Downloaded 75 times





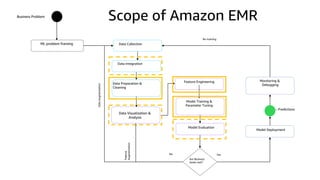

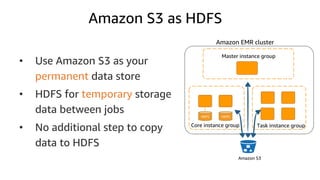
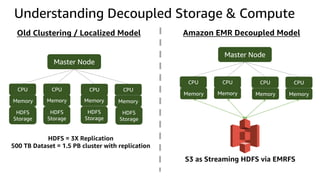
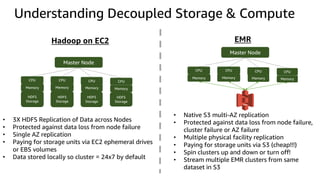

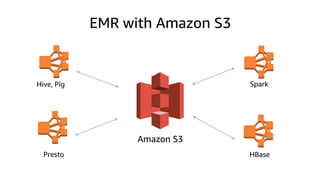
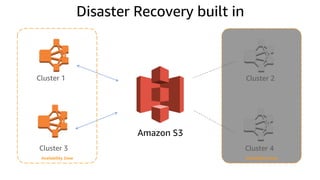



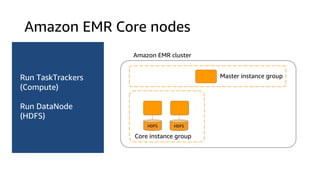
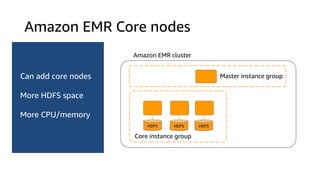
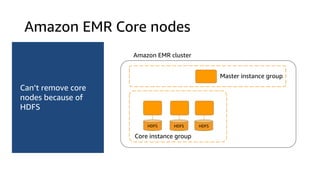
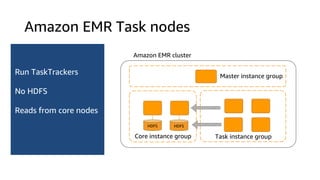
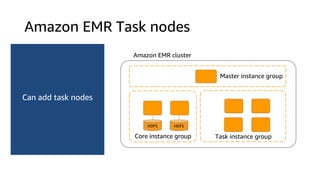
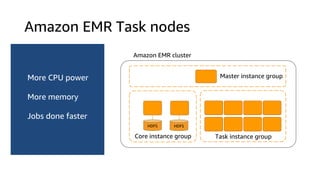
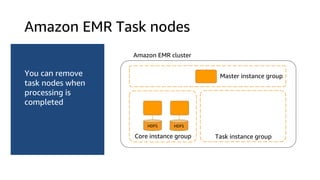


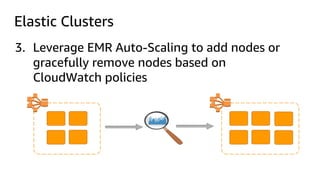
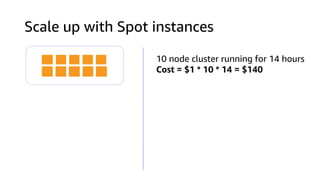

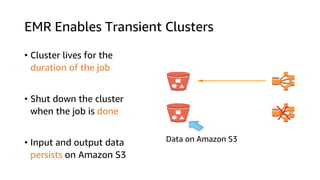
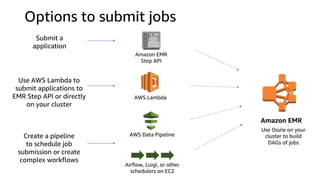

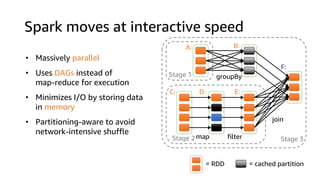
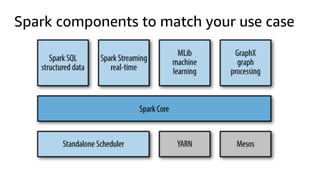

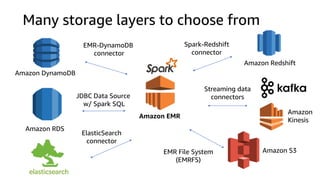

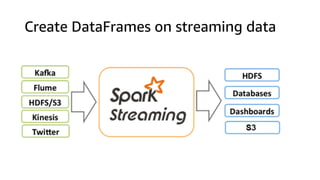
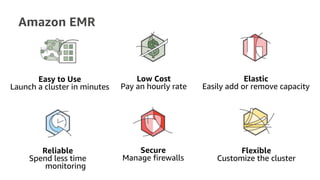



The document provides an overview of Amazon Elastic Map Reduce (EMR), highlighting its features like the use of Amazon S3 as a permanent data store, the advantages of decoupled storage and compute, and the ability to launch clusters quickly and at scale. It explains the functionality of core and task nodes, elastic clusters, and integration with tools like Spark for advanced analytics. Additionally, it emphasizes the benefits of Amazon S3 for data durability and efficient scaling compared to traditional HDFS.



























![[Jun AWS 201] Technical Workshop](https://cdn.slidesharecdn.com/ss_thumbnails/aws201general201tworkshop-130708040331-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







































