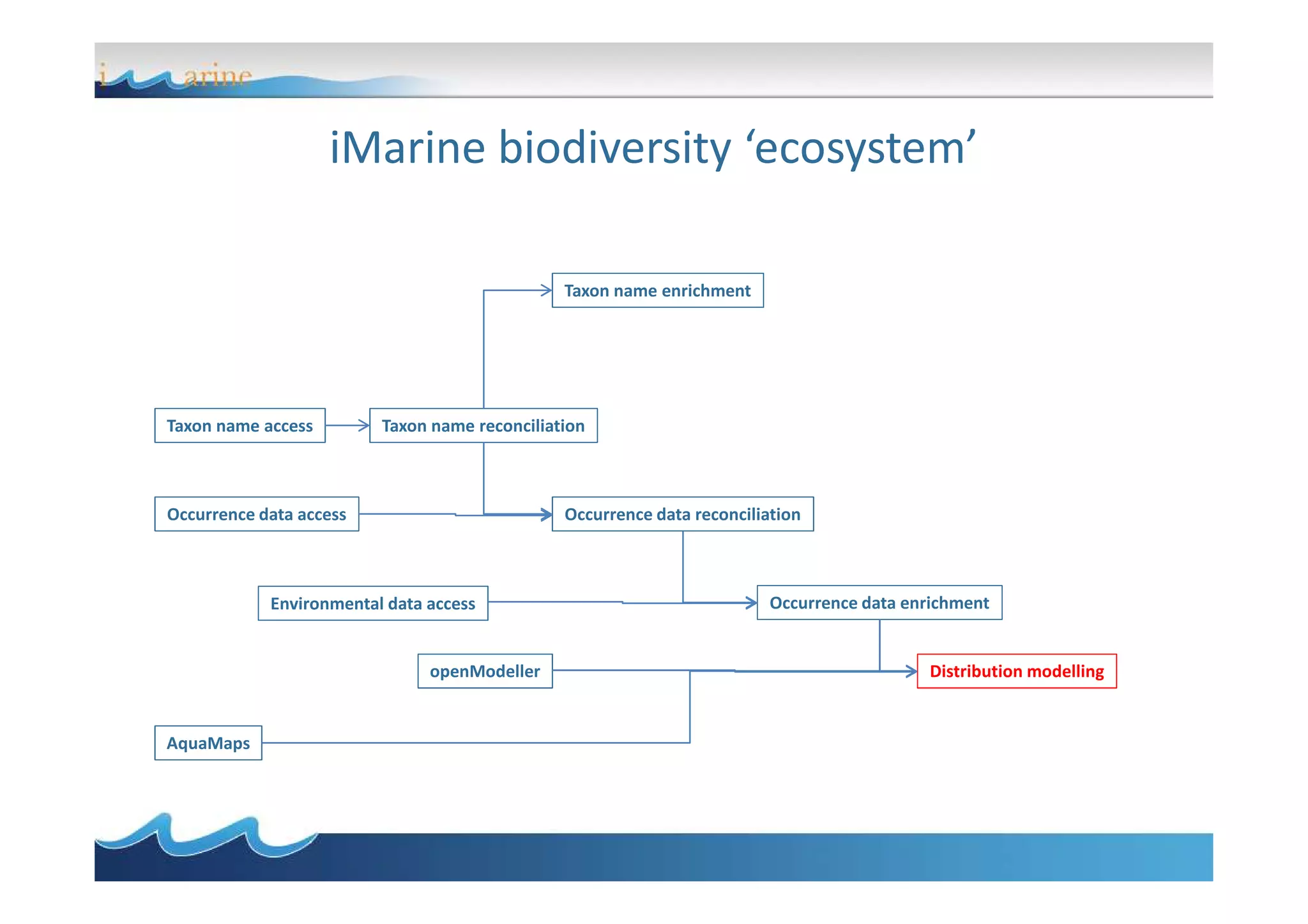
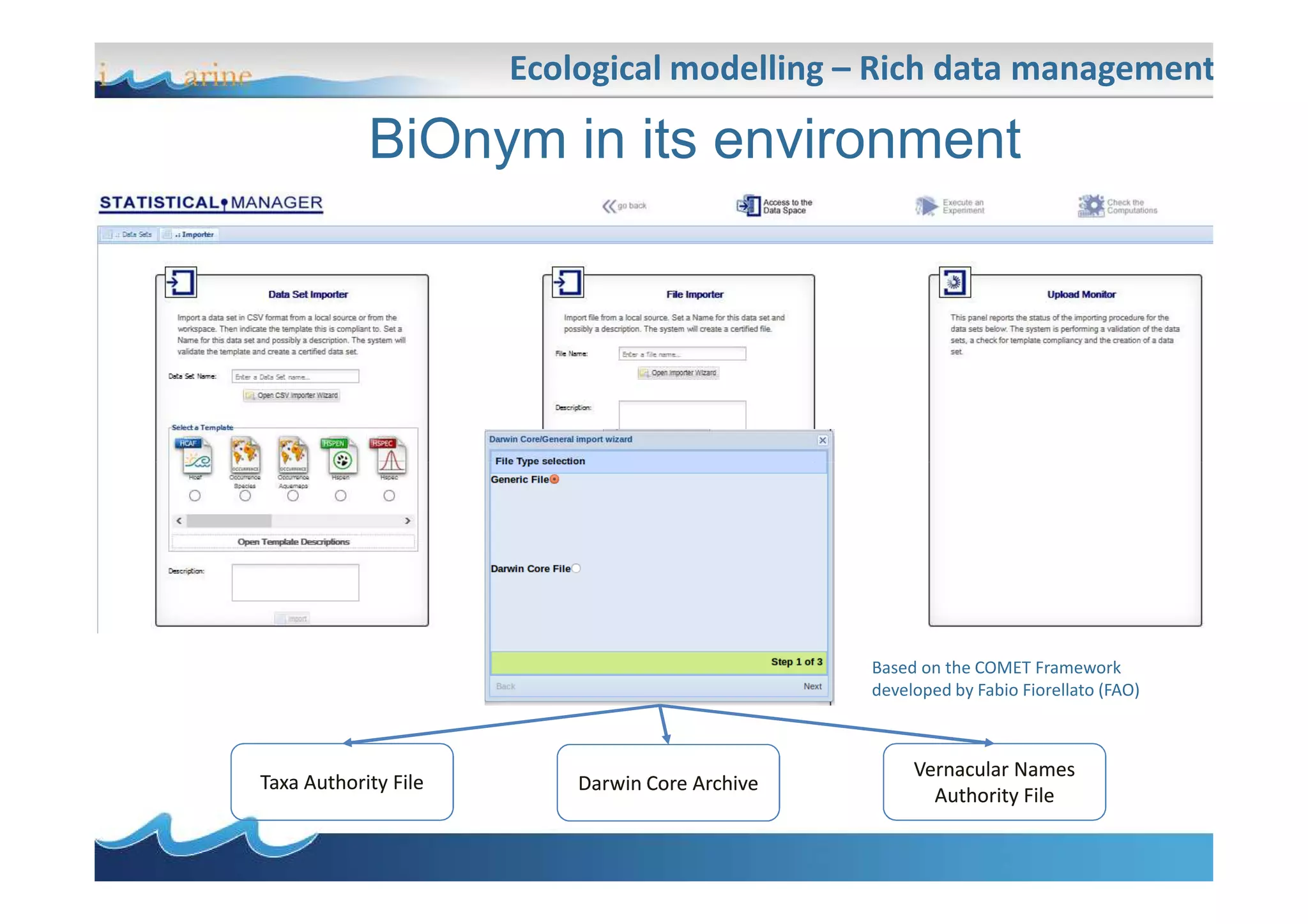
BiOnym is a concept-mapping workflow for taxon name reconciliation that addresses issues in integrating and matching large biodiversity databases. It provides a flexible modular architecture to customize the matching process and integrate third-party components. BiOnym leverages existing open-source tools and uses standard formats to enable interoperability. The workflow includes steps for data preparation, multiple chained matchers, and review of matching results.





































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














