Download to read offline






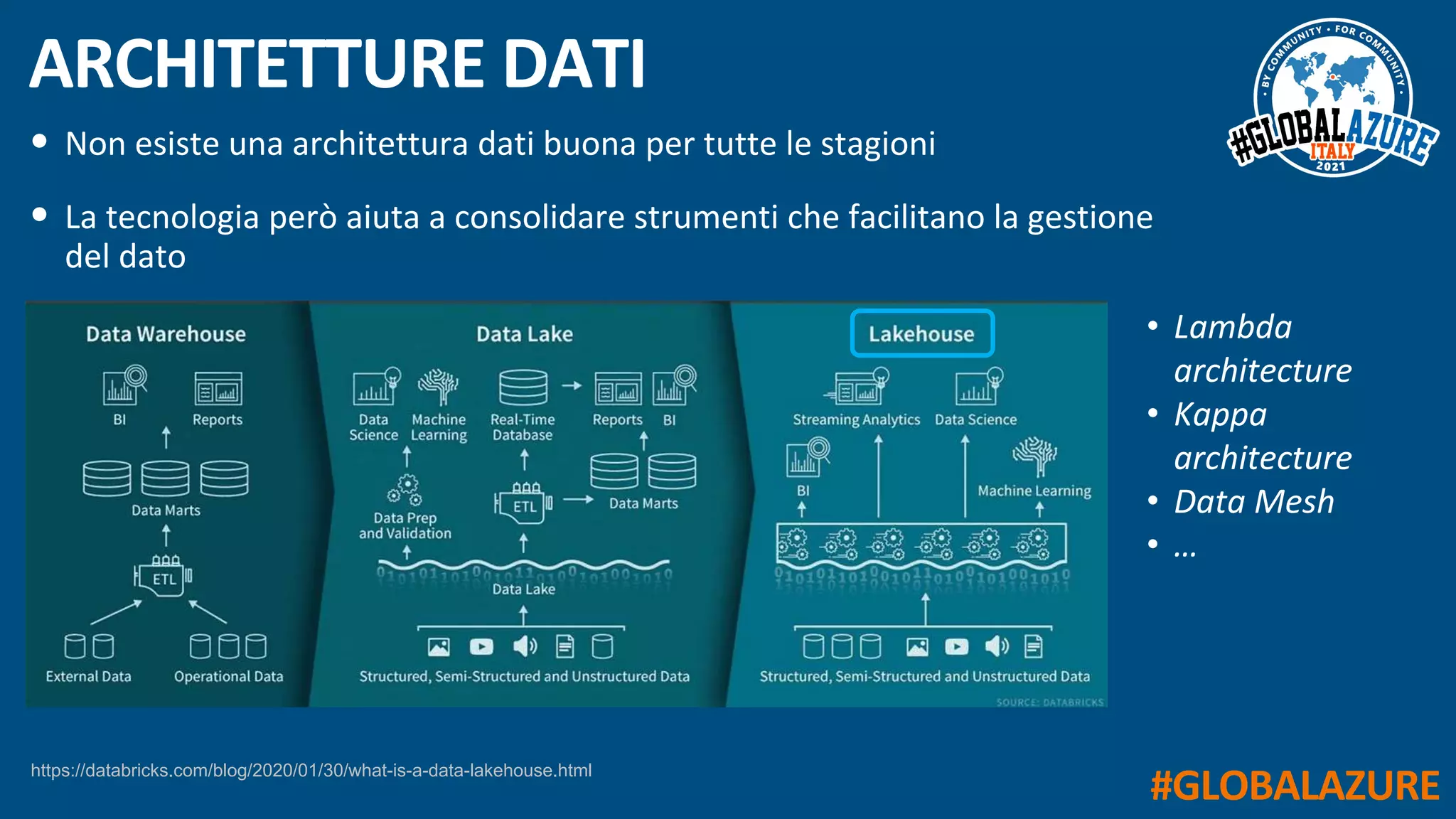



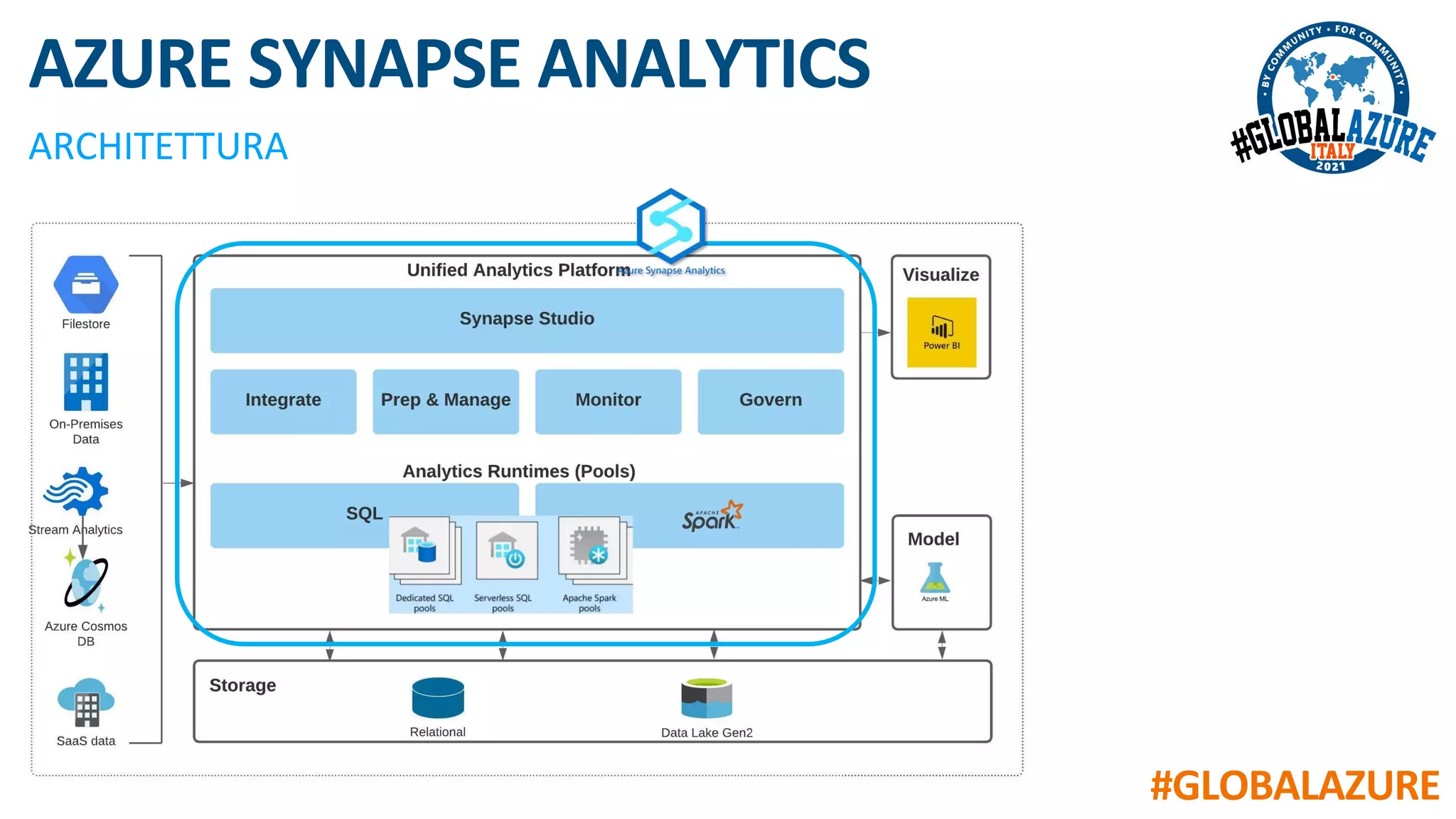
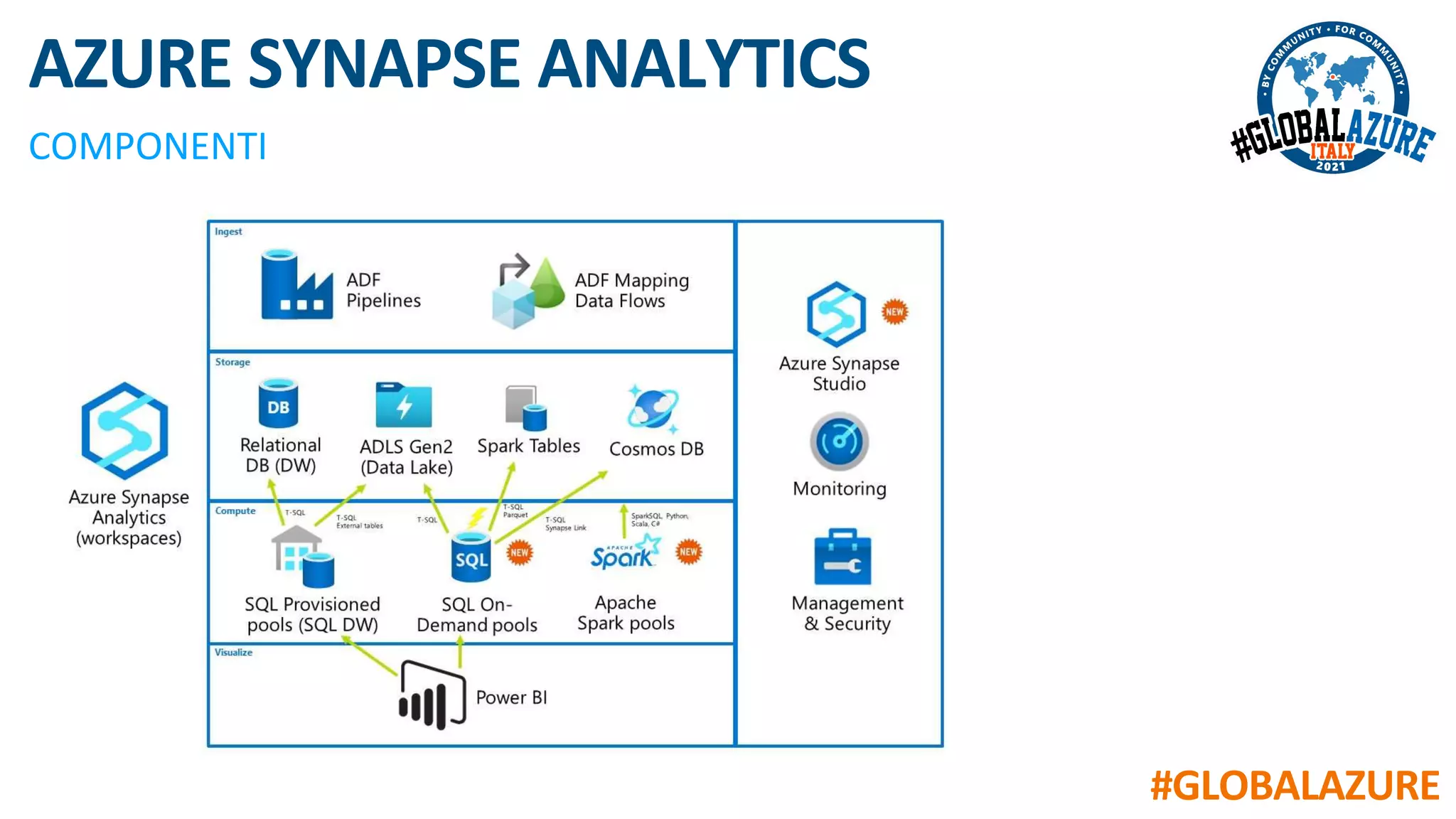




