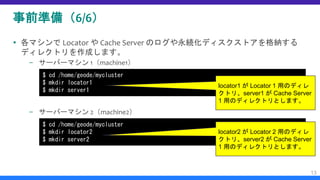
データオブジェクト設計と Region 作成(10/12)
[任意設定] シリアライザーの設定(4/5)
– さて、“configure pdx” コマンドを実行すると、以下のような不穏な
メッセージがでてくると思います。
– はい、PDX シリアライザー設定を有効化するには、すでに起動して
いる Cache Server を再起動する必要があります。
34
The command would only take effect on new data members joining the distributed
system. It won't affect the existing data members
:
Non portable classes :[quitada.*]
35.
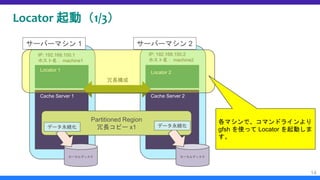
データオブジェクト設計と Region 作成(11/12)
[任意設定] シリアライザーの設定(5/5)
– ということでまず以下の gfsh の “stop server” コマンドを使ってコマンドラ
インより Cache Serverを停止します。
– サーバーマシン 1(machine1)の Cache Server 停止
– サーバーマシン 2(machine2)の Cache Server 停止
– その後、先で言及した “start server” コマンドで各 Cache Server を再起動し
ます。
35
$ cd /home/geode/mycluster
$ gfsh stop server --dir=server1
$ cd /home/geode/mycluster
$ gfsh stop server --dir=server2
36.
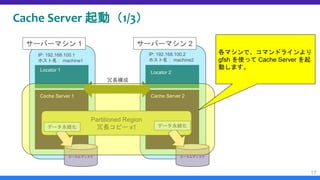
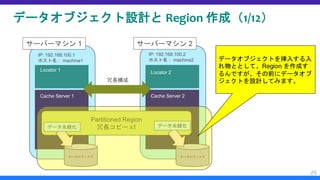
データオブジェクト設計と Region 作成(12/12)
Region の作成
– SQL で create table を実行するイメージ(?)で、以下のようなコマンドを実行します。
– “—name=/Employee” とすることで、“Employee” という名前の Region を作成します。なお
Region 名の前に付与されているスラッシュは省略可能です。
– “—type=PARTITION_REDUNDANT_PERSISTENT” とすることで、Region 型として、データを各
サーバに分散配置(PARTITION)、高可用性確保のため他の Cache Server に各データのコピーを
1 つ保持(REDUNDANT)、全データをディスクに永続化(PERSISTENT)としています。
– “—key-constraint=java.lang.String” とすることで、Key として挿入可能なオブジェクトは文字列型
のみとなります。
– “—value-constraint=quitada.Employee” とすることで、Value として挿入可能なオブジェクトはド
メインオブジェクトとしてさきほど作成した quitada.Employee 型のみとなります。
36
gfsh>create region --name=/Employee --type=PARTITION_REDUNDANT_PERSISTENT --key-
constraint=java.lang.String --value-constraint=quitada.Employee







![事前準備(4/6)
設定ファイルの作成(2/3)
– サーバーマシン 1(machine1)
– サーバーマシン 2(machine2)
11
log-level=config
locators=machine1[55221],machine2[55221]
bind-address=machine1
server-bind-address=machine1
jmx-manager-bind-address=machine1
log-level=config
locators=machine1[55221],machine2[55221]
bind-address=machine2
server-bind-address=machine2
jmx-manager-bind-address=machine2](https://image.slidesharecdn.com/mgmtapachegeodewithgfsh-170818083242/85/Apache-Geode-gfsh-11-320.jpg)
![事前準備(5/6)
設定ファイルの作成(3/3)
– 各パラメーターの意味
▪ log-level : ログレベルです。config レベルに設定すると、一般的な info レベルに加えてクラ
スターの設定内容も出力されるので、正しく設定されているかどうか確認のため便利です。
▪ locators : Locator 一覧(ホスト名[ポート番号])をあらかじめ設定する必要があります。
▪ bind-address : クラスター内通信用のホスト名を指定します。NIC が 1 つだけの時は設定不要
ですが、意図したネットワークセグメントで通信しているかどうか確認のため明示的に設
定することをおすすめします。
▪ server-bind-address : クライアントサーバー通信用のホスト名を指定します。NIC が 1 つだけ
の時は bind-address 同様設定不要です。Cache Server だけに有効なパラメーターです。
▪ jmx-manager-bind-address : JMX マネージャー通信用のホスト名を指定します。NIC が 1 つだ
けの時は bind-address 同様設定不要です。JMX マネージャーサービスが稼働する Locator あ
るいは Cache Server にのみ有効なパラメーターです。デフォルトでは、一番最初に起動す
る Locator のみに適用されるパラメーターとなります。
▪ ホスト名を指定するパラメーターに関しては、代わりに IP 直指定でもかまいません。
12](https://image.slidesharecdn.com/mgmtapachegeodewithgfsh-170818083242/85/Apache-Geode-gfsh-12-320.jpg)





