













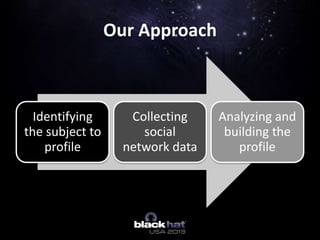






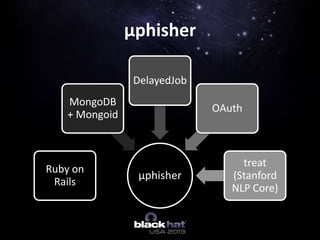







The document discusses using online activity as digital fingerprints to improve spear phishing techniques, with a focus on using social network data and natural language processing. It introduces 'μphisher,' an open-source tool developed to collect and analyze social media data to profile potential targets for phishing. The document outlines the methodology, challenges, and future improvements for the tool and its application in cybersecurity.

















![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)





























