Download to read offline






















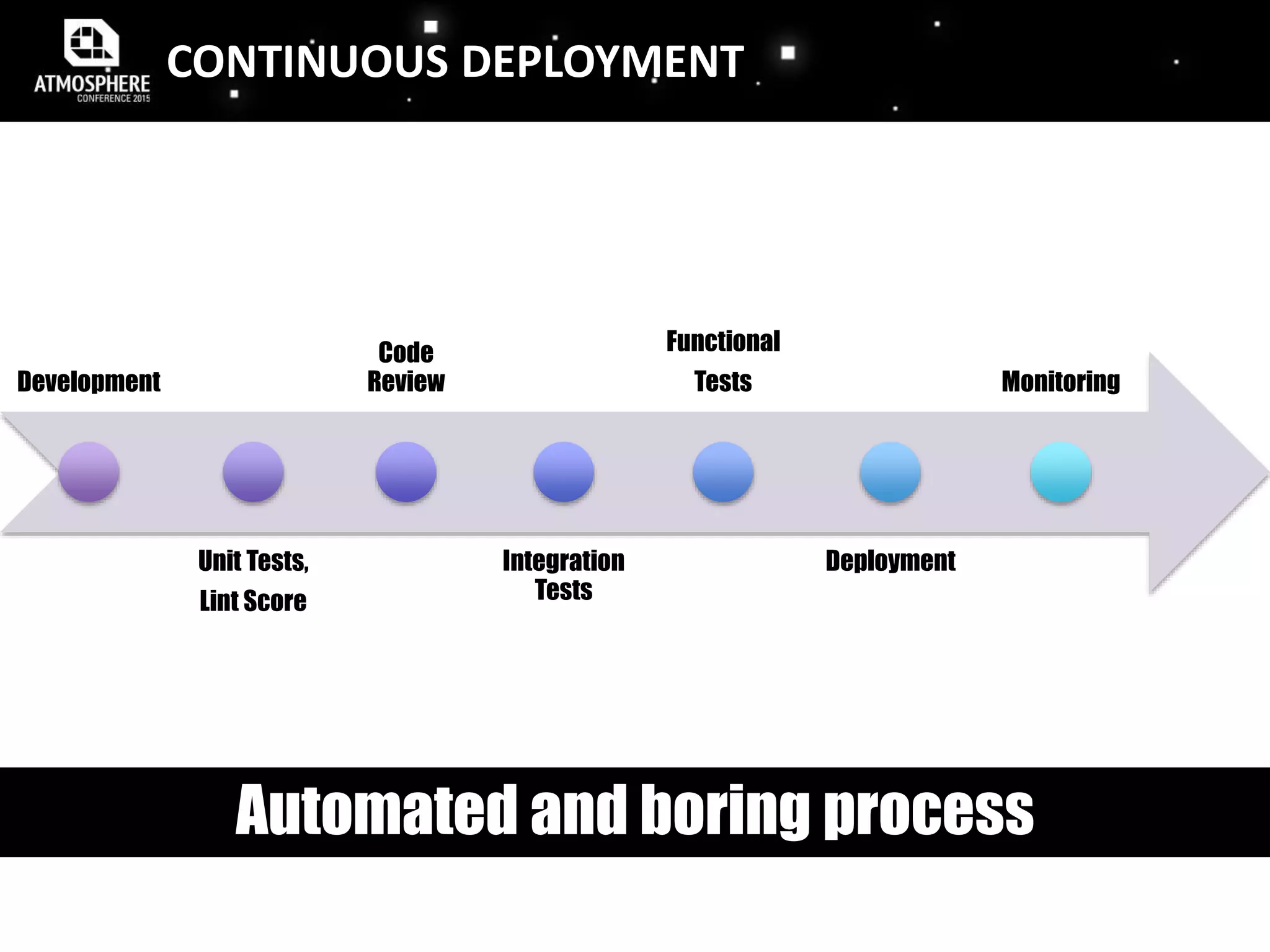


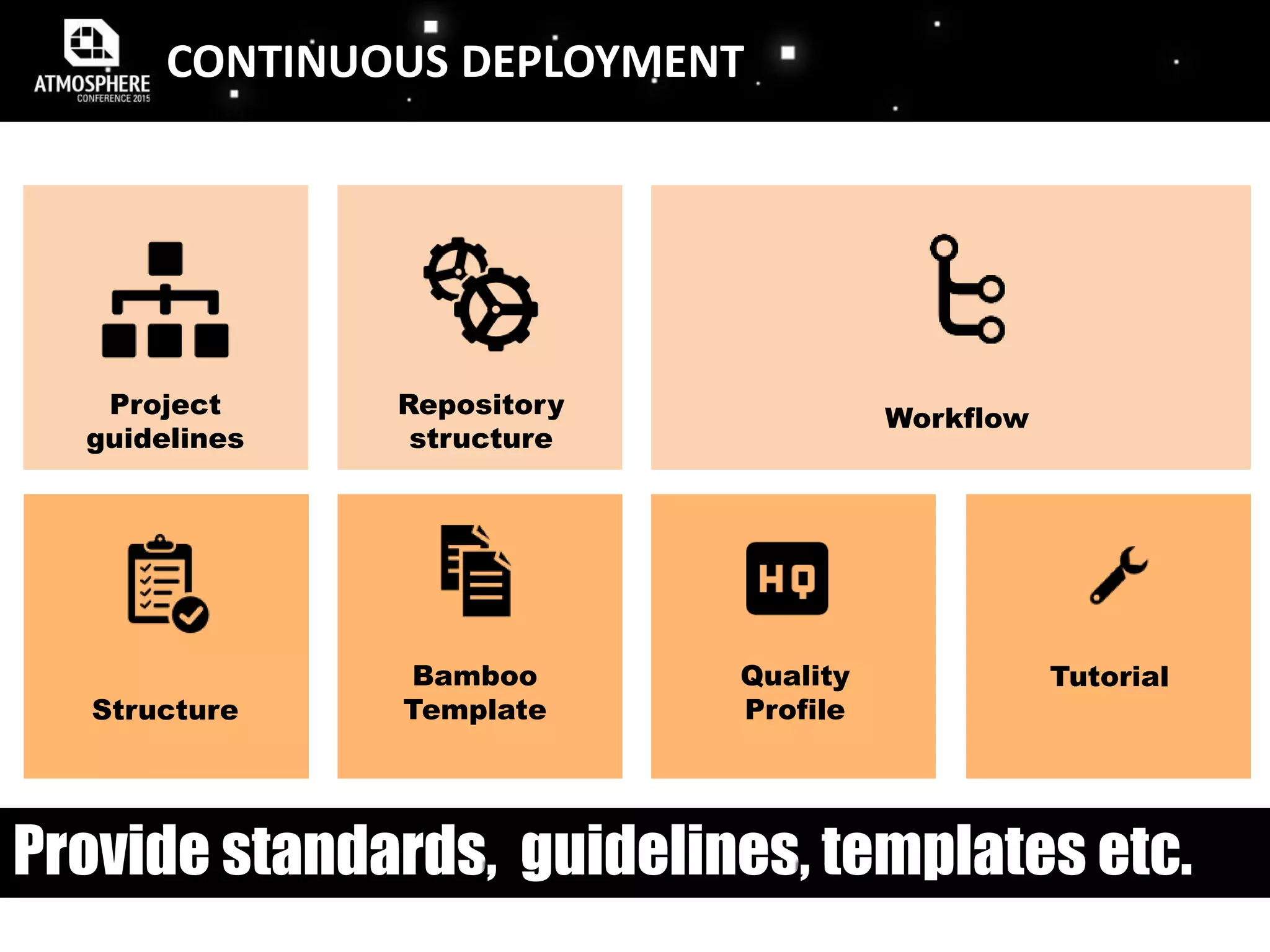


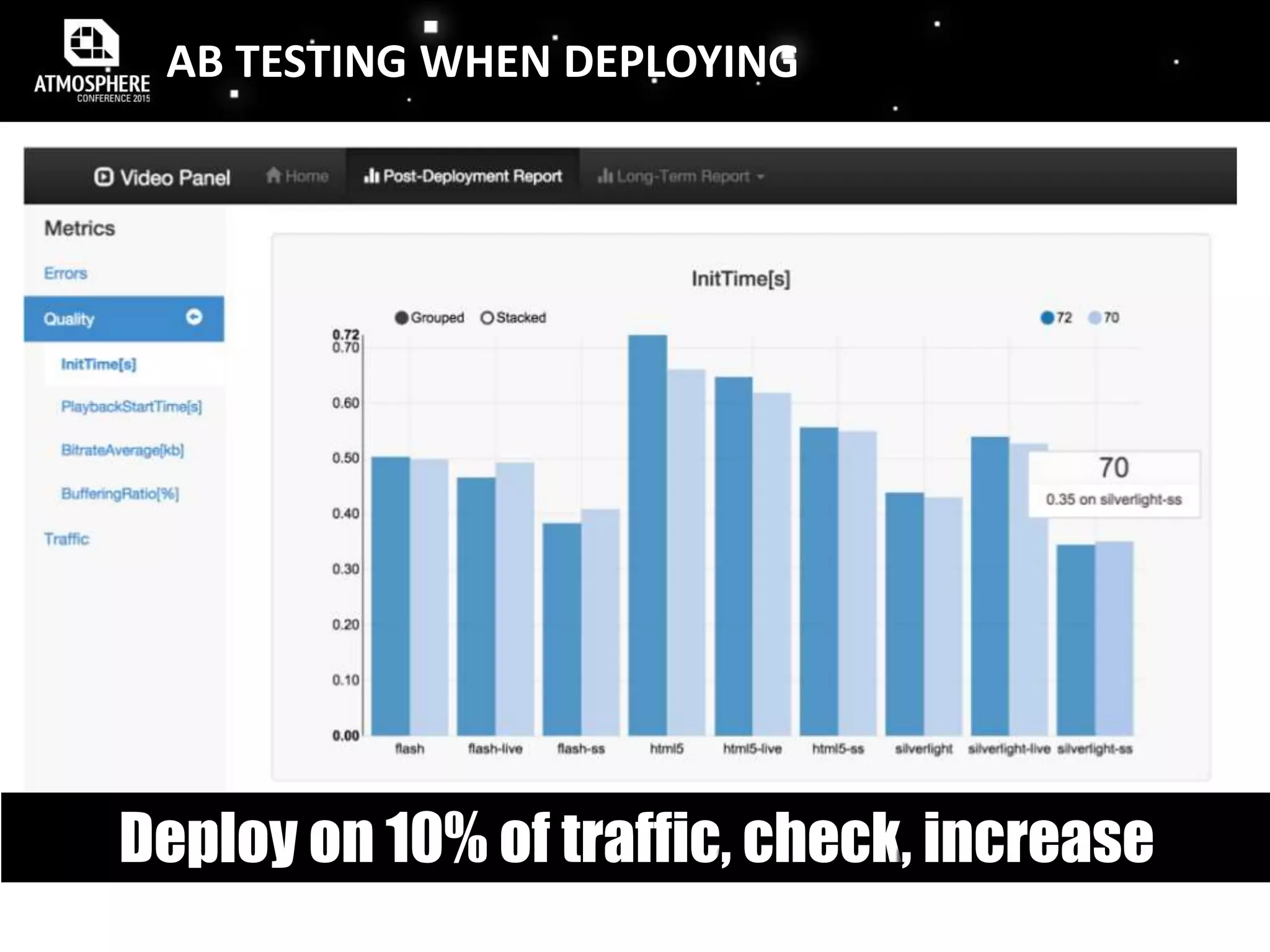

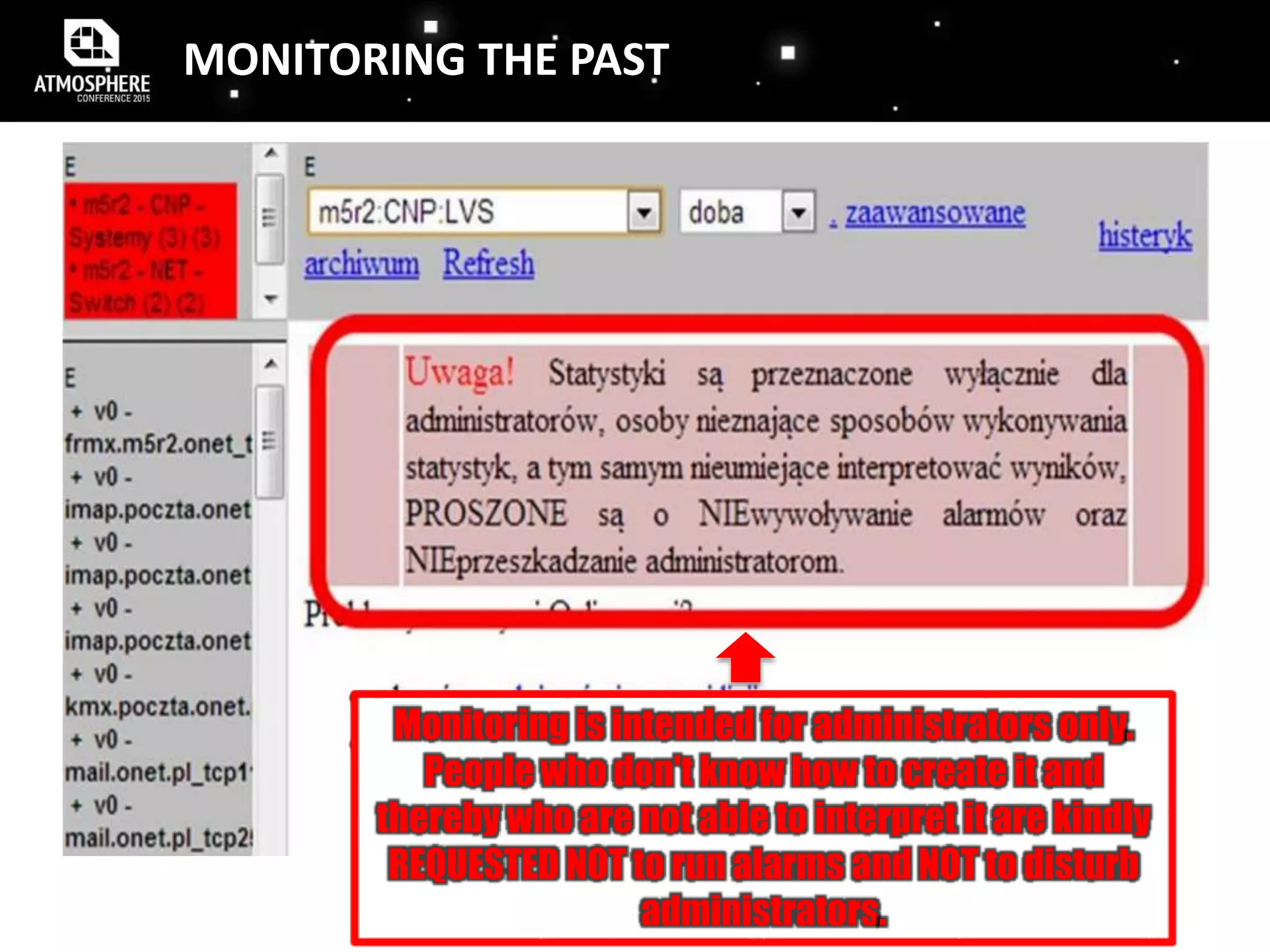


![MONITORING FEEDBACK LOOP
