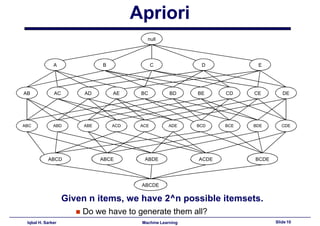
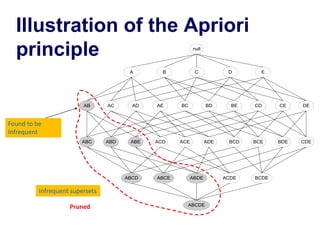
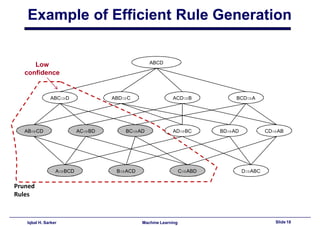
This document discusses association rule learning and frequent pattern mining. It begins with an introduction to association rule mining using a grocery store example. It then describes the Apriori algorithm for finding frequent itemsets and generating association rules. The algorithm works in two steps - first finding all frequent itemsets whose support is above a minimum threshold, and then generating association rules from those itemsets where the confidence is above a minimum. An example run of the Apriori algorithm on a transactional database is shown. Finally, some potential application areas for association rule mining are discussed.















![Relevant Algorithms
1. Apriori
2. FP-Growth
3. ECLAT
4. ABC-RuleMiner (Sarker et al., Elsevier)
[ABC-RuleMiner: User behavioral rule-based machine learning method for
context-aware intelligent services, Journal of Network and Computer
Applications, Elsevier, 2020]
5. Others…
Iqbal H. Sarker Machine Learning Slide 19](https://image.slidesharecdn.com/association-analysis-230405082710-ebe685df/85/Association-Analysis-pdf-19-320.jpg)

















































