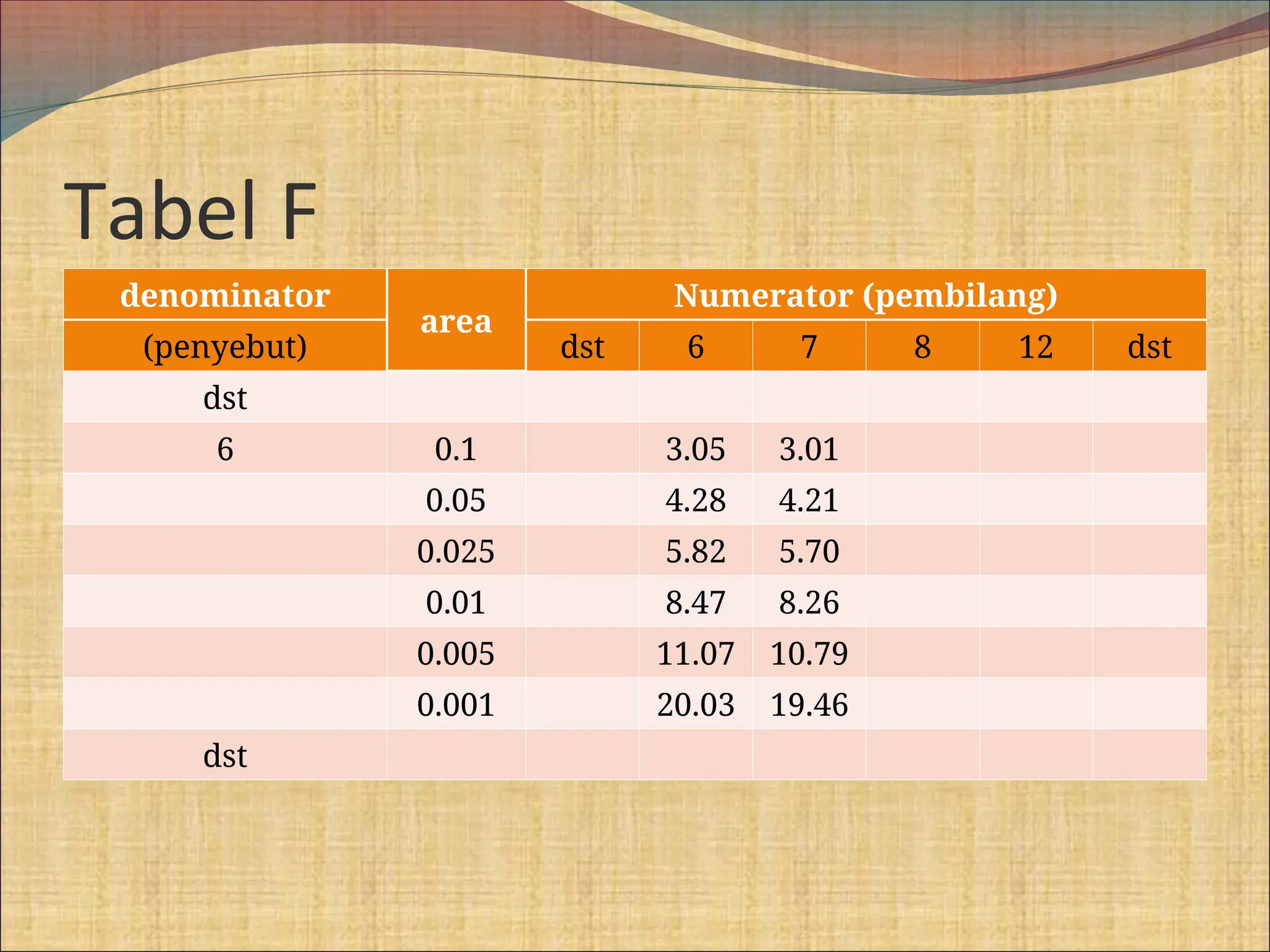
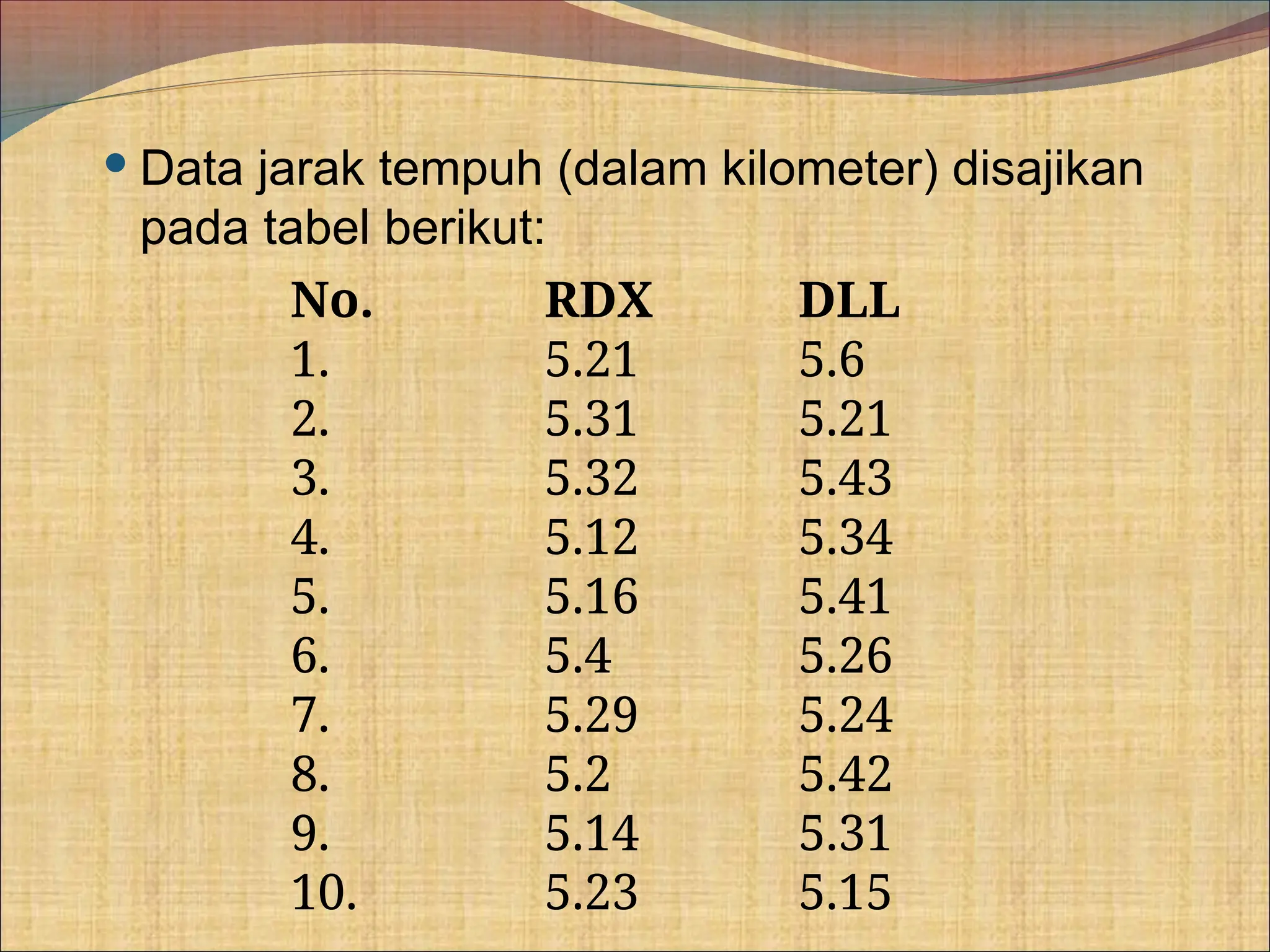
Dokumen ini membahas berbagai metode statistik untuk menguji perbedaan rata-rata antara populasi dan sampel, termasuk uji z, uji t independen, dan uji t berpasangan. Contoh kasus yang diberikan melibatkan pengujian kadar kolesterol pada pasien hipertensi dan efektivitas obat baru pada gangguan tidur. Selain itu, dokumen ini menjelaskan pentingnya asumsi normalitas dan homogenitas ragam dalam analisis statistik.