MaaS Team [24/7/365]
Product/TeamReactive
Proactive
Monitoring points (buttons)
Troubleshooters/HowTo’s
Escalation Path
Trainings
First aid based on Howto's
Fake alarms, lack of
alarms](https://image.slidesharecdn.com/jerzygulczynski-150602131348-lva1-app6892/75/Atmosphere-Conference-2015-DevOps-sum-is-greater-than-its-parts-42-2048.jpg)




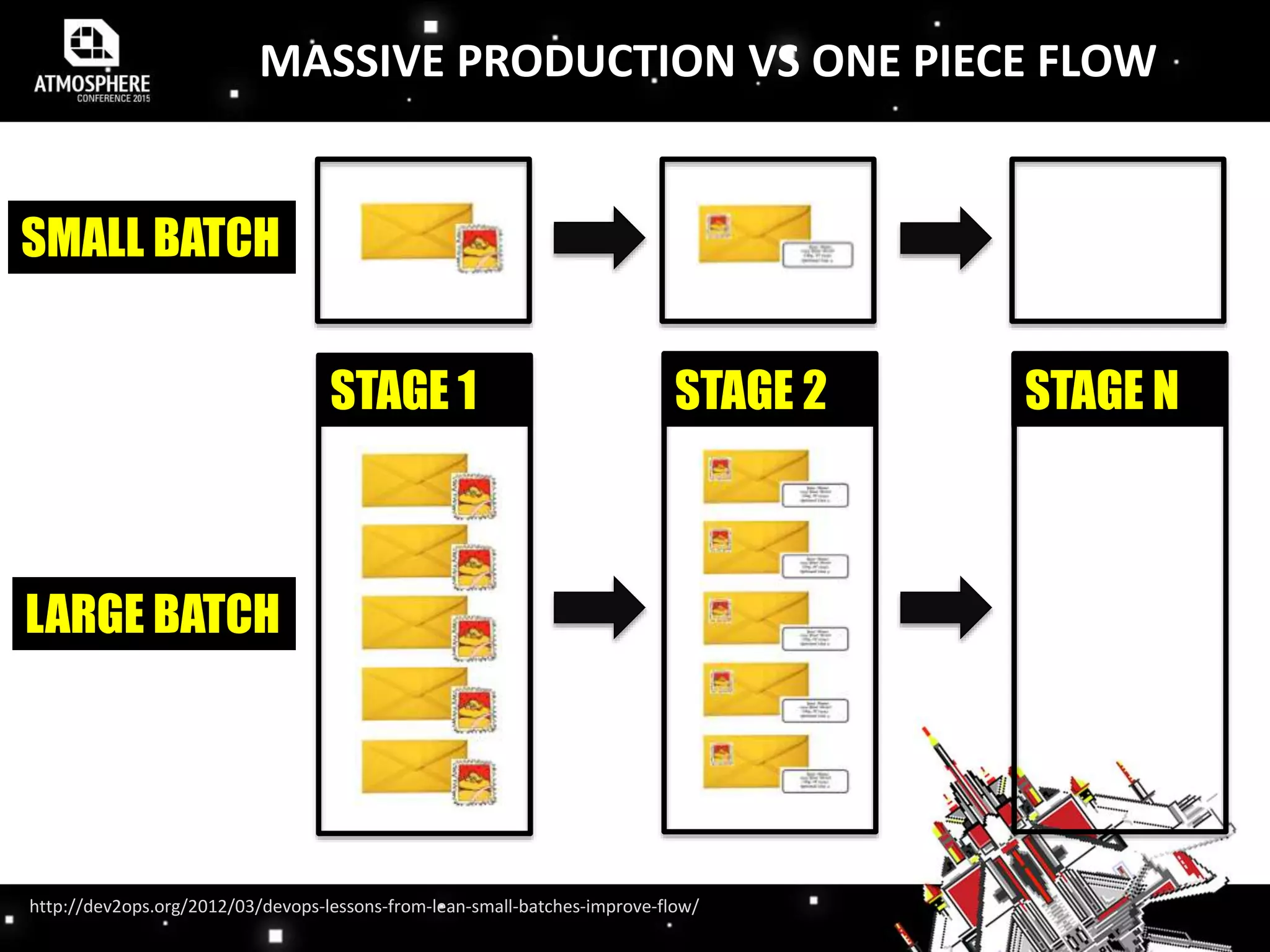
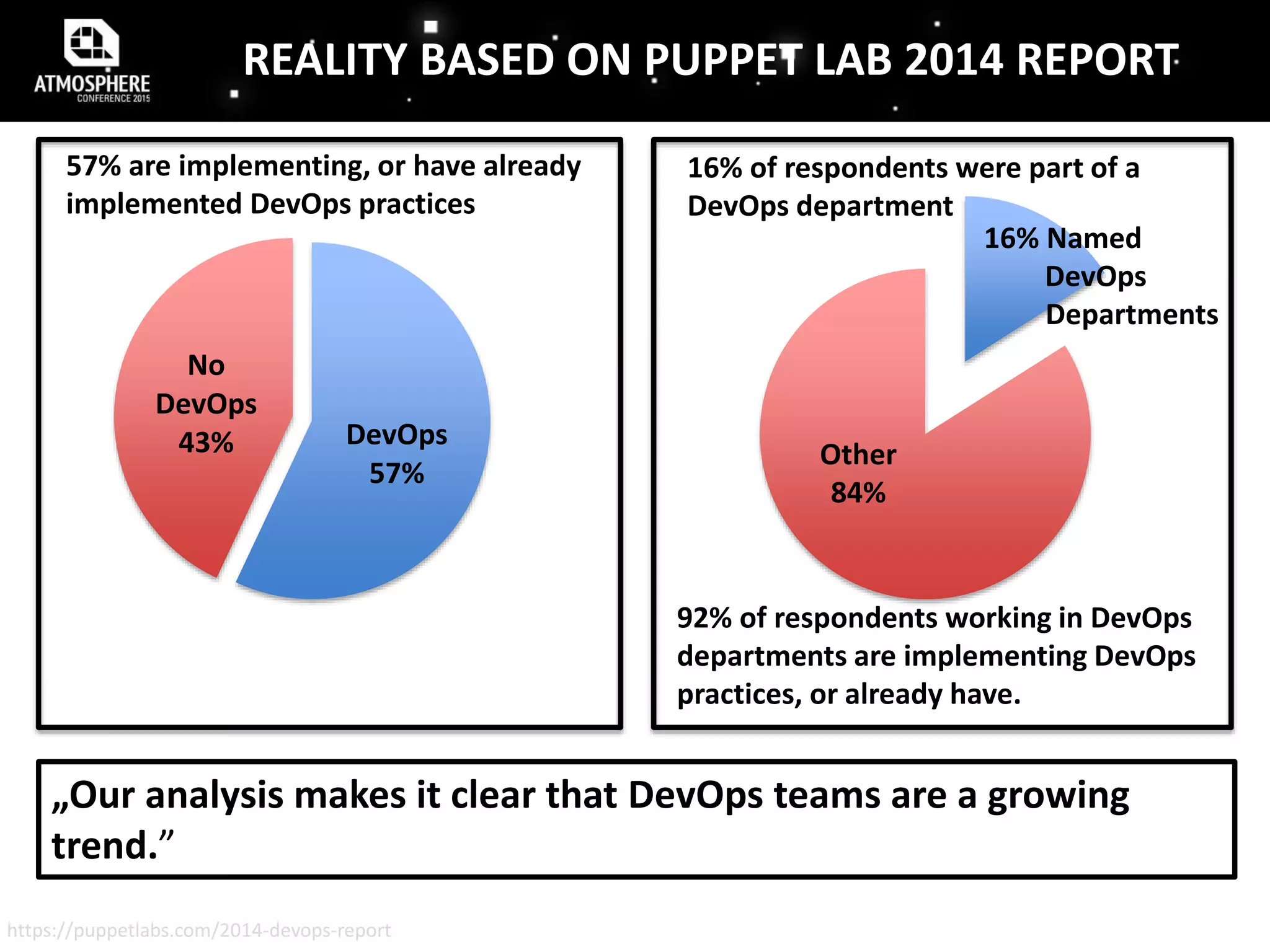
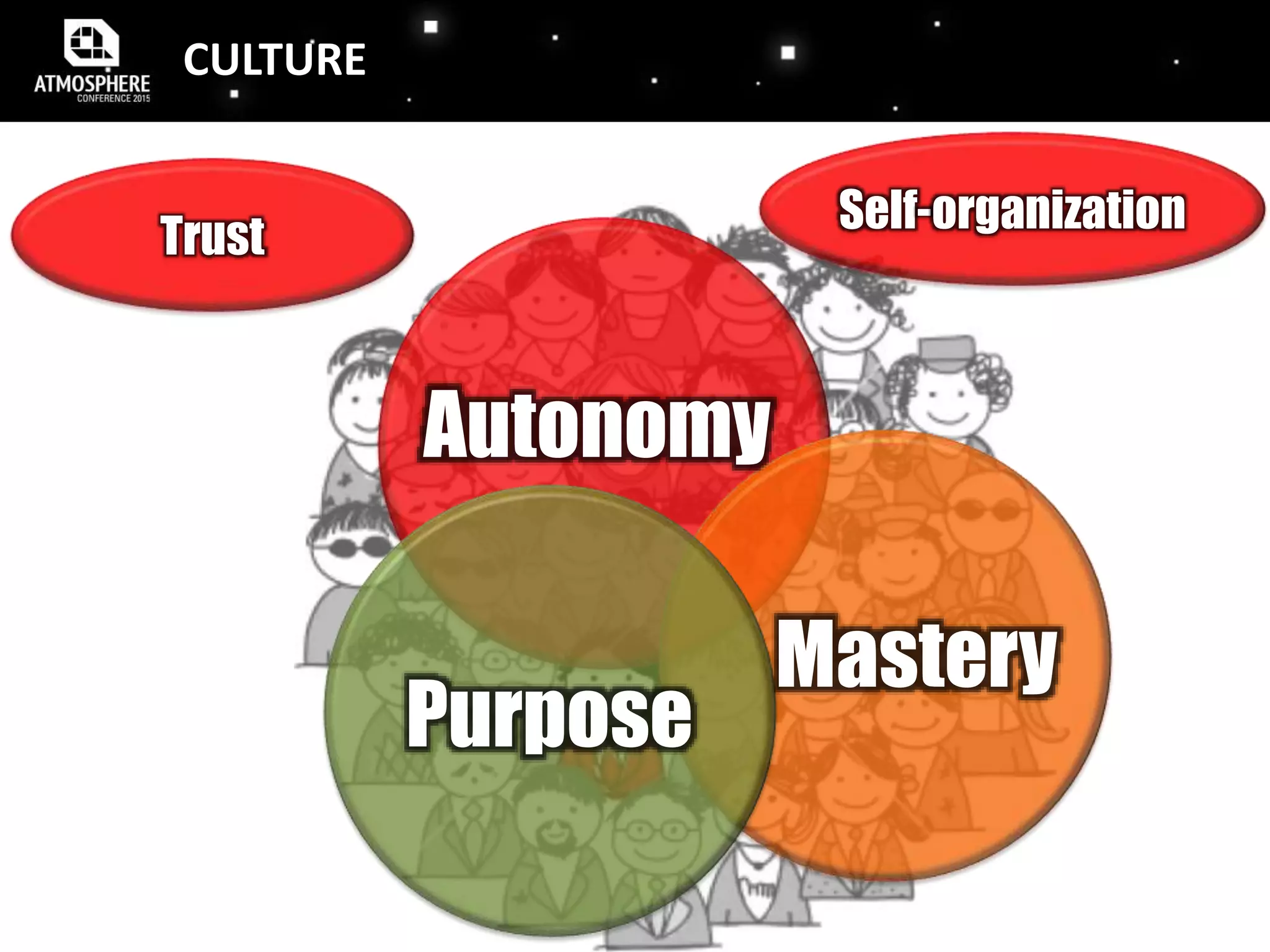
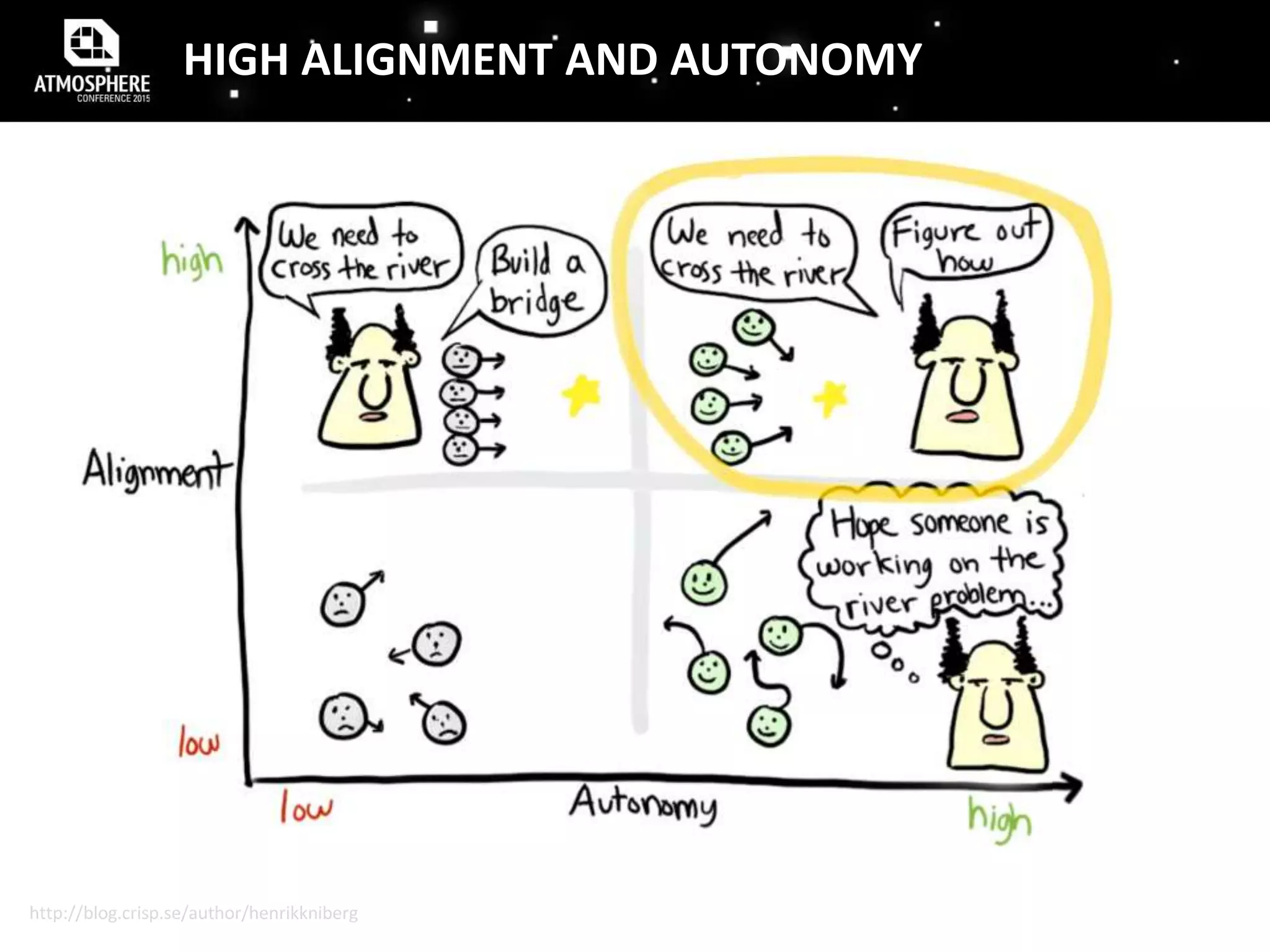