![gfsh によるクラスター管理(2/2)
大部分のコマンドを実行するには、まず、以下のコマンドでいずれかの Locator に接続す
る必要があります。
– --locator パラメーターに、Locator のホスト名とポート番号を指定します
以下の管理コマンドを実行してみます。
22
gfsh>connect --locator=machine1[55221]
gfsh>help
gfsh>list members
gfsh>show log —member=server1 —lines=100
gfsh>change loglevel —loglevel=fine --members=server1
gfsh>show log —member=server1 —lines=100
gfsh>change loglevel --loglevel=config --members=server1
gfsh>status server —name=server1
gfsh>describe member —name=server1](https://image.slidesharecdn.com/mgmtapachegeodewithgfsh-170818083242/85/Apache-Geode-gfsh-22-320.jpg)






![データオブジェクト設計と Region 作成(7/12)
[任意設定] シリアライザーの設定(1/5)
– ドメインオブジェクトを通信経路にのせるため、シリアライズ可能
であるよう設定する必要があります。
– ドメインオブジェクトの Java クラスをシリアライズ可能であるよ
うに実装していれば明示的なシリアライザー設定は不要です
(implements java.io.Serializable 付与してるとか)。
– ドメインオブジェクトの Java クラス自体がシリアライズ不可であ
る場合は、gfsh でシリアライザーの設定を行います。なお、シリア
ライザーは、Apache Geode 独自のシリアライズフォーマットであ
る PDX(Portable Data eXchange)のオートシリアライザーを適用し
ます。
31](https://image.slidesharecdn.com/mgmtapachegeodewithgfsh-170818083242/85/Apache-Geode-gfsh-31-320.jpg)
![データオブジェクト設計と Region 作成(8/12)
[任意設定] シリアライザーの設定(2/5)
– まず対象クラスの PDX メタデータを永続化するディスクストアを以下のコマンドで
作成します。PDX メタデータの永続化は必須ではありませんが、Cache Server 再起動
の度に再作成するコスト削減のため設定が推奨されます。
– “—dir=pdx” と指定することで各 Cache Server ディレクトリ配下に PDX メタデータ永
続化ディスクストア格納用に pdx というディレクトリが作成されます。今回の例で
は、以下のディレクトリー配下に作成されます。
▪ machine1:/home/geode/mycluster/server1/pdx
▪ machine2:/home/geode/mycluster/server2/pdx
– “—name=pdx” と指定することで、当該ディスクストアを “pdx” という名前で参照
可能となります。
32
gfsh>create disk-store --name=pdx --dir=pdx](https://image.slidesharecdn.com/mgmtapachegeodewithgfsh-170818083242/85/Apache-Geode-gfsh-32-320.jpg)
![データオブジェクト設計と Region 作成(9/12)
[任意設定] シリアライザーの設定(3/5)
– 次に、以下のコマンドで PDX ベースのシリアライザーを設定します。
– “—read-serialized=false” とすることで、ドメインオブジェクトをそのもののオブ
ジェクト型で読み込みます。逆に “true” とした場合は、必ず PdxInstance 型のオブ
ジェクトとして読み込みます(対象ドメインオブジェクトがシリアライズされたま
ま PdxInstance 型の入れ物に入っているイメージです)。
– “—disk-store=pdx” とすることで、先ほど作成した “pdx” という名前のディスクスト
アに PDX メタデータを格納するよう指定します。
– “—auto-serializable-classes=quitada.*” とすることで、quitada というパッケージの全
てのドメインオブジェクトを自動的にシリアライズ可能とします。
33
gfsh>configure pdx --read-serialized=false --disk-store=pdx --auto-serializable-
classes=quitada.*](https://image.slidesharecdn.com/mgmtapachegeodewithgfsh-170818083242/85/Apache-Geode-gfsh-33-320.jpg)
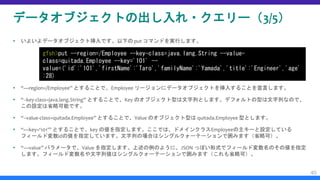
![データオブジェクト設計と Region 作成(10/12)
[任意設定] シリアライザーの設定(4/5)
– さて、“configure pdx” コマンドを実行すると、以下のような不穏な
メッセージがでてくると思います。
– はい、PDX シリアライザー設定を有効化するには、すでに起動して
いる Cache Server を再起動する必要があります。
34
The command would only take effect on new data members joining the distributed
system. It won't affect the existing data members
:
Non portable classes :[quitada.*]](https://image.slidesharecdn.com/mgmtapachegeodewithgfsh-170818083242/85/Apache-Geode-gfsh-34-320.jpg)
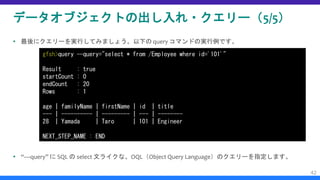
![データオブジェクト設計と Region 作成(11/12)
[任意設定] シリアライザーの設定(5/5)
– ということでまず以下の gfsh の “stop server” コマンドを使ってコマンドラ
インより Cache Serverを停止します。
– サーバーマシン 1(machine1)の Cache Server 停止
– サーバーマシン 2(machine2)の Cache Server 停止
– その後、先で言及した “start server” コマンドで各 Cache Server を再起動し
ます。
35
$ cd /home/geode/mycluster
$ gfsh stop server --dir=server1
$ cd /home/geode/mycluster
$ gfsh stop server --dir=server2](https://image.slidesharecdn.com/mgmtapachegeodewithgfsh-170818083242/85/Apache-Geode-gfsh-35-320.jpg)































![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://cdn.slidesharecdn.com/ss_thumbnails/gke02-200121091040-thumbnail.jpg?width=640&height=640&fit=bounds)



















