無限回繰り返しゲーム
成分ゲーム
: プレイヤーの集合
: プレイヤーの行動の集合
: プレイヤー の利得関数. として,
成分ゲームを 回繰り返すゲームを考える.
回目において, 各プレイヤーは 回目までに選ばれた行動をすべて知った上で行動を選択する.
繰り返しゲームにおける戦略
として, とし, とする. ここで, を 回目までの履歴という.
プレイヤー の 回目の行動は, 履歴 をもとに決定される, すなわち で与えられる
これより繰り返しゲームにおけるプレイヤー の純粋戦略は で与えられる
プレイヤー の純粋戦略の集合を とし, プレイヤー全体の戦略の組の集合を で表す
G = (N, {Si
}i∈N, {fi
}i∈N)
N
Si
i
fi
i S = S1
× ⋯ × Sn
fi
: S → ℜ
∞
t t − 1
S = S1
× ⋯ × Sn
St−1 =
t−1
S × ⋯ × S S0 = {∅} ht−1 = (s1, ⋯, st−1) ∈ St−1 t − 1
i t ht−1 xi
t : St−1 → Si
i xi
= (xi
t)∞
t=1
i X∞i
X∞
= X∞1
× ⋯ × X∞n
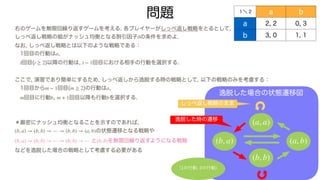
右のゲームを無限回繰り返すゲームを考える. 各プレイヤーがしっぺ返し戦略をとるとして,
しっぺ返し戦略の組がナッシュ均衡となる割引因子 の条件を求めよ.
なお,しっぺ返し戦略とは以下のような戦略である:
1回目の行動は ,
回目( )以降の行動は, 回目における相手の行動を選択する.
ここで, 演習であり簡単にするため, しっぺ返しから逸脱する時の戦略として, 以下の戦略のみを考慮する:
1回目から 回目( )の行動は ,
回目に行動 , 回目以降も行動 を選択する.
*厳密にナッシュ均衡となることを示すのであれば,
の状態遷移となる戦略や
と を無限回繰り返すようになる戦略
などを逸脱した場合の戦略として考慮する必要がある
δ
a
t t ≥ 2 t − 1
m − 1 m ≥ 2 a
m b m + 1 b
(b, a) → (b, b) → ⋯ → (b, b) → (a, b)
(b, a) → (b, b) → ⋯ → (b, b) → ⋯ (b, b)
問題 1\ 2 a b
a 2, 2 0, 3
b 3, 0 1, 1
(a, a)
(b, a) (a, b)
(b, b)
逸脱した場合の状態遷移図
しっぺ返し戦略のまま
逸脱した時の遷移
(1の行動, 2の行動)





![解答
右のゲームを無限回繰り返すゲームを考える. 各プレイヤーがしっぺ返し戦略をとるとして,
しっぺ返し戦略の組がナッシュ均衡となる割引因子 の条件を求めよ.
なお, しっぺ返し戦略とは以下のような戦略である:
1回目の行動は ,
回目( )以降の行動は, 回目における相手の行動を選択する.
プレイヤー2がしっぺ返し戦略をとるとして, プレイヤー1のしっぺ返し戦略が最適反応になる条件を求める.
しっぺ返し戦略
別の戦略 [1回目から 回目( )の行動は , 回目に行動 , 回目以降も行動 を選択する.]を考えたとき,
回目まで , 回目で , 回目以降 という行動の組になるため,
以下の利得を得る.
δ
a
t t ≥ 2 t − 1
f∞1
δ (x) = (1 − δ)(2 + 2δ1
+ ⋯ + 2δm−2
+ 2δm−1
+ 2δm
+ 2δm+1
+ ⋯) = (1 − δ)(2 + 2δ1
+ ⋯ + 2δm−2
) + 2δm−1
(1 − δ)(1 + δ + δ2
+ ⋯)
= (1 − δ)(2 + 2δ1
+ ⋯ + 2δm−2
) + 2δm−1
(1 − δ)
1
1 − δ
= (1 − δ)(2 + 2δ1
+ ⋯ + 2δm−2
) + 2δm−1
m − 1 m ≥ 2 a m b m + 1 b
m − 1 (a, a) m (b, a) m + 1 (b, b) → (b, b) → (b, b) → ⋯
f∞1
δ (x′

) = (1 − δ){2 + 2δ1
+ ⋯ + 2δm−2
+ 3δm−1
+ 1 ⋅ δm
+ 1δm+1
+ 1 ⋅ δm+2
+ 1δm+3
+ 1 ⋅ δm+4
+ ⋯}
= (1 − δ)(2 + 2δ1
+ ⋯ + 2δm−2
) + 3δm−1
(1 − δ) + (1 − δ)δm
(1 + δ + δ2
+ ⋯)
= (1 − δ)(2 + 2δ1
+ ⋯ + 2δm−2
) + 3δm−1
(1 − δ) + (1 − δ)
δm
1 − δ
= (1 − δ)(2 + 2δ1
+ ⋯ + 2δm−2
) + 3δm−1
(1 − δ) + δm
1\ 2 a b
a 2, 2 0, 3
b 3, 0 1, 1](https://image.slidesharecdn.com/basic118-241222123943-d801aa81/85/BASIC-117-2-6-320.jpg)
![解答
しっぺ返し戦略
別の戦略 [1回目から 回目( )の行動は , 回目に行動 , 回目以降も行動 を選択する.]
ゆえに, しっぺ返し戦略が最適反応となるには
プレイヤー2の同様の議論が言える. ゆえに求めるべき条件は, (END)
f∞1
δ (x) = (1 − δ)(2 + 2δ1
+ ⋯ + 2δm−2
) + 2δm−1
(1 − δ)
1
1 − δ
= (1 − δ)(2 + 2δ1
+ ⋯ + 2δm−2
) + 2δm−1
m − 1 m ≥ 2 a m b m + 1 b
f∞1
δ (x′

) = (1 − δ)(2 + 2δ1
+ ⋯ + 2δm−2
) + 3δm−1
(1 − δ) + δm
f∞1
δ (x) ≥ f∞1
δ (x′

) ⇔ 2δm−1
≥ 3δm−1
(1 − δ) + δm
⇔ 2 ≥ 3(1 − δ) + δ ⇔ 2 ≥ 3 − 3δ + δ ⇔ δ ≥
1
2
δ ≥
1
2
1\ 2 a b
a 2, 2 0, 3
b 3, 0 1, 1](https://image.slidesharecdn.com/basic118-241222123943-d801aa81/85/BASIC-117-2-7-320.jpg)














































