Download to read offline


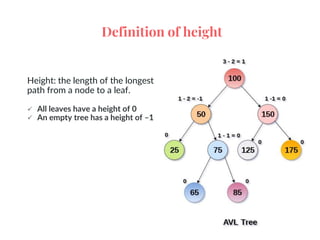

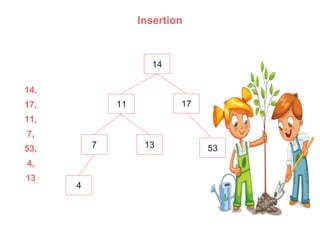
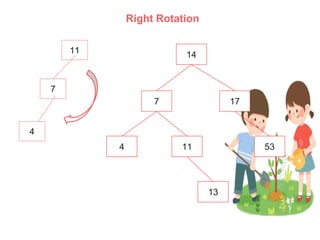
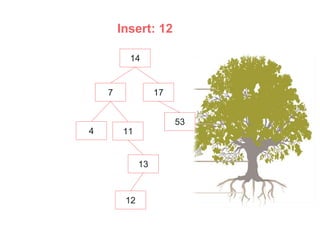


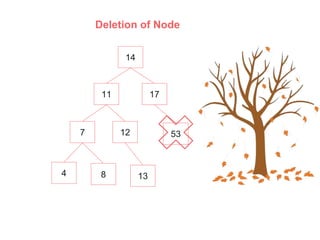
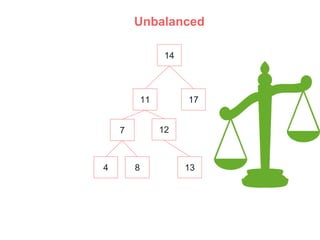
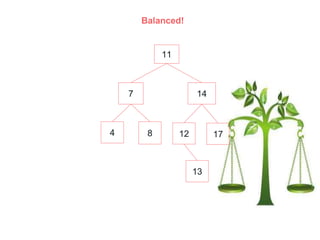


An AVL (Adelson-Velskii & Landis) tree is a self-balancing binary search tree where the height difference between subtrees is at most one, ensuring O(log n) time complexity for lookup, insertion, and deletion operations. It employs rotations to maintain balance during inserts and deletes, including left, right, left-right, and right-left rotations. The document illustrates insertion and deletion processes, demonstrating how to rebalance the tree as necessary.














