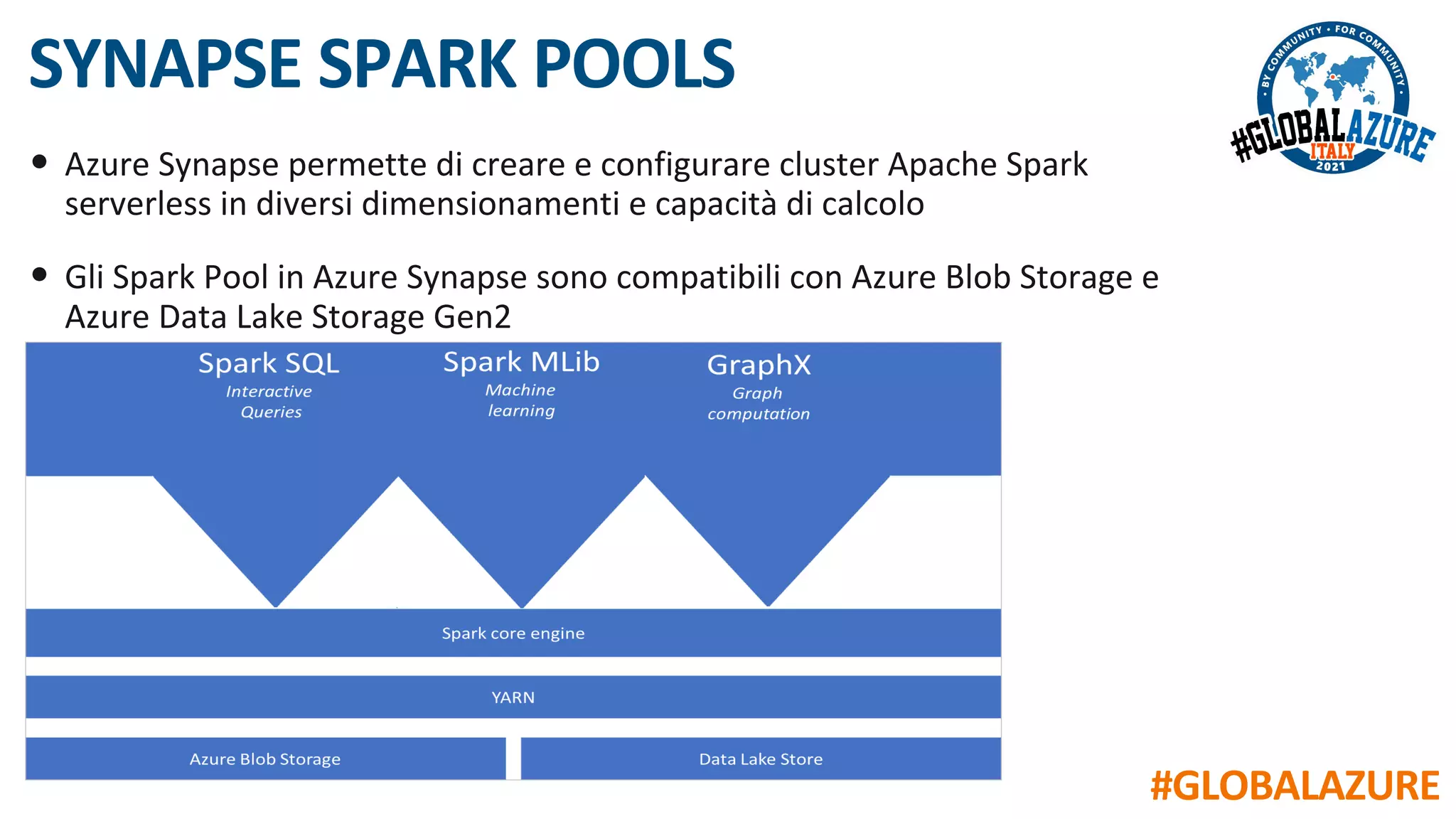




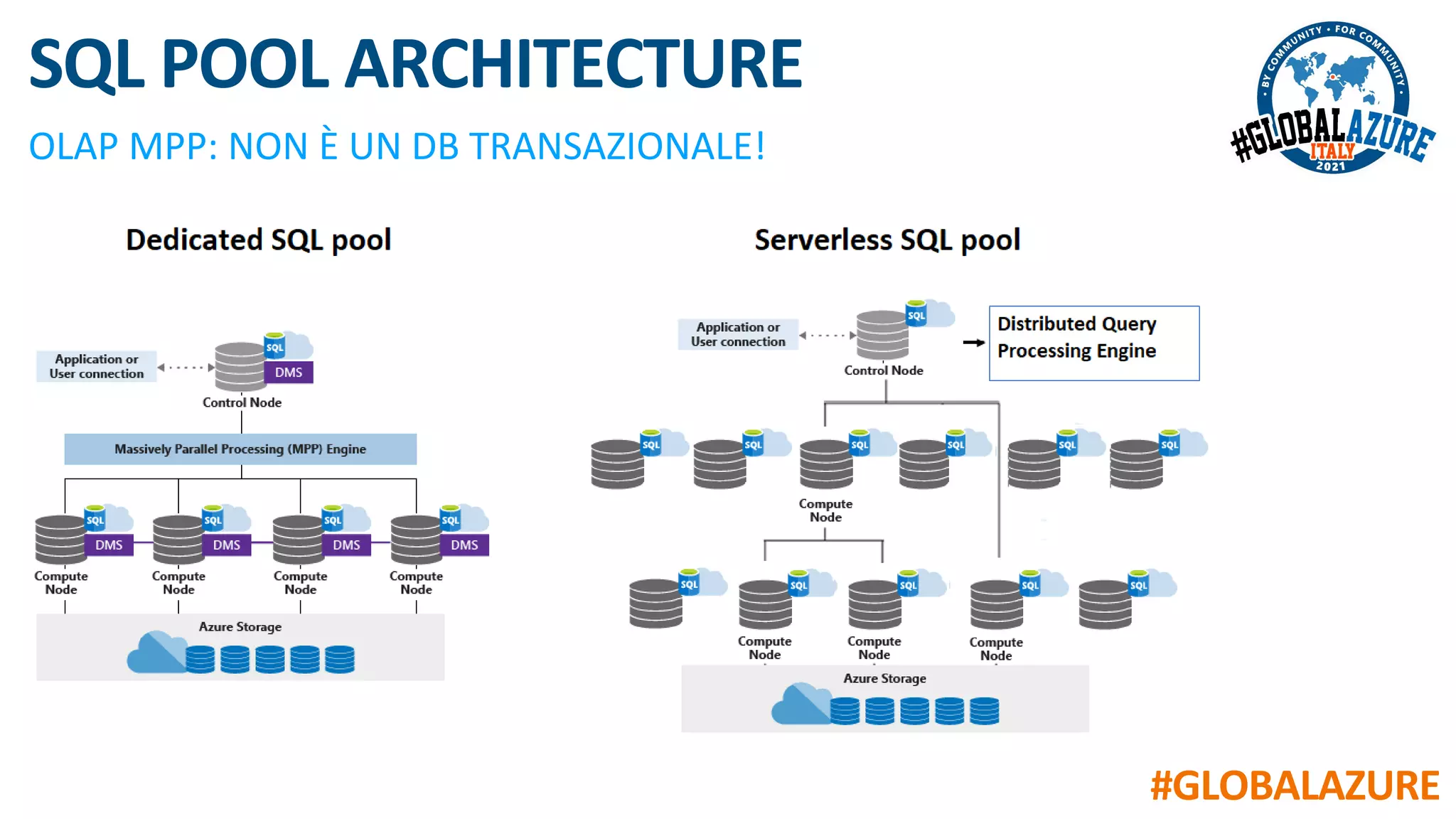








Il documento riguarda un evento virtuale sulla piattaforma Azure Synapse, evidenziando le funzionalità chiave come il data lakehouse e l'analisi dei dati. Viene presentata un'architettura moderna per la gestione dei dati tramite strumenti come SQL Pools, Spark Pools e Data Pipelines, facilitando l'elaborazione e l'analisi dei dati. L'accento è posto sull'integrazione di vari servizi all'interno di un ambiente unificato per ottimizzare operazioni ETL e garantire prestazioni scalabili.































