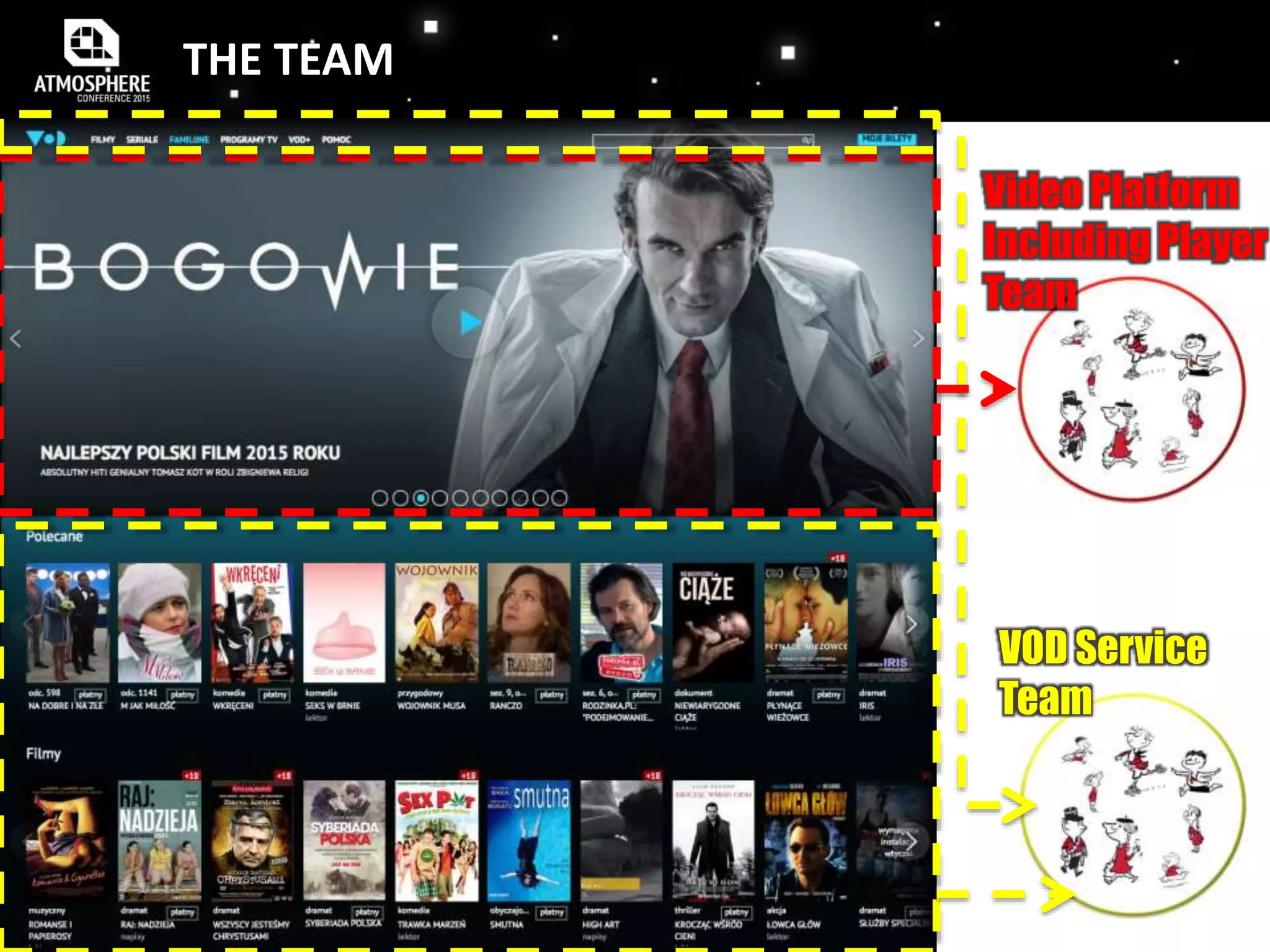
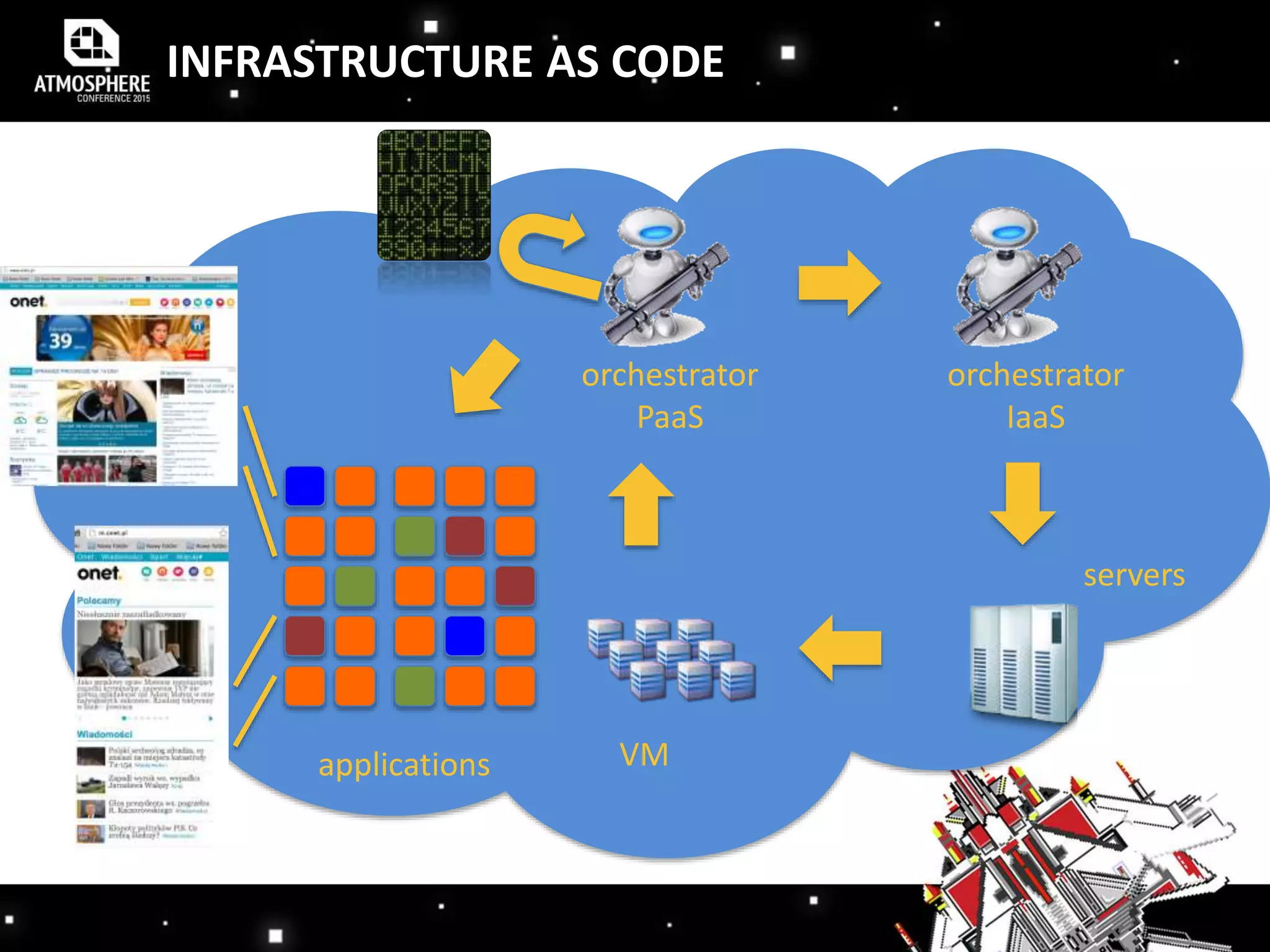
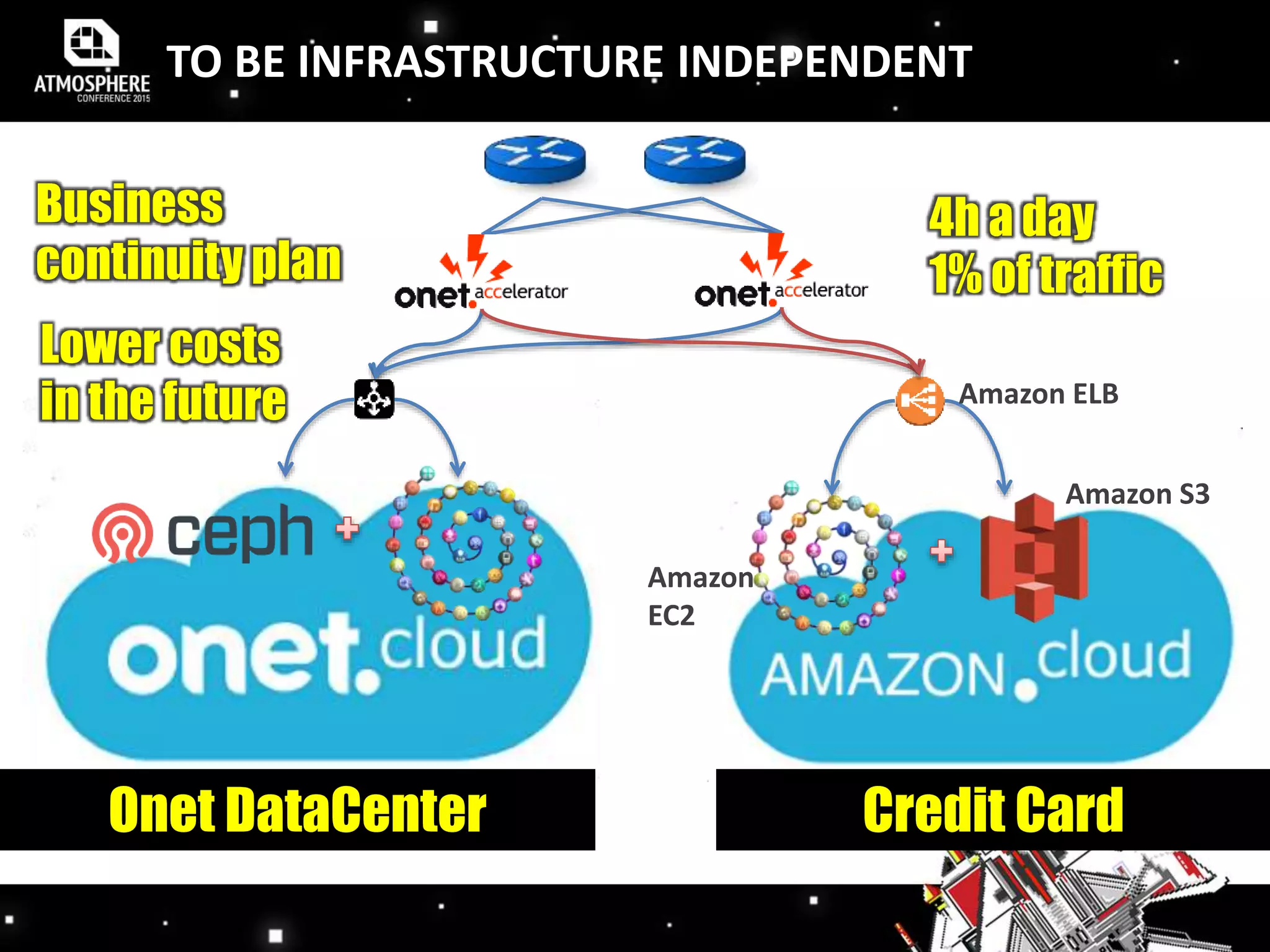
The document discusses the evolution and implementation of DevOps practices, highlighting the transition towards agile methodologies and the benefits of self-organized teams. It emphasizes the importance of continuous deployment, monitoring, and a culture of transparency and collaboration within DevOps teams. Additionally, it presents statistics indicating a growing trend in organizations adopting these practices to improve efficiency and reduce failures.




























![[CONFidence 2016] Glenn ten Cate - OWASP-SKF Making the web secure by design,...](https://cdn.slidesharecdn.com/ss_thumbnails/glentencate-owasp-skfmakingthewebsecurebydesignbecomeempoweredbetheneo-160603100034-thumbnail.jpg?width=640&height=640&fit=bounds)










![[4developers] - ScalaJS – web without pain of JavaScript](https://cdn.slidesharecdn.com/ss_thumbnails/scalajs-160531133851-thumbnail.jpg?width=640&height=640&fit=bounds)








![Agility and Control from AWS [FutureStack16]](https://cdn.slidesharecdn.com/ss_thumbnails/agilityandcontroldougleeaws-161201210211-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)






