Download to read offline



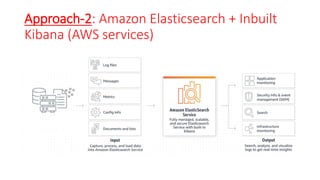
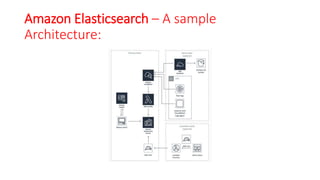


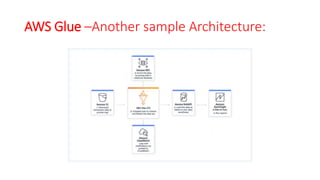

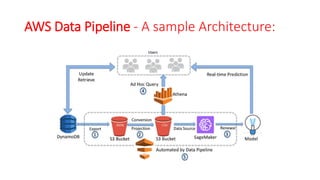

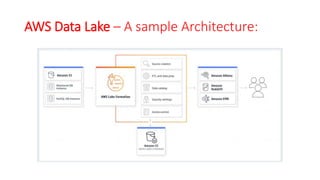
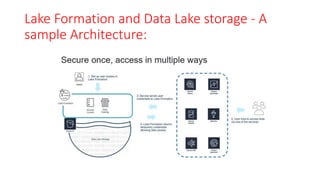
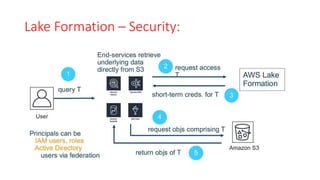

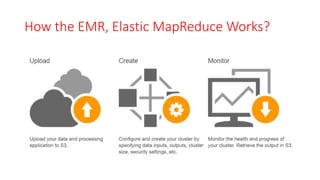

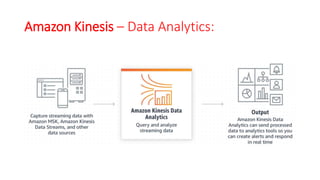
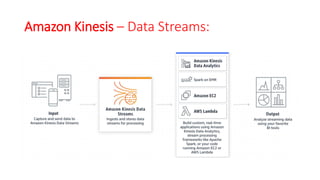
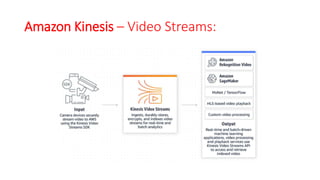
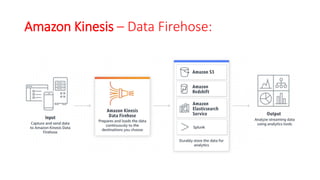



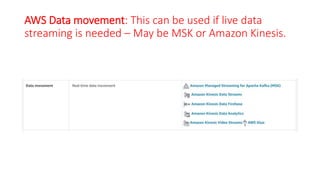





The document discusses various approaches for centralized logging, data analytics, visualization, and ETL services using AWS tools. It covers several AWS services, including Amazon Elasticsearch, AWS Glue, AWS Data Pipeline, Amazon EMR, and Amazon Kinesis, highlighting their functionalities and architectures for handling data processing and analytics. Each approach is tailored to specific use cases, emphasizing the need to select appropriate tools based on organizational requirements.






























































